I posted the latest version of my Introduction to GIS with QGIS tutorial manual, updated for QGIS 3.44 Solothurn. The manual and sample data are freely available from my lab’s tutorials page.
This year’s changes are minor, as there weren’t major software updates that would impact the exercises. I updated the sample data as it was growing a bit stale, which necessitated updating screenshots and references in the text. I also updated the source LaTeX code to ensure the PDF meets the new federal WCAG guidelines for digital accessibility. I added a brief troubleshooting section on using QGIS with a Mac to the Introduction, as there have been a creeping number of annoying problems that have thrown my workshops off kilter (MacOS security blocking installation and writing of files to the user’s documents folder, and UI issues with the default color scheme and hiding menus in the background).
It’s hard to believe this is the 16th edition of this manual. When I wrote the first version back in 2011 (it was originally called Introduction to GIS Using Open Source Software), there was relatively little documentation on QGIS. In launching a workshop series and on-going support for it, I felt that I needed to create a basic guidebook. QGIS was far more primitive back then; converting the CRS for a GIS file required a separate command-line program, and you had to calculate natural breaks by hand! QGIS has certainly come a long way since then, and has been widely adopted. I’ve updated my materials as the software has evolved, but overall I’ve stuck to the same plan in terms of content, with modifications to the examples:
Introduction: a general overview of the workbook, goals for the material and workshop, and updates to the manual since the previous version.
An Overview of GIS: a short narrative that describes basic GIS concepts, and open source software.
Exploring the Interface: explanation of the interface, adding vector data and viewing and selecting features, adding raster data, web base maps, and project files.
Geographic Analysis: a cohesive case study that illustrates the process for doing an analysis while showcasing fundamental operations including: tables joins, plotting coordinate data, selecting, filtering, and deleting features, and geoprocessing tools like intersection and buffering. My original case study was locating a new comic book store in NYC, subsequently modified to locating a coffee shop, and more recently identifying public libraries in Rhode Island that met criteria for a grant to host an after school program.
Thematic Mapping: exercise for understanding coordinate reference systems and how they function in QGIS, transforming systems, classifying data, and creating a final map layout. The original example was mapping healthcare sector employment by US state, but eventually switched to voter participation in federal elections.
Data and Educational Resources: strategies and suggestions for finding GIS data, and recommendations for learning more through tutorials and workshops.
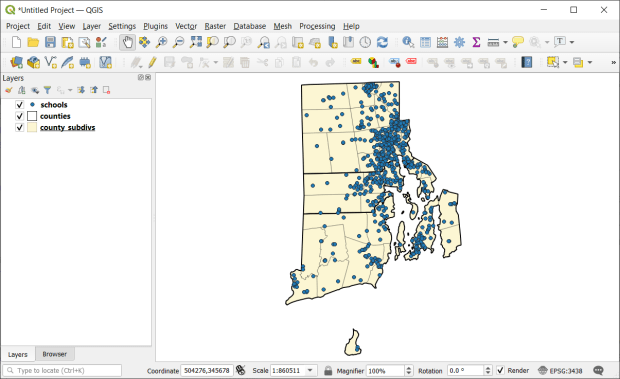
QGIS 3.44 Solothurn interface in Windows 11, used for the 16th edition of the manual in 2026
I’ve always used a follow-the-leader approach in teaching the workshop, where we stay together and the group does the material step by step. Everyone is a little fatigued by the end of the day, so for the thematic mapping piece we pivot to using the workbook; I demo the material and folks work on their own. I primarily wrote the book as a takeaway, so people could refer back to it after the session was over. It was also useful for self-directed learning, and the act of writing and updating it helps me internalize the material.
The last couple of years have been challenging though, and I have been thinking about what I could do differently. There have been a number of articles recently that discuss declining attention spans and students’ diminishing ability to thoughtfully engage with text (for example, in The Economist and The Atlantic). My own experiences bear this out. Increasingly, participants have a hard time following me in the session, and when I have student employees do the tutorial on their own as part of orientation, it takes them much longer and they struggle to finish. I have other workshops where I don’t use the follow-the leader approach, and instead I demo the material and everyone works on their own using the text, and once everyone finishes we move on to the next part. This works no better, as many participants wander away (mentally and physically) from the exercises and struggle to relate the text to what’s on the screen. Now, a good deal of success hinges on having good instructions, but I update them every year, and have used the same system and material in earlier years to good effect.
I have considered creating a more interactive web version of the workbook, or creating videos. The problem with both is that updating them each year would be far more time consuming; in contrast, updating the text and images in the workbook is pretty straightforward. I had one colleague suggest that my “old school” workbook fills an important niche in terms of structure and format, and is useful “as is” for deep learners. A professor I work with, who has had similar experiences in the classroom, expressed that there’s a limit to what an instructor can do; we can only simplify the material so much, and it’s up to students to rise to the occasion.
Reflecting on how I learn, I have gradually moved to videos to learn new material: whether it’s understanding a particular GIS method or tool, mastering a video game, or figuring out how to replace the belt on my clothes drier. Nothing beats a book for getting a comprehensive introduction to a topic, but the videos are helpful for targeted, stand-alone tasks. They can be comprehensive too, if they’re thoughtfully designed as part of a series. I’m definitely going to keep the workbook manual going, but am considering a video version for the future. I’ll wait until the 4.x version of QGIS becomes the new long term release (early next year) before I head in that direction, as the jump from 3.x to 4.x is more likely to come with some interface and functional changes.
The workbook has gotten a lot of miles these past 16 years, and I know others have used it for their own workshops and courses. Feel free to reach out if you have any suggestions.
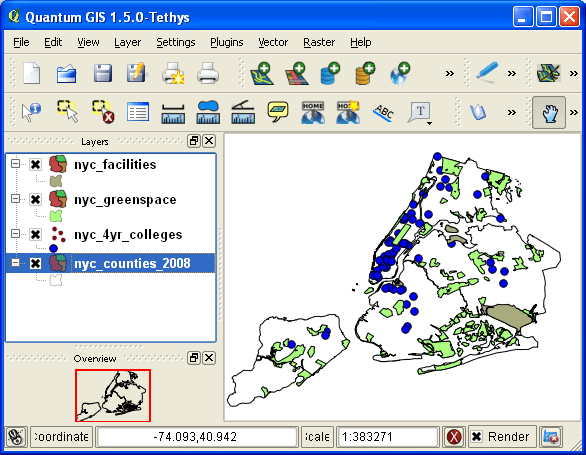
QGIS 1.5 Tethys interface in Windows XP, used for the 1st edition of the manual in 2011
It’s been awhile since I’ve written a post that showcases different GIS datasets. So in this one, I’ll provide an overview of some free and open data sources that I’ve learned about and worked with this past spring semester. The topics in these series include: global land use and land cover, US heat and temperature, detailed population data for India, and public health in low and middle income countries.
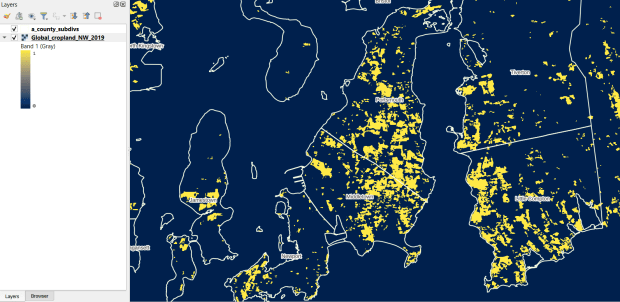
The GLAD lab at the Department of Geographical Sciences at the University of Maryland produces over a dozen GIS datasets related to global land use, land cover, and change in land surface over time. Last semester I had folks who were interested in looking at recent global change in cropland and forest. GLAD publishes rasters that include point-in-time coverage, period averages, and net change and loss over the period 2000 to 2020. Much of the data is generated from LANDSAT, and resolution varies from 30m to 3km. Other series include tropical forest cover and change, tree canopies, forest lost due to fires, a few non-global datasets that focus on specific regions, and LANDSAT imagery that’s been processed so it’s ready for LULC analysis.
Most of the sets have been divided up into tiles and segmented based on what they’re depicting (change in crops, forest, etc). The download process is basic point and click, and for larger sets they provide a list of tifs in a text file so you can automate downloading by writing a basic script. Alternatively, they also publish datasets via Google Earth Engine.
GLAD Cropland Extent in 2019 in QGIS, Zoomed in to Optimal Resolution in SE Rhode Island
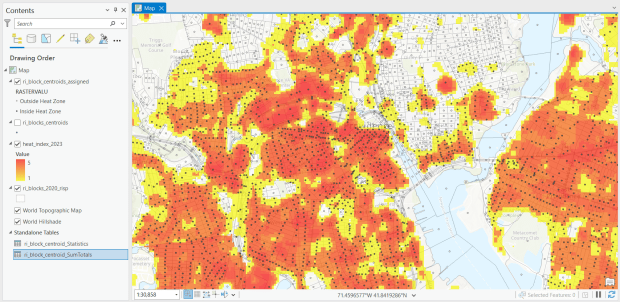
For the past few years, the Trust for Public Land has published an annual heat severity index. This layer represents the relative heat severity for 30m pixels for every city in the United States; depicting where areas of cities are hotter than the average temperature for that same city as a whole (i.e. the surface temperature for each pixel relative to the general air temperature reading for the entire city). Severity is measured on a scale of 1 to 5, with 1 being a relatively mild and 5 being severe heat. The index is generated from a Heat Anomalies raster which they also provide; it contains the relative degrees Fahrenheit difference between any given pixel and the mean heat value for the city in which the pixel is located. Both datasets are generated from 30-meter Landsat 8 imagery, band 10 (ground-level thermal sensor) from summertime images.
The dataset is published as an ArcGIS image service. The easiest way to access it is by to adding it from the Living Atlas to ArcGIS Pro (or Online), and then export the service from there as a raster feature class (while doing so, you can also clip the layer to a smaller area of interest). It’s possible that you can also connect to it as an ArcGIS REST Server in QGIS, but I haven’t tried. While there are files that go back to 2019, the methodology has changed over time, so studying this as a national, annual time series is not appropriate. The coverage area expanded from just large, incorporated cities in earlier years to the entire US in recent years.
US Heat Severity Index 2023 in ArcGIS Pro, Providence and Adjacent Areas with Census Blocks
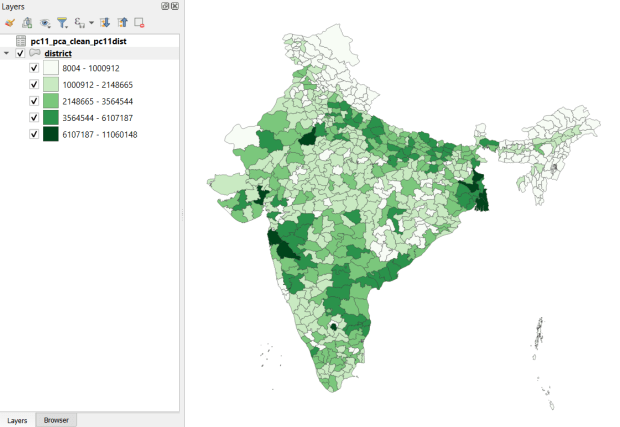
Created and hosted by the Development Data Lab (a collaborative project created by academic researchers from several universities), the Socioeconomic High-resolution Rural-Urban Geographic Platform for India (SHRUG) is an open access repository consisting of datasets for India’s medium to small geographies (districts, subdistricts, constituencies, towns, and villages), linked together with a set of common geographic IDs. Getting geographically detailed census data for India is challenging as you have to purchase it through 3rd party vendors, and comparing data across time is tough given the complex sets of administrative subdivisions and constant revisions to geographic identifiers. SHRUG makes it easy and open source, providing boundaries from the 2011 census and a unique ID that links geographies together and across time, back to 1991. In addition to the census, there are also environmental and election datasets.
Polygon boundaries can be downloaded as shapefiles or geopackages, and tabular data is available in CSV and DTA (STATA) formats. Researchers can also contribute data created from their own research to the repository.
SHRUG India Districts Total Population Data from 2011 Census in QGIS
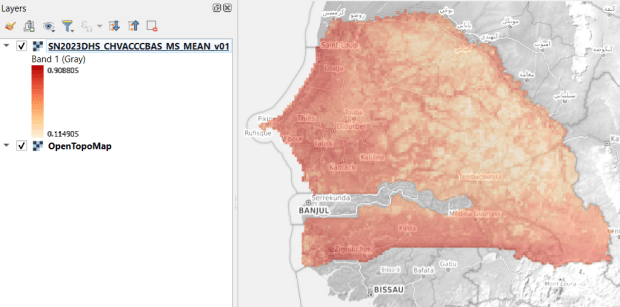
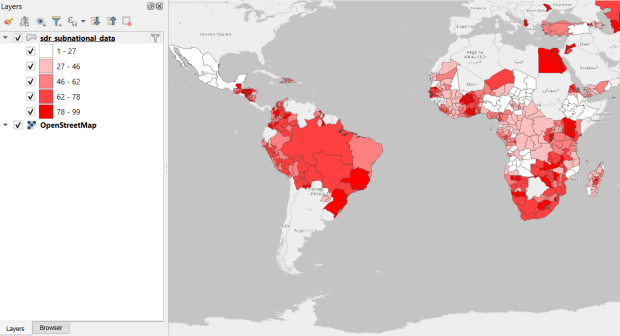
USAID published the detailed Demographic and Health Surveys (DHS) as far back as the mid 1980s for many of the world’s low and middle income countries. The surveys captured information about fertility, family planning, maternal and child health, gender, HIV/AIDS, literacy, malaria, nutrition, and sanitation. A selection of different countries were surveyed each year, and for most countries data was captured at two or three different points in time over a 40 year period. While researchers had to submit proposals and request access to the microdata (individual person and household level responses), the agency generated population-level estimates for countries and country subdivisions that were readily downloadable. They also generated rasters that interpolated certain variables across the surface of a country (the header image for this post is a raster of Senegal in 2023, illustrating the percentage of children aged 12-36 months who are vaccinated for eight fundamental diseases, including measles and polio). The rasters, boundary files, and a selection of survey indicators pre-joined to country and subdivision boundaries were published in their Spatial Data Repository. You could access the full range of population indicators as tables from a point and click website, or alternatively via API.
I’m writing in the past tense, as USAID has been decimated and de-funded by DOGE. There is currently no way to request access to the microdata. The summary data is still available on the USAID website (via links in the previous paragraph), but who knows for how long. As part of the Data Rescue Project, I captured both the Spatial Data Repository and the Indicators data, and posted them on DataLumos, an archive of archived federal government datasets. You can download these datasets in bulk from DataLumos, from the links under the title for this section. Unfortunately this series is now an archive of data that will be frozen in time, with no updates expected. The loss of these surveys is not only detrimental to researchers and policymakers, but to millions of the world’s most vulnerable people, whose health and well-being were secured and improved thanks to the information this data provided.
USAID Country Subdivisions in QGIS where Recent Data is Available on % Children who are Vaccinated
Last month I cobbled together bits and pieces of geospatial Python code I’ve written in various scripts into one cohesive example. You can script, automate, and document a lot of GIS operations with Python, and if you use a combination of Pandas, GeoPandas, and Shapely you don’t even need to have desktop GIS software installed (packages like ArcPy and PyQGIS rely on their underlying base software).
I’ve created a GitHub repository that contains sample data, a basic Python script, and a Jupyter Notebook (same code and examples, in two different formats). The script covers these fundamental operations: reading shapefiles into a geodataframe, reading coordinate data into a dataframe and creating geometry, getting coordinate reference system (CRS) information and transforming the CRS of a geodataframe, generating line geometry from groups and sequences of points, measuring length, spatially joining polygons and points to assign the attributes of one to the other, plotting geodataframes to create a basic map, and exporting geodataframes out as shapefiles.
A Pandas dataframe is a Python structure for tabular data that allows you to store and manipulate data in rows and columns. Like a database, Pandas columns are assigned explicit data types (text, integers, decimals, dates, etc). A GeoPandas geodataframe adds a special geometry column for holding and manipulating coordinate data that’s encoded as point, line, or polygon objects (either single or multi). Similar to a spatial database, the geometry column is referenced with standard coordinate reference system definitions, and there are many different spatial functions that you can apply to the geometry. GeoPandas allows you to work with vector GIS datasets; there are wholly different third-party modules for working with rasters (Rasterio for instance – see this post for examples).
First, you’ll likely have to install the packages Pandas, GeoPandas, and Shapely with pip or your distro’s package handler. Then you can import them. The Shapely package is used for building geometry from other geometry. Matplotlib is used for plotting, but isn’t strictly necessary depending on how detailed you want your plots to be (you could simply use Panda’s own plot library).
import os, pandas as pd
import geopandas as gpd
from shapely.geometry import LineString
import matplotlib.pyplot as plt
%matplotlib inline
Reading a shapefile into a geodataframe is a piece of cake with read_file. We use path.join from the os module to build paths that work in any operating system. Reading in a polygon file of Rhode Island counties:
If you have coordinate data in a CSV file, there’s a two step process where you load the coordinates as numbers into a dataframe, and then convert the dataframe and coordinates into a geodataframe with actual point geometry. Pandas / GeoPandas makes assumptions about the column types when you read a CSV, but you have the option to explicitly define them. In this example I define the Census Bureau’s IDs as strings to avoid dropping leading zeros (an annoying and perennial problem). The points_from_xy function takes the longitude and latitude (in that order!) and creates the points; you also have to define what system the coordinates are presently in. This sample data came from the US Census Bureau, so they’re in NAD 83 (EPSG 4269) which is what most federal agencies use. For other modern coordinate data, WGS 84 (EPSG 4326) is usually a safe bet. GeoPandas relies on the EPSG / ESRI CRS library, and familiarity with these codes is a must for working with spatial data.
In the output below, you can see the distinction between the coordinates, stored separately in two numeric columns, and point-based geometry in the geometry column. The sample data consists of eleven point locations, ten in Rhode Island and one in Connecticut, labeled alfa through kilo. Each point is assigned to a group labeled a, b, or c.
You can obtain the CRS metadata for a geodataframe with this simple command:
gdf_cnty.crs
You can also get the bounding box for the geometry:
gdf_cnty.total_bounds
These commands are helpful for determining whether different geodataframes share the same CRS. If they don’t, you can transform the CRS of one to match the other. The geometry in the frames must share the same CRS if you want to interact with the data. In this example, we transform our points from NAD 83 to the RI State Plane zone that the counties are in with to_crs; the EPSG code is 3438.
gdf_pnts.to_crs(3438,inplace=True)
gdf_pnts.crs
If our points represent a sequence of events, we can do a points to lines operation to create paths. In this example our points are ordered in the correct sequence; if this was not the case, we’d sort the frame on a sequence column first. If there are different events or individuals in the table that have an identifying field, we use this as the group field to create distinct lines. We use lambda to repeat Shapely’s LineString function across the points to build the lines, and then assign them to a new geodataframe. Then we add a column where we compute the length of the lines; this RI CRS uses feet for units, so we divide by 5,280 feet to get miles. The Panda’s loc function grabs all the rows and a subset of the columns to display them on the screen (we could save them to a new geodataframe if we wanted to subset rows or columns).
To assign every point the attributes of the polygon (county) that it intersects with , we do a spatial join with the sjoin function. Here we take all attributes from the points frame, and a select number of columns from the polygon frame; we have to take the geometry from both frames to do the join. In this example we do a left join, keeping all the points on the left regardless of whether they have a matching polygon on the right. There’s one point that falls oustide of RI, so it will be assigned null values on the right. We rename a few of the columns, and use loc again to display a subset of them to the screen.
To see what’s going on, we can generate a basic plot to display the polygons, points, and lines. I used matplotlib to create a figure and axes, and then placed each layer one on top of the other. We could opt to simply use Pandas / GeoPandas internal plotting instead as illustrated in this tutorial, which works for basic plots. If we want more flexibility or need additional functions we can call on matplotlib. In this example the default placement for the tick marks (coordinates in the state plane system) was bad, and the only way I could fix them was by rotating the labels, which required matplotlib.
Exporting the results out a shapefiles is also pretty straightforward with to_file. Shapefiles come with many limitations, such as a limit on ten characters for column names. You can opt to export to a variety of other vector formats, such a geopackages or geoJSON.
Let’s say you have different sets of points, and each set represents a distinct category of features. Maybe villages where residents speak different languages, or historical events that occurred during different epochs. Beyond plotting and symbolizing the points, perhaps you would like to create areas for each set that represent generalized territory, and you’d like to see how these areas correspond. I’ll demonstrate a few approaches for achieving this, using convex hulls, attribute table calculations, and geoprocessing tools like intersection and union. A convex hull is a minimum bounding polygon, where an area is drawn around all points in a set, where the outermost points serve as vertices for creating boundaries.
I’ll use QGIS for this example, but will mention the corresponding tools in ArcGIS Pro at the end. In QGIS we’ll use the tools that are located within the Processing Toolbox (gear icon on the toolbar). Unlike the shortcut tools under the Vector menu, these tools provide more options and allow us to process multiple files at once.
Steps in QGIS
First, we need either distinct point files for each set of features, or a single file with a categorical variable that distinctly identifies different sets of features. For this example I’ll use three distinct files that I’ve generated using phony sample data. The points are in a projected coordinate system (important!) that’s appropriate for the area I’m mapping.
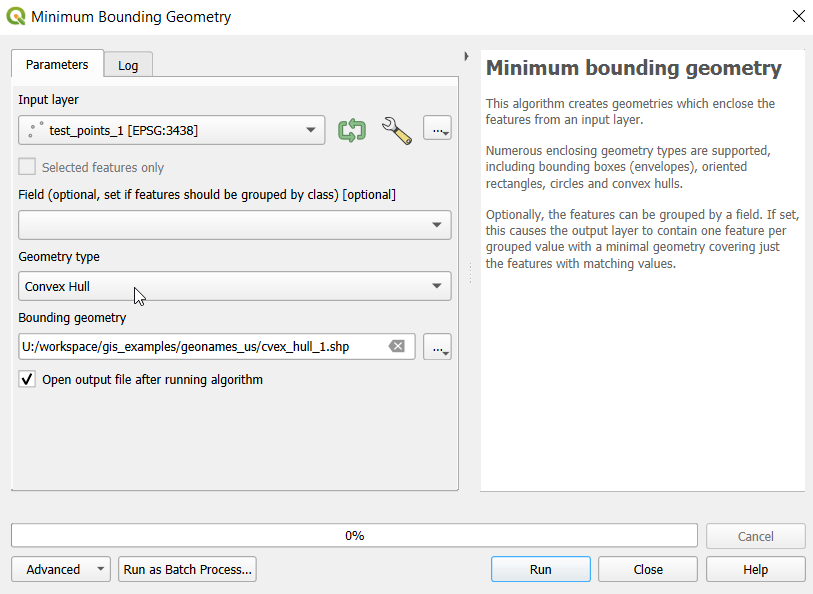
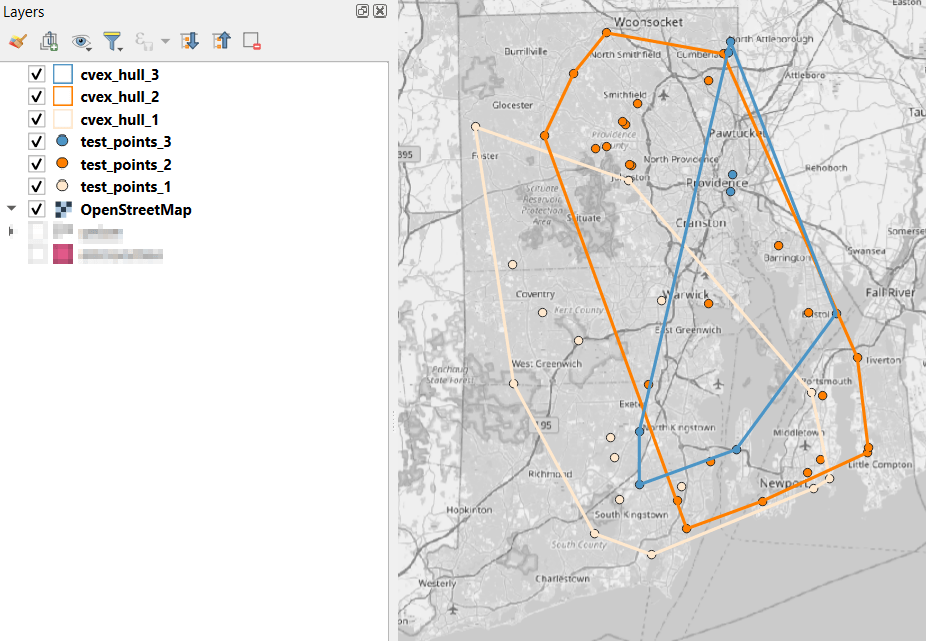
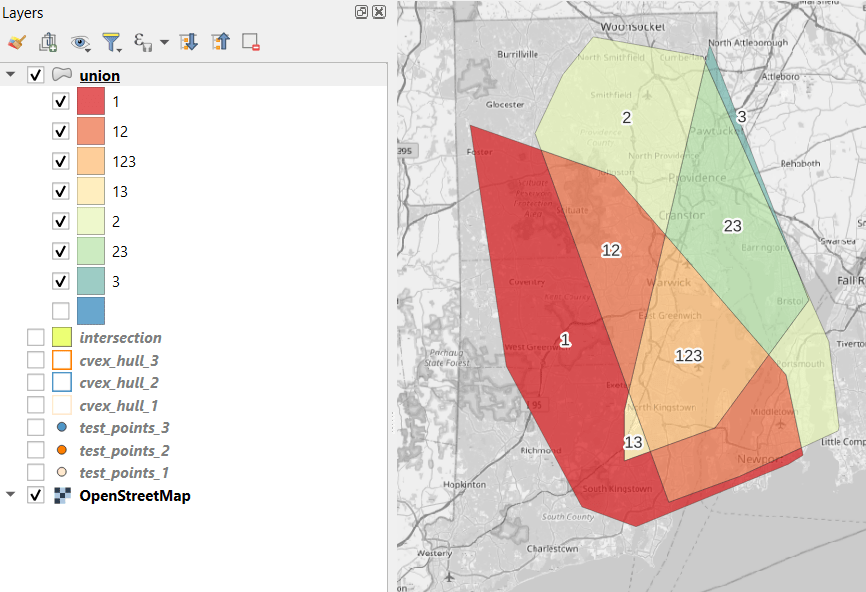
In the QGIS Processing Toolbox, we select the Minimum Bounding Geometry (MBG) tool, and under the Geometry Type specify that we want to create a convex hull. I ran this tool for each file, creating three convex hull files (alternatively, if you had one file with distinct categories, you could use the Field option to generate separate hulls for each category). I’ve symbolized the output below, making the fill hollow and assigning an outline that matches the color of the points. This gives you a good sense for the coverage areas for the points, and how they overlap.
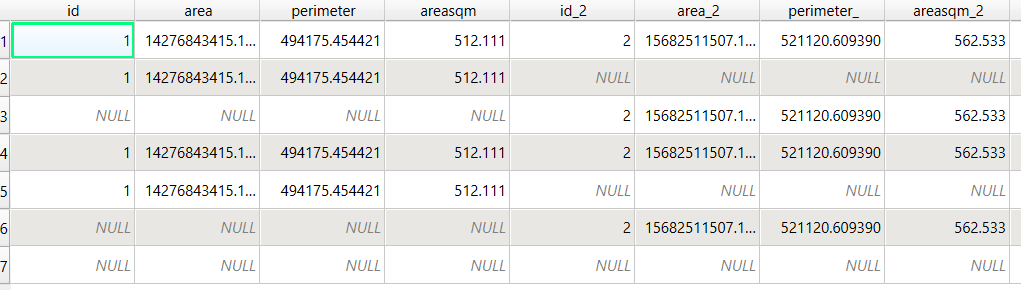
Before running additional tools to explicitly measure overlap, we need to modify the attribute tables of the convex hulls, so we’ll have useful attributes to carry over. The MBG tool creates a new layer with an ID number, area, and perimeter. The ID is set to zero for each hull file, but we should change it to distinctly represent the file / category. With the attribute table open, we can go into an edit mode and type in a new integer value; in this case I’m assigning 1, 2, and 3 to each of the test layers. Alternatively, you could add a new field and assign it a meaningful category value.
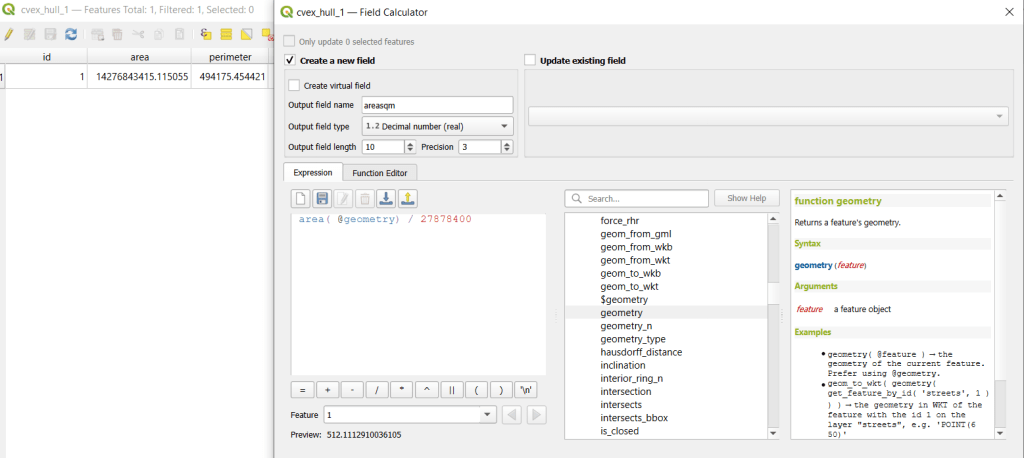
The units for area and perimeter match the units used by the map projection of the layer, which is why we want to use a projected coordinate system that uses meters or feet, and not a geographic one (like WGS 84 or NAD 83) that uses degrees. I’m using a state plane system, so the area is in square feet. To convert this to square miles, within the attribute table view I use the Field Calculator to add a new decimal field, and divide the value of the area by 27,878,400 (the number of sq feet in a sq mile; for metric units in meters, we’d divide by 1,000,000 to get sq km). We calculate the area directly from the polygon geometry:
area( @geometry) / 27878400
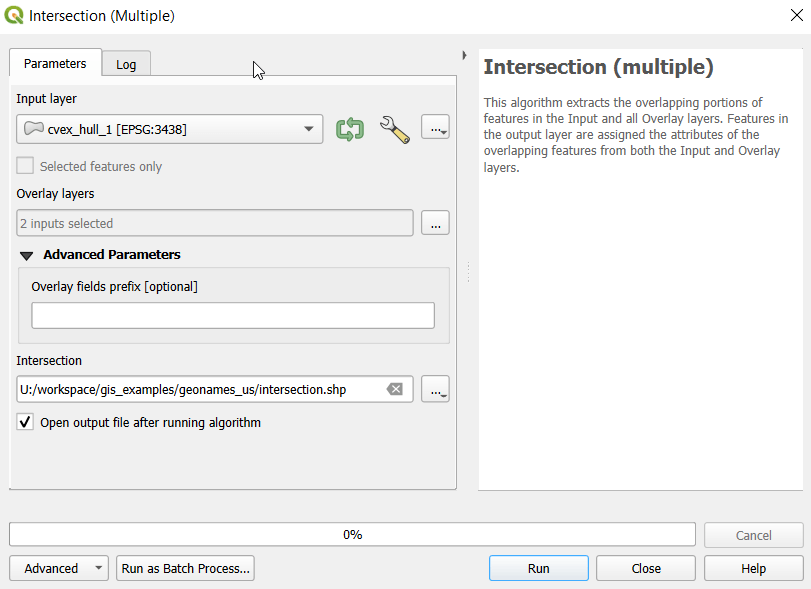
To generate the area of intersection, we go into the Processing tool box and run the Intersection (multiple) tool. The first convex hull is the input layer, while the overlay layers are the other two hull files (in the dialog box, we check the layers we want, and then use the arrow to navigate back to the tool to run it). The output is a new file with polygon(s) that cover the area where all three layers intersect. Its attribute table contains an ID, area, and perimeter field, and we can calculate a new area field in sq miles and see how it compares to the total areas. In my example, the area where all three territories intersect covers about 112 sq miles, while the areas for the individual territories are 512, 563, and 256 sq miles respectively.
To identify distinct areas of overlap between the territories, we return to the Processing toolbox and run the Union (multiple) tool. The dialog is similar to the intersection tool, where the first hull is the union layer and the additional hulls are overlay layers. The output of this tool is a layer with distinct polygons where the hulls coincide. The attribute table for the union layer carries over the attributes from each of the three layers, with columns suffixed with underscores and sequential integers. So if a polygon consists of area covered by hulls 1 and 2, those attributes will be filled in, while the attributes of 3 will be null. As before, we can calculate an area in sq miles for the new polygons. In this case, we’d see that the area covered by hull 1 without any overlapping hulls is 240 sq miles, the largest of all territories.
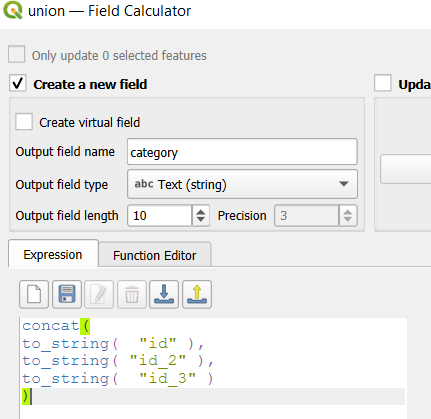
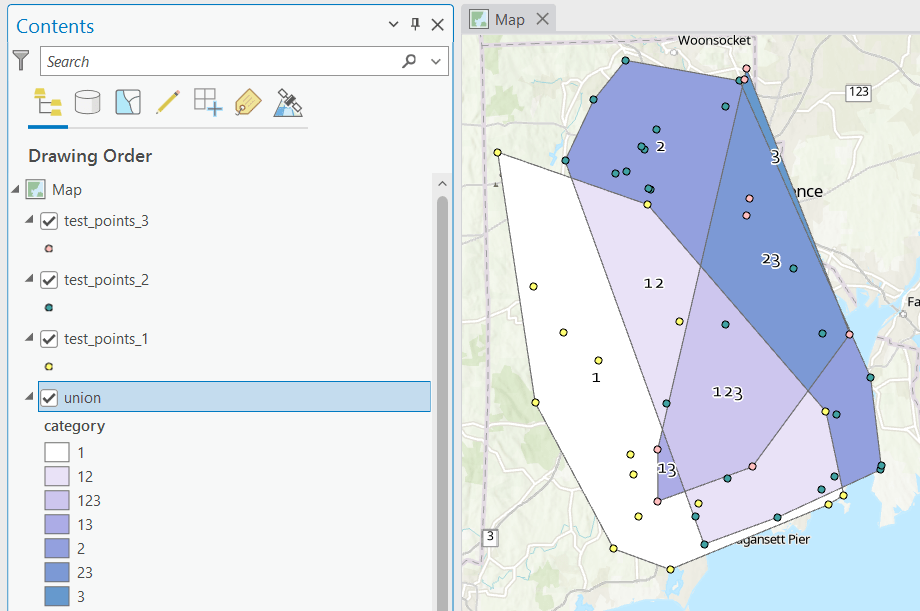
To explicitly categorize these areas, we can add a new field in the attribute table. This will be a text field, where we take the ID numbers, convert them to strings, and concatenate them. In the example above, IDs 1 and 2 would be concatenated to 12, and since the value for 3 is null, no text is appended. (Variation – if you created distinct text-based category fields instead of using the integer IDs, you could concatenate them directly without having to convert them to strings). Using the symbology tool, we can classify the data using these new categories, and can modify the color scheme to something appropriate for displaying the contributions from each area. So a polygon with category 1 includes areas covered by the first convex hull and no others, while category 12 includes areas where hulls 1 and 2 overlapped.
With the areas of the individual union pieces, we can compute the percentages of each territory that fall inside and outside various overlapping zones with the field calculator. For example, we can calculate the total area of the union file (which is NOT the sum of each hull, as there’s overlap between them), and then divide each feature by that total to get its percent total. The expression for doing this is below; the numerator has the name of the field that contains the area of each polygon in sq miles, while the denominator includes the calculation for the sum of all parts (alternatively you could use the QGIS Statistics tool to compute this, and hard code the total into the formula):
If the idea is to create areas of territory that the points exert influence on, you may want to add a buffer to each hull, to account for the fact that the outer points that form the boundaries will exert influence on both sides of the boundary. Use the Processing – Buffer tool. For the buffer distance, you can use an arbitrary value that makes sense for the circumstances. Or you can generate a relative value that represents a fraction of each convex hull’s area. The output of the buffer tool would then serve as the input to the intersection and union tools.
These examples focus on area. If the number of points that falls within the areas is important, you can use the Points in Polygon tool on each of the hulls to count points, and then do the same for the output of the intersection and union tools to get the different points counts for each set of polygons.
ArcGIS Pro Corollaries
Following the same steps above for QGIS, but with ArcGIS Pro:
In the red toolbox, the Minimum Boundary Geometry tool is used to create convex halls. It’s quite similar to the one in QGIS: specify the geometry type, and there is an option to Group (if you have one file with categories). If you leave the Add geometry characteristics box unchecked, it will still compute basic area and perimeter; the checkbox adds a bunch of additional fields.
Unlike QGIS, ArcGIS will not allow you to modify its OBJECTID field. To create a unique value for each hull, you will have to open the attribute table and use the Calculate tool to create a category field (integer or text). To ensure that you can carry it over, in ArcGIS you need to give this column a different name in each hull: cat1, cat2, cat3. Set the value at the bottom in the expression box.
You can use the calculate tool in the attribute table to generate an area column in sqft or sqkm, or use the Calculate Geometry Tool in the toolbox instead. The latter is actually simpler: create a new column, and choose Area and the output units.
The Intersect tool will create the intersection, and functions similarly to QGIS.
The Union tool creates the union, and also functions similarly.
Creating the category field in the union file is a bit more complicated, as ArcGIS assigns values of 0 instead of NULL for non-overlapping polygons. In the Calculate window, with the input file as Union and the field as category, change the Expression type to Arcade (ESRI’s scripting language). First, run an expression to concatenate the categories and convert integers to strings (if necessary). Then, replace that expression with a second one that replace the zeros with nothing.
This is a basic approach, appropriate for certain use cases where you want to generate areas from points; particularly when different point sets have a well defined category, so there’s no question of how to group them. Also appropriate where you don’t have – or don’t want – hard boundaries between sets of points and want to see areas of overlap. More sophisticated methods exist for separating points into clusters based on density, distance, and similar attributes, such as K-Means and DB Scan. You can generate non-overlapping territories for individual points using Thiessen / Voronoi polygons, and for points with a sufficiently high density, you can generate rasters with kernel tools.
In this post I’ll demonstrate how to create least cost paths using QGIS and GRASS GIS, and in doing so will describe how a cost surface is constructed. In a surface analysis, you model movement across a grid whose values represent friction encountered in moving across it. In computing a least cost path, you’re seeking an optimal route from an origin to the closest destination, where ‘close’ incorporates distance and ease of movement across that surface. These kinds of analyses are often conducted in the environmental sciences, in modeling the movement of water across terrain, and in zoology in predicting migration paths for land-based animals.
In this example the idea was to chart the origin of settlements and possible trade routes in ancient history. In applications where we’re studying human activity, network analysis is typically used instead. Networks use geometry, where a node is a place or person, and connections between nodes are indicated with lines. Lines typically have a value associated with them that identify either the strength of a connection, or conversely friction associated with moving between nodes. The idea for this project was to identify how networks formed, so the surface analysis served as a proto-network analysis. While there were roads and maritime routes in pre-modern times, these networks were weaker and less dense. Charting movement over a surface representing terrain could provide a decent approximation of routes (but if you’re interested in ancient Roman network routing, check out the ORBIS project at Stanford).
This example stems from a project I was helping a PhD student with; I don’t want to replicate his specific study, so I’ve modified the data sources and area of focus to model movement between large settlements and stone quarries in the ancient Roman world. My goal is to demonstrate the methods with a plausible example; if we were doing this as part of an actual study, we would need to be more discriminating in selecting and processing our data.
Preliminary Work
The Pleiades project will serve as our source for destinations; it’s an academic gazetteer that includes locations and place names for the ancient and early medieval world, stretching from Europe and North Africa through the Middle East to India. It’s published in many forms, and I’ve downloaded the Pleiades Data for GIS in a CSV format. Using QGIS, I used the Add Delimited Text tool to plot the places.csv to get all of the locations, and joined that file to the places_place_type.csv file which contains different categories of places. I used Select by Attributes to get locations classified as quarries, and exported the selection out to a geopackage.
The Pleiades data includes a category for settlements, but there are about ten thousand of these and there isn’t an easy way to create a subset of the largest places. So I opted to use Hanson’s dataset of the largest settlements in the ancient Roman world to serve as our source for origins (about 1,400 places). This data was packaged in an Excel file; I plotted the coordinates using the Create Points Layer from Table tool in QGIS and converted the result to a geopackage. For testing purposes, I selected a subset of ten major cities and saved them in a separate layer: Athenae, Alexandria (Aegyptus), Antiochia (Syria), Byzantium, Carthago, Ephesus, Lugdunum, Ostia, Pergamum, Roma.
For the friction grid, I downloaded a geoTIFF of the Human Mobility Index by Ozak. The description from the project:
“The Human Mobility Index (HMI) estimates the potential minimum travel time across the globe (measured in hours) accounting for human biological constraints, as well as geographical and technological factors that determined travel time before the widespread use of steam power.”
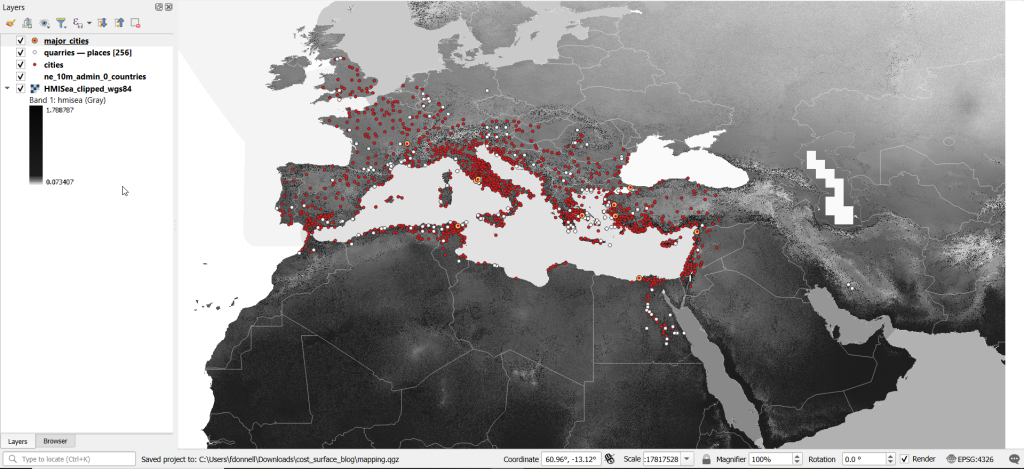
There are three separate grids that vary in extent based on the availability of seafaring technology. I chose the grid that incorporates seafaring prior to the advent of ocean-going ships, which is appropriate for the Mediterranean world during the classical era. The HMI is a global grid at 925 meter resolution. To minimize processing time, I clipped it to a bounding box that encompasses the area of study. The grid is in the World Cylindrical Equal Area system; I reprojected it to WGS 84 to match the rest of the layers. As long as we’re not measuring actual distances, we don’t need to worry about the system we’re using (but if we were, we’d use an equidistant system). Since the range of values is small and it’s hard to see differences in cell values, I symbolized the grid as single-band psuedo color and used a quantiles classification scheme with 12 categories.
Lastly, I grabbed some modern country boundaries from Natural Earth to serve as a general frame of reference. A screenshot of the workspace is below:
Least Cost Path in QGIS
QGIS has a third-party plug-in for doing a least cost path analysis, which works fine as long as you don’t have too many origin points. Go to Plugins > Manage and Install Plugins > Least Cost Path to turn it on. Then open the Processing toolbox and it will be listed at the bottom. See the screenshot below for the tool’s menu. The Cost raster layer is the friction surface, so the human mobility index in this example. The start points are the ten major cities and the end points are the quarries. The start-point layer dialog only accepts a single point; if you have multiple points, hit the green circular arrow button to iterate across all of them. There’s a checkbox for connecting the start point to just the nearest end point (as opposed to all of them). Save the output to a geopackage.
It took about five minutes to run the analysis and iterate across all ten points. Each path is saved in a separate file, but since they have an identical structure I subsequently used Vector > Data Management Tools > Merge Vector Layers to combine them into one file. The attribute table records the end point ID (for the quarry) and the accumulated cost, but does not include the origin ID; this ID is the number 1 repeated each time, as the tool was iterating over the origin points. We can see the result below; for Athens and Ephesus in the south, land routes were shortest, whereas for Pergamum and Byzantium in the north it was easier (distance and friction-wise) to move across the sea.
While this worked fine for ten cities, it would take a considerable amount of time to compute paths for all 1,400. The problem here is that the plugin was designed for one point at a time. Let’s outline the process so we can understand how alternatives would work.
Cost Surface Analysis
To calculate a least cost path, the first step is to create a cost surface, where we take our friction grid and the destinations and calculate the total cost of movement across all cells to the nearest destination. First, the destinations are placed on the grid, and they become the grid sources. Then, the accumulated cost of moving from each source to its adjacent cells is calculated. For horizontal and vertical movement, it’s the sum of the friction values divided by two, and for diagonal movement it’s the sum of the friction values divided by two then multiplied by 1.4142. Once those calculations are performed, those adjacent cells are assigned to each source. Next, the lowest accumulated cost cell in the grid is identified, the cost for moving to its unassigned neighbors is calculated, and these cells are assigned to the same source. This process is repeated by cycling through the lowest accumulated value until all calculations for the grid are finished. Illustrated in the example below, which I derived from Lloyd’s Spatial Data Analysis (2010) pp. 165-168.
For each cell, three items are recorded, and are saved either as separate bands in one raster, or in three separate raster files:
Accumulated cost of moving to that cell from the nearest source
Assignment or allocation of the cell to its source (the nearest one to which it “belongs”)
A vector that indicates direction from that source
With these cost surfaces, we can take the second step of calculating the least cost path. We place a number of starting points onto this surface, and each point is assigned to the closest destination based on where its grid cell was allocated. The direction to that destination is traced backward using the direction grid, and the total cost of movement is taken from the accumulated cost surface.
Knowing how this process works, there are two practical conclusions we can draw. First, when computing the cost surface, you use your destinations (not the origins) as the source for the cost surface. You use the origins as the start points for the least cost path. Second, there’s no need to recalculate the cost surface for every origin point; you only need to do this once. That’s why the QGIS plugin took so long; it was recomputing the cost surface each time. Knowing this, we can use GRASS GIS to compute the paths, as it’s designed to compute the surface just once (and it’s data structure will also boost performance a bit).
Cost Surface Analysis in GRASS
GRASS GIS comes bundled with QGIS. While it’s possible to run a number of GRASS tools directly within QGIS, it’s a bit undesirable as you’re not able to access the full range of parameters or options for each GRASS command. I opted to create the GRASS environment in QGIS, and loaded all the necessary data into the GRASS format. Then, I flipped over to the GRASS GUI to do the analysis.
GRASS uses a distinct database structure and file format, and we need to create a GRASS workspace and load our data into that database in order to use the cost surface tools. I followed the steps in the QGIS manual for creating a GRASS environment and loading data into a GRASS database. Once you create the database and mapset, you use the QGIS Browser to browse to the grassdata folder and designate your new mapset as your working mapset (mapsets have the little green grass icon beside them). With the GRASS tools open, I used v.in.ogr.qgis to load my my cities and quarries layers into this mapset, and r.in.gdal.qgis to load the mobility index (if these layers weren’t already in your QGIS project, you’d use the tools that don’t have the qgis suffix, i.e. v.in.ogr).
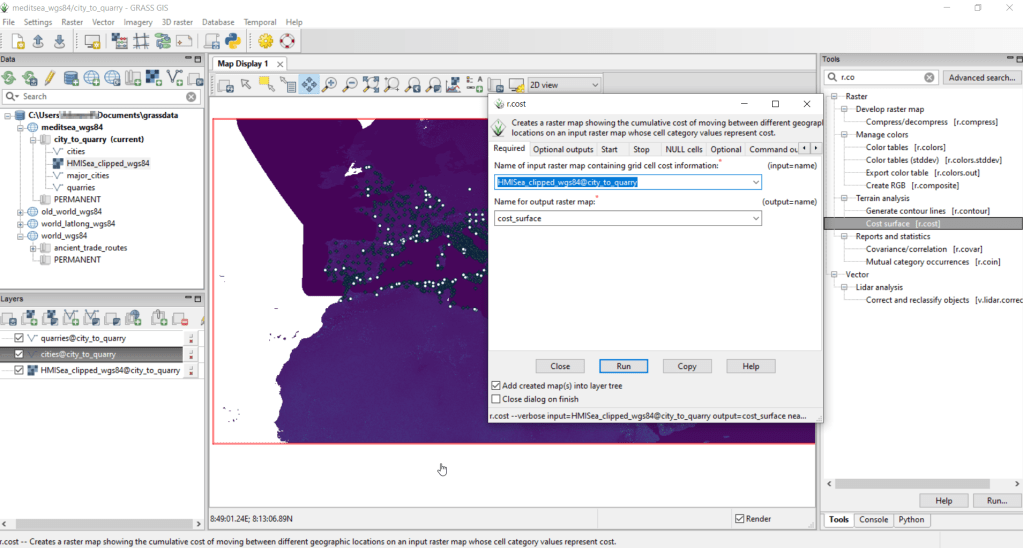
After exiting QGIS and launching GRASS, you select the mapset under the grassdata database at the top, right click and choose Switch mapset, and choose the mapset you want to work with (if you don’t see it, hit the database icon to browse and connect to the grassdata folder). You can display the layers in the GRASS window to visualize them, but it’s not necessary for running the tools. In the tool menu on the right, search for the Cost surface tool, r.cost, and choose the following options:
Required: input raster map with grid cell cost is the human mobility index, and output raster is cost_surface
Optional outputs: output raster with nearest start point as allocation_surface, output raster with movement as direction_surface
Start: vector starting points for the cost surface are the destinations, the quarries
Optional: check verbose output (to get more details on errors)
Running this operation on all 1,400 cities took a matter of seconds, and all three rasters described in the previous section were generated: cost, allocation, direction (shown below).
Using these outputs, we can run the Least cost route or flow tool, which is called r.drain (as it’s often used in earth sciences to chart the path that water will drain based on elevation).
Required: Name of input elevation or cost surface raster is cost_surface, Name of output raster path: is path_raster
Cost surface: check the Input raster map is a cost surface box, Name of input movement direction raster is direction_surface
Start: Name of starting points vector map: are the origins (cities)
Path settings: choose ONE option that you’d like to record (or none)
Optional: check Verbose mode, Name for output drain vector is path_vector
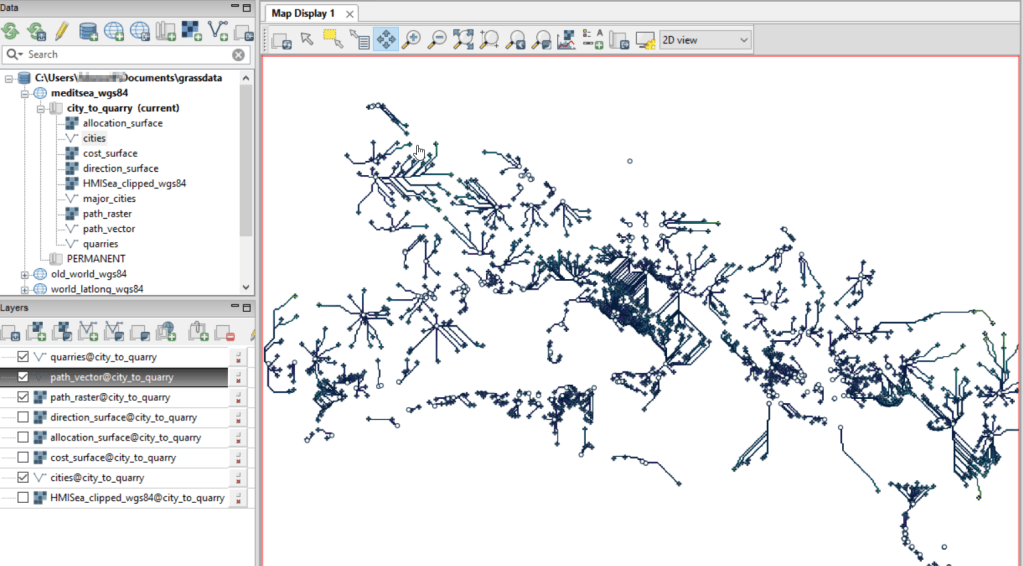
This also took mere seconds to complete (!) and generated the paths from each origin (city) to the closet destination (quarry) over the surface as both raster cells and vector lines. The output in GRASS is shown below.
At this stage, we can hop back into QGIS, and load these output paths into our original project to symbolize and study what’s going on. Notice the settlements in northeastern Italy and along the Dalmatian coast; for many of them the least cost path is to a quarry across the sea rather than through rugged mountainous terrain. Even though some quarries in the mountains may be closer in actual distance, it’s a tougher path to travel.
Conclusion
The benefit of using GRASS is that we can run these processes fairly quickly for large datasets. The GRASS commands can also be compiled into a batch script, so you can create a documented and automated process instead of having to drill through multiple menus.
A big downside of the GRASS tools for this analysis is that the resulting vector paths contain no information about the origin or destination points, and only the raster path output carries along values. You might be able to generate this information through some extra steps; using the QGIS field calculator, you can get the coordinates for the start point and end point of each path and add them explicitly to the attribute table. Then take those coordinates, and for the start point of the line select the closest city and get its attributes, and for the end point select the closet quarry and get its attributes. I say “closest” because the vector paths don’t snap perfectly to the start and end points. Modifying the resolution of the human mobility index to make it coarser (fewer cells) might help to resolve this, or converting the origin and destination points to a raster of the same resolution as the index. Alternatively, if you incorporate the GRASS commands into a Python script, you could iterate over the origins in the least cost path analysis and record the origin IDs as you step through.
I haven’t worked all the pieces, but hopefully this will be useful for those of you who are interested in conducting a basic cost surface analysis in open source. The student I was helping was interested in measuring the density of the paths across a grid, so this process worked for him as he didn’t need to associate the paths with origins and destinations. Beyond FOSS GIS, ArcGIS Pro has a full suite of tools for cost surface analysis, and the underlying methods and logic are the same.
I’ve recently given a few presentations on the Ocean State Spatial Database, which is a basic geodatabase for Rhode Island that we’ve created in our lab. The database was designed so that new and experienced users alike could easily access a curated collection of foundational layers and data tables for thematic mapping and geospatial analysis. The database is available for download on GitHub, and there is documentation that describes the layers and tables that are included. The database comes in two formats: SQLite/ Spatialite that’s great for QGIS, and a File Geoadatabase version for ArcGIS Pro users.
One of the big advantages of using the Spatialite database in QGIS is that you can take advantage of the Database Manager, and write SQL and spatial SQL queries for selecting records and doing spatial analysis. Instead of using a series of point and click tools that create a bunch of new files, you can write a single block of code to perform an entire operation, and you can save that code to document your work. Access the Database Manager above the toolbars at the top of the QGIS interface. Once you’re in, you can select the Spatialite option, right click and then browse your file system to point to the database to establish a connection. At the top of the DB Manager is a button (piece of paper with wrench) to open a SQL query window.
Database Manager in QGIS with SQL Window Open
The following commands are basic SQL: SELECT some columns FROM some tables WHERE some criteria is met. This returns all rows and columns from the public libraries layer in the database:
SELECT * FROM d_public_libraries;
This returns just some of the columns for all rows:
SELECT libid, libname, city, cnty FROM d_public_libraries;
While this returns some of the columns and rows that meet specific criteria, in this case where libraries are located in Providence County, RI:
SELECT libid, libname, city, cnty, geom FROM d_public_libraries WHERE cnty='PROVIDENCE' ORDER BY city;
Traditional database column types include strings (aka text), integers, and decimal numbers, which limit the values that can be stored in the column, and allow specific functions that can operate on values of that type (math on numeric columns, string operations on text columns). Beyond the basic data types, many databases have special ones, such as date types that allow you to store and manipulate dates and times as distinct objects.
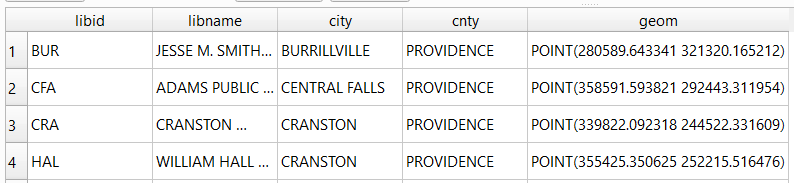
Spatial databases incorporate special columns for storing the geometry of features as strings of coordinates, and provide functions that can operate on that geometry. In the example above, the values stored in the geometry column were returned in a binary format. But we can apply a spatial function called ST_AsText to display the geometry as readable text:
SELECT libid, libname, city, cnty, ST_AsText(geom) AS geom FROM d_public_libraries WHERE cnty='PROVIDENCE' ORDER BY city;
We can see that this is point geometry (as opposed to lines or polygons), and we have an X and Y coordinate for each point. The layers in this database are in the Rhode Island State Plane System, so the coordinates that are returned are in that system. We can convert these to longitude and latitude using the ST_Transform function:
SELECT libid, libname, city, cnty, ST_AsText(ST_Transform(geom,4269)) AS geom FROM d_public_libraries WHERE cnty='PROVIDENCE' ORDER BY city;
This illustrates that the functions can be nested, first we transform the geometry and then display the result of that function as text. The number in the transform function is the unique identifier of the spatial reference system that we wish to transform the geometry to. In the open source world these are EPSG codes, and 4269 is the identifier for NAD 83, the basic long / lat system for North America (alternatively, we could use 4326 for WGS 84, the standard global long / lat system). The geometry column in a spatial table is connected to a series of internal tables that store all the definitions of the spatial reference systems. You can view the spatial reference system table:
SELECT * from spatial_ref_sys;
You can also get a read out of all the spatial tables in the database which include their type of geometry and the spatial reference system (3438 is the EPSG code for the RI State Plane zone, geometry of type 6 is a multipolygon, while type 1 is a point):
SELECT * from geometry_columns;
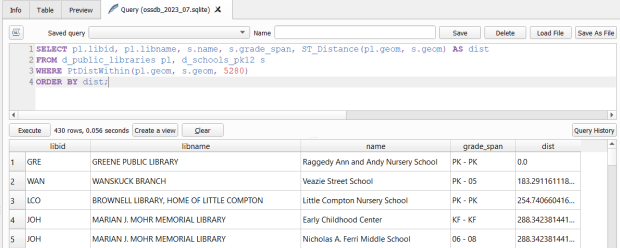
With a spatial database, you perform operations within and between tables by running functions against the geometry columns. For example, to return all public libraries and schools that are within a mile of a library while measuring the distance:
SELECT pl.libid, pl.libname, s.name, s.grade_span, ST_Distance(pl.geom, s.geom) AS dist FROM d_public_libraries pl, d_schools_pk12 s WHERE PtDistWithin(pl.geom, s.geom, 5280) ORDER BY dist;
The ST_Distance function returns the actual distance in a new column, while the PtDistWithin function only returns libraries that have a school within one mile (5,280 feet – we have to express the measurement in the units used by the spatial reference system of both layers). In the FROM statement we provide aliases after each table name, so we can use those as shorthand (if our statement includes multiple tables, we need to indicate which table each column comes from).
You can also do summaries, like you would in standard SQL using GROUP BY. To count the number of schools that are within a mile of every library:
SELECT pl.libid, pl.libname, CAST(COUNT (s.name) AS integer) AS school_count, pl.geom FROM d_public_libraries pl, d_schools_pk12 s WHERE PtDistWithin(pl.geom, s.geom, 5280) GROUP BY pl.libid, pl.libname, pl.geom ORDER BY school_count DESC;
The rule for GROUP BY is that every column in the select statement must be used as a grouping variable, or has an aggregate function applied to it (COUNT, SUM, MEAN, etc). In this example we added the CAST function, which defines the data type for new columns that you create. Unless we explicitly declare it as an integer or real (decimal), values are returned as strings.
You can save your statements as views, by adding CREATE VIEW [view name] AS followed by the statement. Views are saved statements that appear as objects in the database; by opening a view, the statement is rerun and the result is returned. This approach works if you want to save a non-spatial view, i.e. a table without geometry. To save a spatial one with geometry, omit the VIEW statement and hit the Create a view button below the SQL window (each record must have a unique identifier and the geometry column in order for this to work). That registers the geometry column of the view in the database. Then, you can return to the main QGIS window, add the view and symbolize it. Alternatively, there is a Load as new layer button at the bottom of the screen, which allows you to see a temporary result without saving anything (while you can see features and records returned, you won’t be able to symbolize or manipulate the layer).
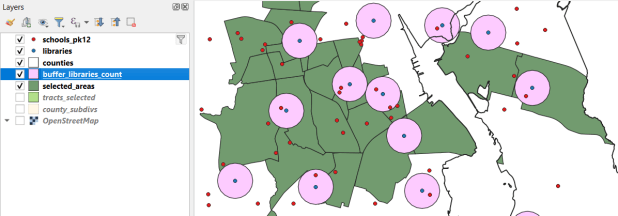
Count schools within 1 mile of libraries, and save as a spatial viewSymbolize the spatial query out in the main QGIS window
One of the primary reasons to use a database is to join related data stored in separate tables. This statement has two joins: a tabular join between the census tracts and an ACS data table, and a spatial join between the geometry of public libraries and tracts:
SELECT pl.libid, pl.libname, a.geoidshort, a.name, c.hshd01_e, c.hshd01_m FROM d_public_libraries pl, a_census_tracts a INNER JOIN c_tracts_acs2021_socecon c ON a.geoidlong=c.geoidlong WHERE ST_Intersects(pl.geom, a.geom);
This returns all public libraries and their intersecting tracts based on the relationship between their two geometries (could also have done ST_Within in this case to get the same result). Spatialite supports most of the spatial relationship functions defined by the OGC. The estimated number of households for these tracts are returned based on the shared unique census identifier between the two census tract tables.
You can visit the following references for a full list of SQLite functions and Spatialite functions. As it’s designed to be “Lite”, SQLite contains a smaller subset of the SQL standard. Spatialite contains a pretty full range of OGC spatial SQL functions, but there are instances where it deviates from the standard. PostgreSQL / PostGIS provides a greater range of functions that adhere more closely to the standard; it also provides you with greater storage, efficiency, and processing power. As a file-based database, SQLite / Spatialite’s strengths are that it’s compact and transportable, and gives you the option to write SQL rather than relying solely on the point and click tools of a desktop GIS package.
In addition to the QGIS DB Manager, you could also use the Spatialite command line tools provided by the developer, and the Spatialite GUI (graphic user interface) that gives you a standard, stand-alone database interface. Downloading it is a bit confusing; Windows users can grab one of the binaries at the bottom of this page. If you’re a Linux person, search for it in your package manager. Mac users can get it via Homebrew.


























You must be logged in to post a comment.