
Since the COVID-19 pandemic began, I’ve received several questions about finding census data and boundary files for ZIP Codes (aka US postal codes), as many states are publishing ZIP Code-level data for cases and deaths. ZIP Codes are commonly used for summarizing address data, as it’s easy to do and most Americans are familiar with them. However, there are a number of challenges associated with using ZIP Codes as a unit of analysis that most people are unaware of (until they start using them). In this post I’ll summarize these challenges and provide some solutions.
The short story is: you can get boundary files and census data from the decennial census and 5-year American Community Survey (ACS) for ZIP Code Tabulation Areas (ZCTAs, pronounced zicktas) which are approximations of ZIP Codes that have delivery areas. Use any census data provider to get ZCTA data: data.census.gov, Census Reporter, Missouri Census Data Center, NHGIS, or proprietary library databases like PolicyMap or the Social Explorer. The longer story: if you’re trying to associate ZIP Code-level data with census ZCTA boundary files or demographic data, there are caveats. I’ll cover the following issues in detail:
- ZIP Codes are actually not areas with defined boundaries, and there are no official USPS ZIP Code maps. Areas must be derived using address files. The Census Bureau has done this in creating ZIP Code Tabulation Areas (ZCTAs).
- The Census Bureau publishes population data by ZCTA and boundary files for them. But ZCTAs are not strictly analogous with ZIP Codes; there isn’t a ZCTA for every ZIP Code, and if you try to associate ZIP data with them some of your records won’t match. You need to crosswalk your ZIP Code data to the ZCTA-level to prevent this.
- ZCTAs do not nest or fit within any other census geographies, and the postal city name associated with a ZIP Code does not correlate with actual legal or municipal areas. This can make selecting and downloading ZIP Code data for a given area difficult.
- ZIP Codes were designed for delivering mail, not for studying populations. They vary tremendously in size, shape, and population.
- Analyzing data at either the ZIP Code or ZCTA level over time is difficult to impossible.
- ZIP Code and ZCTA numbers must be saved as text in data files, and not as numbers. Otherwise codes that have leading zeros get truncated, and the code becomes incorrect.
ZIP Codes versus ZCTAs and Boundaries
Contrary to popular belief, ZIP Codes are not areas and the US Postal Service does not delineate boundaries for them. They are simply numbers assigned to ranges of addresses along street segments, and the codes are associated with a specific post office. When we see ZIP Code boundaries (on Google Maps for example), these have been derived by creating areas where most addresses share the same ZIP Code.
The US Census Bureau creates areal approximations for ZIP Codes called ZIP Code Tabulation Areas or ZCTAs. The Bureau assigns census blocks to a ZIP number based on the ZIP that’s used by a majority of the addresses within each block, and aggregates blocks that share the same ZIP to form a ZCTA. After this initial assignment, they make some modifications to aggregate or eliminate orphaned blocks that share the same ZIP number but are not contiguous. ZCTAs are delineated once every ten years in conjunction with the decennial census, and data from the decennial census and the 5-year American Community Survey (ACS) are published at the ZCTA-level. You can download ZCTA boundaries from the TIGER / Line Shapefiles page, and there is also a generalized cartographic boundary file for them.
Crosswalking ZIP Code Data to ZCTAs
There isn’t a ZCTA for every ZIP Code. Some ZIP Codes represent large clusters of Post Office boxes or are assigned to large organizations that process lots of mail. As census blocks are aggregated into ZCTAs based on the predominate ZIP Code for addresses within the block, these non-areal ZIPs fall out of the equation and we’re left with ZCTAs that approximate ZIP Codes for delivery areas.
As a result, if you’re trying to match either your own summarized address data or sources that use ZIP Codes as the summary level (such as the Census Bureau’s Business Patterns and Economic Census datasets), some ZIP Codes will not have a matching ZCTA and will fall out of your dataset.
To prevent this from happening, you can aggregate your ZIP Code data to ZCTAs prior to joining it to boundary files or other datasets. The UDS Mapper project publishes a ZIP Code to ZCTA Crosswalk file that lists every ZIP Code and the ZCTA it is associated with. For the ZIP Codes that don’t have a corresponding area (the PO Box clusters and large organizations), these essentially represent points that fall within ZCTA polygons. Join your ZIP-level data to the ZIP Code ID in the crosswalk file, and then group or summarize the data using the ZCTA number in the crosswalk. Then you can match this ZCTA-summarized data to boundaries or census demographic data at the ZCTA-level.

UDS ZIP Code to ZCTA Crosswalk. ZIP Code 99501 is an areal ZIP Code with a corresponding ZCTA number, 99501. ZIP Code 99520 is a post office or large volume customer that falls inside ZCTA 99501, and thus is assigned to that ZCTA.
Identifying ZIPs and ZCTAs within Other Areas
ZCTAs are built from census blocks and nest within the United States; they do not fit within any other geographies like cities and towns, counties, or even states. The boundaries of a ZCTA will often cross these other boundaries, so for example a ZCTA may fall within two or three different counties. This makes it challenging to select and download census data for all ZCTAs in a given area.
You can get lists of ZIP Codes for places, for example by using the MCDC’s ZIP Code Lookup. The problem is, the postal city that appears in addresses and is affiliated with a ZIP Code does not correspond with cities as actual legal entities, so you can’t count on the name to select all ZIPs within a specific place. For example, my hometown of Claymont, Delaware has its own ZIP Code, even though Claymont is not an incorporated city with formal, legal boundaries. Most of the ZIP Codes around Claymont are affiliated with Wilmington as a place, even though they largely cover suburbs outside the City of Wilmington; the four ZIP Codes that do cover the city cross the city boundary and include outside areas. In short, if you select all the ZIP Codes that have Wilmington, DE as their place name, they actually cover an area that’s much larger than the City of Wilmington. The Census Bureau does not associate ZCTAs with place names.

Lack of correspondence between postal city names and actual city boundaries. Most ZCTAs with the prefix 198 are assigned to Wilmington as a place name, even though many are partially or fully outside the city.
So how can you determine which ZIP Codes fall within a certain area? Or how they do (or don’t) intersect with other areas? You can overlay and eyeball the areas in TIGERweb to get a quick idea. For something more detailed, here are three options:
- The Missouri Census Data Center’s Geocorr application lets you calculate overlap between a source geography and a target geography using either total population or land area for any census geographies. So in a given state, if you select ZCTAs as a source, and counties as the target, you’ll get a list that displays every ZCTA that falls wholly or partially within each county. An allocation factor indicates the percentage of the ZCTA (population or land) that’s inside and outside a county, and you can make decisions as to whether to include a given ZCTA in your study area or not. If a ZCTA falls wholly inside one county, there will be only one record with an allocation factor of 1. If it intersects more than one county, there will be a record with an allocation factor for each county.
- The US Department of Housing and Urban Development (HUD) publishes a series of ZIP Code crosswalk files that associates ZIP Codes with census tracts, counties, CBSAs (metropolitan areas), and congressional districts. They create these files by geocoding all addresses and calculating the ratio of residential, business, and other addresses that fall within each of these areas and that share the same ZIP Code. The files are updated quarterly. You can use them to select, assign, or apportion ZIP Codes to a given area. There’s a journal article that describes this resource in detail.
- Some websites allow you to select all ZCTAs that fall within a given geography when downloading data, essentially by selecting all ZCTAs that are fully or partially within the area. The Census Reporter allows you to do this: search for a profile for an area, click on a table of interest, and then subdivide the areas by smaller areas. You can even look at a map to see what’s been selected. data.census.gov currently does not provide this option; you have to select ZCTAs one by one (or if you’re using the census API, you’ll need to create a list of ZCTAs to retrieve).

Sample output from MCDC Geocorr. ZCTAs 08251 and 08260 fall completely within Cape May County, NJ. ZCTA 08270’s population is split between Cape May (92.4%) and Atlantic (7.6%) counties. The ZCTA names are actually postal place names; these ZCTAs cover areas that are larger than these places.
Do You Really Need to Use ZIP Codes?
ZIP Codes were an excellent mid-20th century solution for efficiently processing and delivering mail that continues to be useful for that purpose. They are less ideal for studying populations or other forms of human activity. They vary tremendously in size, shape, and population which makes them inconsistent as a unit of analysis. They have no legal or administrative meaning or function, other than delivering mail. While all American’s are familiar with them, they do not have any relevant social meaning. They don’t represent neighborhoods, and when you ask someone where they’re from, they won’t say “19703”.
So what are your other options?
- If you don’t have to use ZIP Code or ZCTA data for your project, don’t. For the United States as a whole, consider using counties, PUMAs, or metropolitan areas. Within states: counties, PUMAs, and county subdivisions. For smaller areas: municipalities, census tracts, or aggregates of census tracts.
- If you have the raw, address-based data, consider geocoding it. Once you geocode an address, you can use GIS to assign it to any type of geography that you have a boundary file for (spatial join), and then you can aggregate it to that geography. Some geocoders even provide geographies like counties or tracts in the match result. If your data is sensitive, strip all the attributes out except for the address and a serial integer to use as an ID, and after geocoding you can associate the results back to your original data using that ID. The Census Geocoder is free, requires no log in, allows you to do batches of 1,000 addresses at a time, and forces you to use these safety precautions. For bigger jobs, there’s an API.
- Sometimes you’ll have no choice and must use ZIP Code / ZCTA data, if what you’re interested in studying is only provided in that summary form, or if there are privacy concerns around geocoding the raw address data. You may want to modify the ZCTA geography for your area to aggregate smaller ZCTAs into larger ones surrounding them, for both visual display and statistical analysis. For example, in New York City there are several ZCTAs that cover only one city and census block, as they’re occupied by one large office building that processes a lot of mail (and thus have their own ZIP number). Also, unlike most census geographies, ZCTAs have large holes in them. Any area that does not have streets and thus no addresses isn’t included in a ZCTA. In urban areas, this means large parks and cemeteries. In rural areas, vast tracts of unpopulated forest, desert, or mountain terrain. And large bodies of water in every place.

One-block ZCTAs in Midtown Manhattan, NYC that have either low or zero population.
Analyzing ZIP Code Data Over Time…
In short – forget it. The Census Bureau introduced ZCTAs in the year 2000, and in 2010 they modified their process for creating them. For a variety of reasons, they’re not strictly compatible. ACS data for ZCTAs wasn’t published until 2013. Even the economic datasets don’t go that far back; the ZIP Code Business Patterns didn’t appear until the early 1990s. Use areas that have more longevity and are relatively stable: counties, census tracts.
Why Do my ZIP Codes Look Wrong in Excel?
Regardless of whether you’re using a spreadsheet, database, or scripting language, always make sure to define ZIP / ZCTA columns as strings or text, and not as numeric types. ZIP Codes and ZCTAs begin with zeros in several states. Columns that contain ZIP / ZCTA codes must be saved as text to preserve the 5-digit code. If they’re saved as numbers, the leading zeros are dropped and the numbers are rendered incorrectly. This often happens if you’re working with data in a CSV file and you click on it to open it in Excel. In parsing the CSV, Excel assumes the ZIP / ZCTA field is a number and saves it as a number, which drops the zero and truncates the code. To prevent this from happening: open Excel to a blank project, go to the Data ribbon, click the button to import text data, choose delimited text on the import screen, choose the delimiter (comma or tab, etc), and when prompted you can select the ZIP / ZCTA column and designate it as text so that it imports properly.

To import CSV files in Excel, go to the Data ribbon and under Get External Data select From Text.
Conclusion
That’s all you ever (or maybe never) wanted to know about ZIP Codes and ZCTAs! For more information see the Census Bureau’s page about ZCTAs, a thorough write up by the Missouri Census Data Center, and these informative and fun blog posts from PolicyMap (complete with photos of Mr. ZIP). I wrote an article a few years back that demonstrates how to use some of these resources (the UDS mapper file, Geocorr) to process ZIP data with SQL and python. And of course, check out my book, Exploring the U.S. Census: Your Guide to America’s Data, to explore these concepts and resources in greater detail with hands-on exercises.

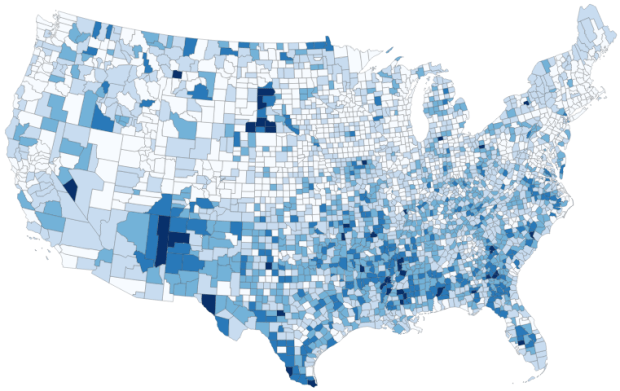
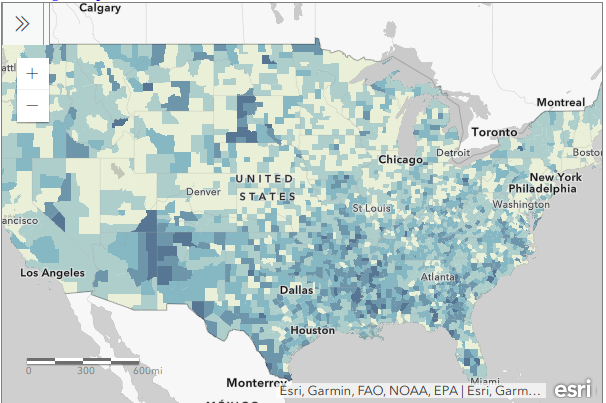


 , and in the vector menu add the CBF shapefile. All census shapefiles are in the basic NAD83 system by default, which is not great for making a thematic map. Go to the Vector Menu – Data Management Tools – Reproject Layer. Hit the little globe beside Target CRS. In the search box type ‘US National’, select the US National Atlas Equal Area option in the results, and hit OK. Lastly, we press the little ellipses button beside the Reprojected box, Save to File, and save the file in a good spot. Hit Run to create the file.
, and in the vector menu add the CBF shapefile. All census shapefiles are in the basic NAD83 system by default, which is not great for making a thematic map. Go to the Vector Menu – Data Management Tools – Reproject Layer. Hit the little globe beside Target CRS. In the search box type ‘US National’, select the US National Atlas Equal Area option in the results, and hit OK. Lastly, we press the little ellipses button beside the Reprojected box, Save to File, and save the file in a good spot. Hit Run to create the file.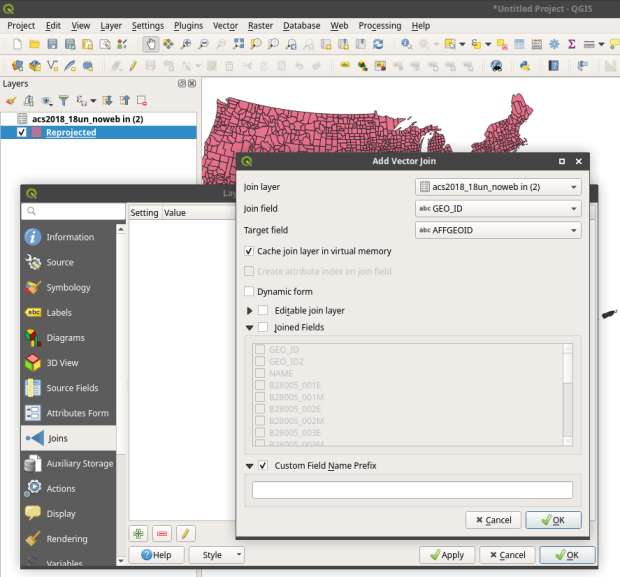







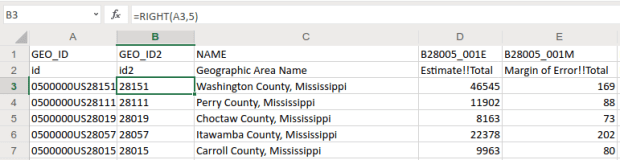
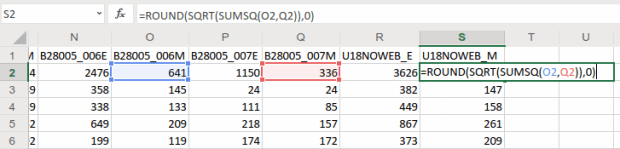
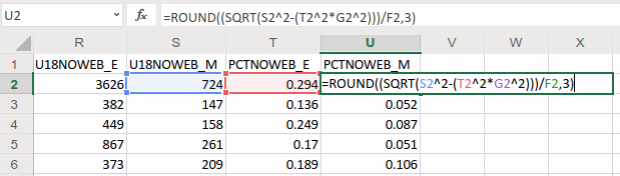
 and creating a grouped summary:
and creating a grouped summary:


You must be logged in to post a comment.