I posted the latest version of my Introduction to GIS with QGIS tutorial manual, updated for QGIS 3.44 Solothurn. The manual and sample data are freely available from my lab’s tutorials page.
This year’s changes are minor, as there weren’t major software updates that would impact the exercises. I updated the sample data as it was growing a bit stale, which necessitated updating screenshots and references in the text. I also updated the source LaTeX code to ensure the PDF meets the new federal WCAG guidelines for digital accessibility. I added a brief troubleshooting section on using QGIS with a Mac to the Introduction, as there have been a creeping number of annoying problems that have thrown my workshops off kilter (MacOS security blocking installation and writing of files to the user’s documents folder, and UI issues with the default color scheme and hiding menus in the background).
It’s hard to believe this is the 16th edition of this manual. When I wrote the first version back in 2011 (it was originally called Introduction to GIS Using Open Source Software), there was relatively little documentation on QGIS. In launching a workshop series and on-going support for it, I felt that I needed to create a basic guidebook. QGIS was far more primitive back then; converting the CRS for a GIS file required a separate command-line program, and you had to calculate natural breaks by hand! QGIS has certainly come a long way since then, and has been widely adopted. I’ve updated my materials as the software has evolved, but overall I’ve stuck to the same plan in terms of content, with modifications to the examples:
Introduction: a general overview of the workbook, goals for the material and workshop, and updates to the manual since the previous version.
An Overview of GIS: a short narrative that describes basic GIS concepts, and open source software.
Exploring the Interface: explanation of the interface, adding vector data and viewing and selecting features, adding raster data, web base maps, and project files.
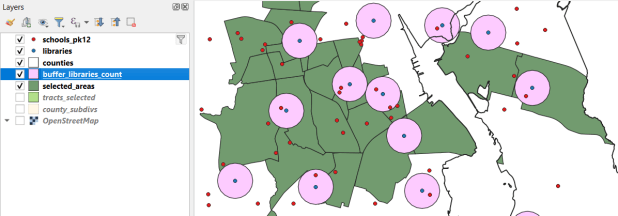
Geographic Analysis: a cohesive case study that illustrates the process for doing an analysis while showcasing fundamental operations including: tables joins, plotting coordinate data, selecting, filtering, and deleting features, and geoprocessing tools like intersection and buffering. My original case study was locating a new comic book store in NYC, subsequently modified to locating a coffee shop, and more recently identifying public libraries in Rhode Island that met criteria for a grant to host an after school program.
Thematic Mapping: exercise for understanding coordinate reference systems and how they function in QGIS, transforming systems, classifying data, and creating a final map layout. The original example was mapping healthcare sector employment by US state, but eventually switched to voter participation in federal elections.
Data and Educational Resources: strategies and suggestions for finding GIS data, and recommendations for learning more through tutorials and workshops.
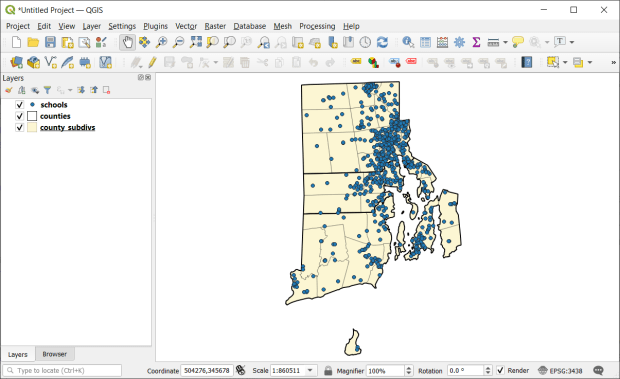
QGIS 3.44 Solothurn interface in Windows 11, used for the 16th edition of the manual in 2026
I’ve always used a follow-the-leader approach in teaching the workshop, where we stay together and the group does the material step by step. Everyone is a little fatigued by the end of the day, so for the thematic mapping piece we pivot to using the workbook; I demo the material and folks work on their own. I primarily wrote the book as a takeaway, so people could refer back to it after the session was over. It was also useful for self-directed learning, and the act of writing and updating it helps me internalize the material.
The last couple of years have been challenging though, and I have been thinking about what I could do differently. There have been a number of articles recently that discuss declining attention spans and students’ diminishing ability to thoughtfully engage with text (for example, in The Economist and The Atlantic). My own experiences bear this out. Increasingly, participants have a hard time following me in the session, and when I have student employees do the tutorial on their own as part of orientation, it takes them much longer and they struggle to finish. I have other workshops where I don’t use the follow-the leader approach, and instead I demo the material and everyone works on their own using the text, and once everyone finishes we move on to the next part. This works no better, as many participants wander away (mentally and physically) from the exercises and struggle to relate the text to what’s on the screen. Now, a good deal of success hinges on having good instructions, but I update them every year, and have used the same system and material in earlier years to good effect.
I have considered creating a more interactive web version of the workbook, or creating videos. The problem with both is that updating them each year would be far more time consuming; in contrast, updating the text and images in the workbook is pretty straightforward. I had one colleague suggest that my “old school” workbook fills an important niche in terms of structure and format, and is useful “as is” for deep learners. A professor I work with, who has had similar experiences in the classroom, expressed that there’s a limit to what an instructor can do; we can only simplify the material so much, and it’s up to students to rise to the occasion.
Reflecting on how I learn, I have gradually moved to videos to learn new material: whether it’s understanding a particular GIS method or tool, mastering a video game, or figuring out how to replace the belt on my clothes drier. Nothing beats a book for getting a comprehensive introduction to a topic, but the videos are helpful for targeted, stand-alone tasks. They can be comprehensive too, if they’re thoughtfully designed as part of a series. I’m definitely going to keep the workbook manual going, but am considering a video version for the future. I’ll wait until the 4.x version of QGIS becomes the new long term release (early next year) before I head in that direction, as the jump from 3.x to 4.x is more likely to come with some interface and functional changes.
The workbook has gotten a lot of miles these past 16 years, and I know others have used it for their own workshops and courses. Feel free to reach out if you have any suggestions.
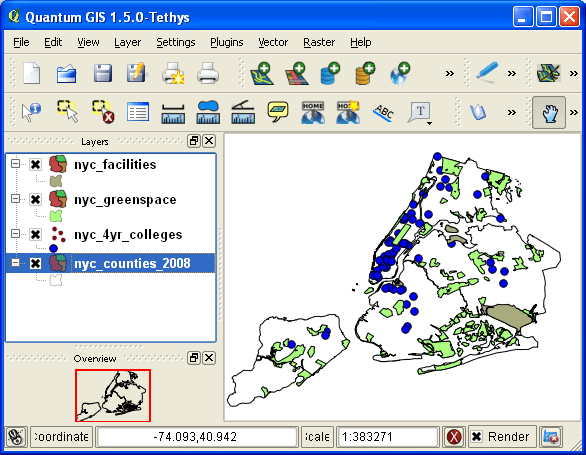
QGIS 1.5 Tethys interface in Windows XP, used for the 1st edition of the manual in 2011
I presented a poster last April on the library’s GIS and Data Services at the CHAIRS-C conference at the Brown School of Public Health. CHAIRS-C is an acronym for Center on Heat, Health, and Aging Innovation and Research Solutions for Communities; it’s a small cluster whose members are interested in heat-related research, and the impact of extreme heat on vulnerable communities. I provided some examples in the poster of heat-related datasets and research that I’ve supported over the last few years. I thought I’d share a summary of these datasets in this post that include air conditioning, heat indices, and sources that provide climate-related rasters with variable that include temperature and precipitation. Most of these examples are US-based, the last one is global.
Local Air Conditioning Estimates (LACE)
The Local Air Conditioning Estimates (LACE) is a new, experimental dataset produced by the US Census Bureau. It includes estimates of occupied housing units that have air conditioning at the national, state, county, and census tract levels. The estimates are published with margins of error at a 90% confidence level, and represent the year 2023. Each record includes the census summary level / fips GEOID, so you can readily match them to vector boundary files for GIS mapping.
Sample records from the Local Air Conditioning Estimates for census tracts
Questions about air conditioning are regularly collected as part of the American Housing Survey (AHS), but the sample size isn’t large enough to publish reliable estimates below the state and metropolitan area levels. To create LACE, the Census Bureau employed machine learning in a process called cross survey modeling, and triangulated the AHS with some other datasets to create small-area estimates. Summary documentation is included on the LACE website if you want to learn more, and there are links to working papers that go into greater detail.
The concept is similar to what the CDC has done in taking data from the Behavioral Risk Factor Surveillance System and using models to create small area estimates for the PLACES project. LACE fills a vital data gap for studying heat; most small-area sources for AC are a patchwork series of parcel data published by individual municipalities. I attended a couple of presentations given by the Census Bureau at FedGeoDay back in April, and they suggested that they will increasingly move in a modeling direction that draws on administrative data and smaller surveys, given declining response rates to large sample surveys like the ACS. Of course, this was before the current administration made the bonkers decision to ban the use of injecting noise into statistical datasets (a basic practice for protecting the privacy of survey participants), so who knows what will happen next.
Urban Heat Severity Index
Research has shown that temperature varies considerably over small areas, especially in cities. So if you are looking at the temperature reported for an entire city, or even at gridded data where the cells are large, both will mask a good deal of geographic variability. The absence of trees and green space, an abundance of impervious surfaces, and concentrated emissions from vehicles and air conditioners can dramatically increase the temperature of urban areas, creating “heat islands”.
The Trust for Public Land has been publishing the annual Heat Severity Urban Areas index for the past few years; originally the dataset covered just incorporated places but was expanded to include the entire US. Index values from 1 to 5 indicate the severity of a heat island, measured relative to the average summer temperature for the city or place where each grid cell is located. The data is published as a grid at 30m resolution (matching the resolution of LANDSAT imagery used in their workflow) and is distributed via an ESRI hub site. You can search for it within the Living Atlas in the data catalog in ArcGIS Pro to add it to a project, or grab the url from the hub site to render it as a web mapping service in QGIS or another package. In order to use it in an analysis, you’ll need to export and save the raster locally. To save time and space, you can clip the layer to a polygon or extent of the screen, and then save the result.
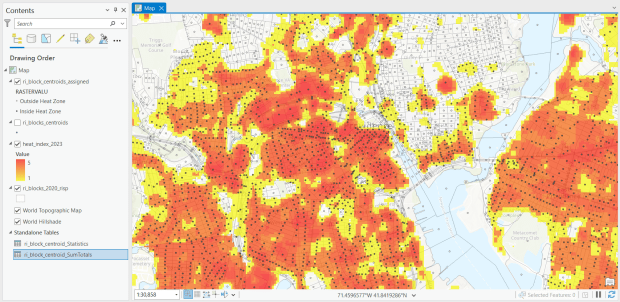
For one project, I had to estimate the number of people in Rhode Island who were living within an urban heat island. I used census block boundaries from the 2020 census, which include total population and housing units as attributes, calculated the centroid of the blocks, and overlaid them on the grid and assigned the intersecting grid value to each point. Then I summed the population by the index values; a value of null indicated that the center of the block fell outside a heat cell.
Urban Heat Severity Index overlayed with census blocks in Providence, RI in ArcGIS Pro
US Gridded Climate Data: PRISM
For rasters of climate data on temperature and precipitation, I’ve often turned to PRISM at Oregon State University. They work with the USDA to generate the maps for plant hardiness zones, and have developed a model to generate gridded climate data. The public data is available at 4km resolution, but researchers with project proposals can submit requests to access 800m resolution data. They publish mean daily, monthly, and annual values, as well as normals. Each raster is stored in one file, where the file represents one observation for one time period. I have written about PRISM in the past as I used it for several projects, writing Python scripts to pull a raster file for specific dates that match attributes in a point file, in order to determine what the temperature was for that date for each point, based on the grid cell the point fell within. PRISM has updated some of their products since I’ve run that analysis, specifically replacing the older raster file formats with tifs.
US County Climate Data: NCEI Climate at a Glance
For certain statistical analyses, it can be helpful to have climate data summarized for an entire geographic area so that it aligns with other variables that are published for that area. NOAA’s National Center for Environmental Information (NCEI) employs a model that takes their gridded data product (derived from the U.S. Climate Divisional Database) to produce monthly state and county-level estimates for the US, from 1895 to the present. I wrote a post that summarizes how to download, interpret, and parse these files so that you can start using them; if you’re seeking the entire dataset you’ll skip the web-based interface for creating summary charts and maps and go right to the FTP site to download data in bulk.
Since our current government doesn’t like the weather, this is one of the datasets that I’ve archived in DataLumos as part of the Data Rescue Project, in case it vanishes one day.
Global Climate Data: ERA5
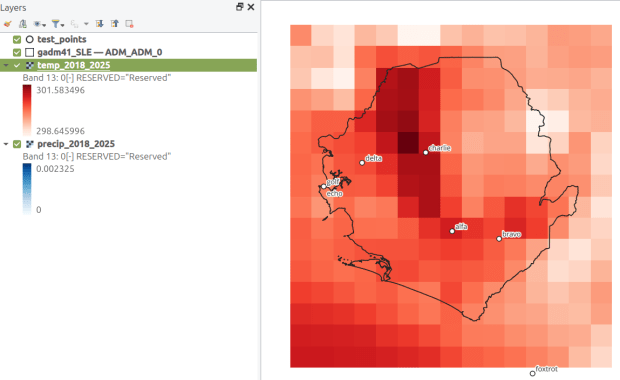
How about the rest of the world? ERA5 is produced by the European Centre for Medium-Range Weather Forecasts, which publishes gridded climate data at 1/4 degree resolution, modeled from 1940 to present. You can choose hourly, daily, or monthly estimates (accessed via separate web pages), and at the download stage you can provide bounding box coordinates to clip the data (so you don’t have to download the entire planet). The data is packaged in a GRIB file, where variables are stored in separate bands. So if you download monthly data for one variable, each month is stored sequentially; if you download two or more variables, they are sorted by variable and then by time period. Similar to my US project with PRISM, I wrote a Python script that extracts ERA5’s monthly gridded data for specific point locations, but in this case I pulled all dates for each point (with an option to highlight a specific month for a matching date). I wrote a detailed post that describes the dataset and process.
ERA5 mean monthly temperature data for Sierra Leone in QGIS
While spending February buried under snow here in Providence, I took the opportunity to update several of the data products we create here at GeoData@SciLi. I’ll provide a summary of what we’re working on in this post. The heading for each project links to its GitHub repo, where you can access the datasets and the scripts we wrote for creating them.
My overall vision has always been that library data services should go beyond simply finding public data and purchasing data for students and faculty; we should actively engage in creating value-added products to meet the research and teaching needs of the university. With a dedication to open data, we also contribute to building a data infrastructure that benefits our local communities, and researchers around world. Creating our own projects keeps our technical skills sharp, gives us more in-depth knowledge about working with particular datasets, and exposes us to the practical processing problems our users face, which makes us better at understanding these issues and thus better able to serve them. To ensure that we can maintain and update our datasets, we automate and script as many of our processes as much as possible. The goal is not to build products, but to build processes to create products.
This is our signature product, a geodatabase of basic Rhode Island GIS and tabular data that folks can use as a foundation for building local projects. The idea is to save mappers the trouble of reinventing the wheel every time they want to do state-based research. I’ve honed this idea over a long period of time; as an graduate student at UW twenty years ago I was creating census databases for the Seattle metropolitan area that we published in WAGDA. I expanded this concept at CUNY, where we created and updated the NYC Geodatabase for many years, which included all forms of mass transit data (which wasn’t readily available at the time). For the Rhode Island version, I pivoted to include layers and attributes that would be of interest at a state-level, and was able to re-use many of the scripts and processes I built previously.
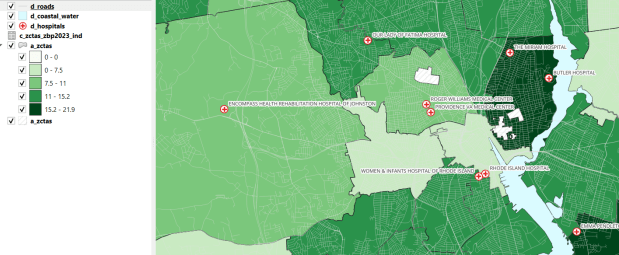
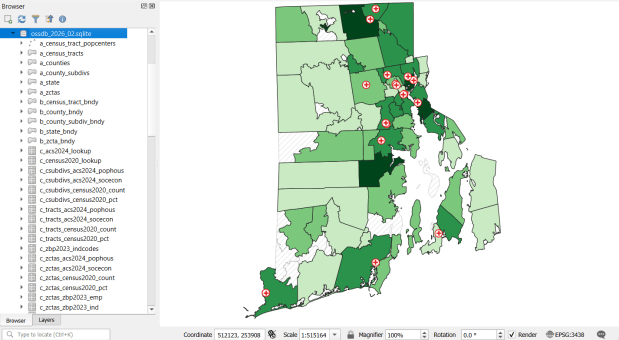
The Census TIGER files are the foundation, and we spent time creating suitably generalized base layers from them. Each layer or object is named with a prefix that categorizes and alphabetizes them in a logical order. “a” layers are areal features that represent land areas (counties, cities and towns, tracts, ZCTAs), “b” features are the actual legal boundaries for these areas (not generalized), “c” features are census data tables that can be joined to the a and b features, and “d” features consist of other points and lines (roads, water bodies, schools, hospitals, etc). The database is published in two formats: a Spatialite version for QGIS, and a file geodatabase for ArcGIS.
OSSDB Features and Sample Map in QGIS (Hospitals and the Percentage of Business Establishments that are Health Care Services by ZCTA)
Most of the features are fixed to the 2020 census and don’t change. There are two feature sets that we need to update every year. The first set are tables from the American Community Survey (ACS) and ZIP Code Business Pattern (ZBP). We’ve created tables that consist of a selection of variables that would be of broad interest to many users. We use python notebooks to download the data from the Census Bureau’s API. The ACS variable IDs and labels are stored in a spreadsheet that the script reads in, and checks it against the Census Bureau’s variable list for the demographic profile tables, to see if identifiers and labels have changed compared to the previous year. They often change, so the program flags these and we update the spreadsheet to pull the correct variables. We run the program for a specific geography, and the results are stored in a temporary database. For the ZBP data, we crosswalk and aggregate ZIP Codes to ZCTAs to create ZCTA-level data. I have separate scripts for quality control, where we check number of columns, count of rows, and any given variable to data from last year to see if there are any significant differences that could be errors, and another script for copying the data from the temporary database into the new one.
The other set of features we update are points representing schools, colleges and universities, hospitals, and public libraries. The libraries come from a federal source (IMLS PLS survey), while the others come from state sources (schools and colleges from an educational directory, and hospitals from a licensing directory). We use python to access RIDOT’s geocoding API (their parcel or point-based geocoder) to get coordinates for each feature. There’s a lot of exception handling, to deal with bad or non-matching addresses, some of which creep up every year. I store these in a JSON file; the program runs a preliminary check to see if these addresses have been corrected, and if they’re not the program uses the good address stored in the JSON. For quality control, the Detect Dataset Changes tool in the QGIS Processing toolbox allows us to see if features and attributes have changed, and we do extra work to verify the existence of records that have fallen in or out since last year.
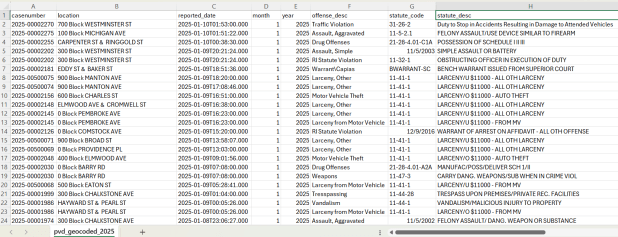
A few years ago I had an excellent undergraduate fellow in the Data Sciences program who created a process for taking all of the police case logs from the Providence Open Data Portal and creating a GIS dataset out of them. We created this dataset for three reasons: the portal contains just the last 180 days and we wanted to create a historic archive, the records did not have coordinates, and the crimes were not standardized. Geocoding was the biggest challenge, as the location information was listed as one of the following: a street intersection, a block number, or a landmark. The script identifies the type of location, and then employs a different procedure for each. Intersections were easy, as we could pass these to the RIDOT geocoder (their street-interpolation geocoder). For block numbers, the program looks at a local file that contains all addresses in the state’s 911 database, which we filter down to just the City of Providence. It finds the matching street, gets the minimum and maximum address numbers within the given block, and computes the centroid between those addresses. For landmarks like Roger Williams Park or Providence Place Mall, we have a local list of major landmarks with coordinates that the program draws from. All non-matching addresses are written to a separate file, and you have the opportunity to add additional landmarks that didn’t match and rerun them. Crimes are matched to the FBI’s uniform categories for violent and non-violent crime, and there’s also an opportunity to update the list if new incident descriptions appear in the data.
Providence Crime Incident Data
We warn users that the matches are not exact, and this needs to be kept in mind when doing any analysis; for every incident we record the match type so users can assess quality. For all of our projects, we provide detailed documentation that explains exactly how the data was created. At this point we have half the data for 2023, and everything for 2024 and 2025. We run the program a few times each year, to ensure that we capture every incident before 180 days elapses.
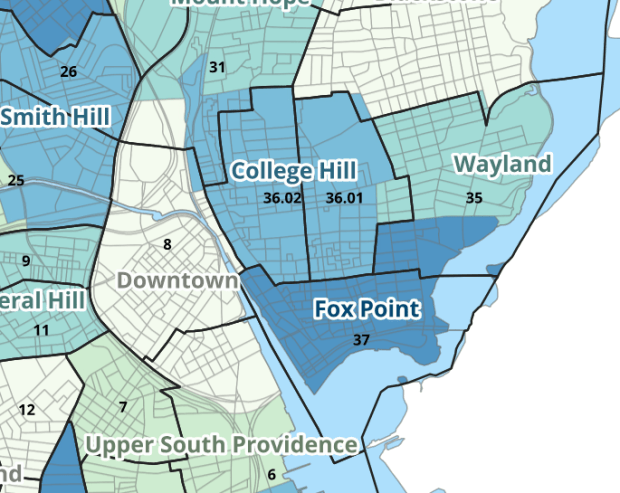
I wrote about this project when we released it last year; it is a set of relational tables for taking census data published at the tract, block group, and block level, and apportioning and aggregating it to local Providence geographies that include neighborhoods and wards (there’s also a crosswalk for ZCTAs to local geographies, but it’s rather useless as there is little correspondence). We also published a set of reference maps for showing correspondence or lack thereof between the census and local areas.
Census Tracts (black outlines) and Neighborhoods in Providence
The newest development is that one of my undergraduates used the crosswalk to generate 2020 census demographic profile summaries for neighborhoods and wards, so that users can simply download a pre-compiled set of data without having to do their own crosswalking. Population and household variables were apportioned using total population as a weight, while housing unit variables were apportioned using total housing units. He also generated percent totals for each variable, which required carefully scrutinizing what the proper numerators and denominators should be based on published census results. Python to the rescue again, he used a notebook that read the census tables in from the Ocean State Spatial Database, which saved us the trouble of using the census API. We publish the data tables in the same GitHub repository as the crosswalk.
I haven’t updated this one yet, but it’s next on the list. I wrote about this project a few years ago; this is a country-level index that documents variation in the cost of living at different UN duty stations. The UN publishes this data at different intervals throughout the year, in macro-driven Excel files that allow you to pull up data for one country at a time. The trick for this project was looping through hundreds of these files, finding the data hidden by the macro, and turning it into a single time series that includes unique identifiers for place, time, and good / service. This project was born from a research request from a PhD student, and we saw the value of building a process to keep it updated and to publish it for others to use. The scripting was done by the first undergraduate student worker I had at Brown, Ethan McIntosh. Thanks to him, I download the new data each year, run the program, and voila, new data!
Conclusion
I hope you found this summary useful, either because you can use these datasets, or you can learn something from one of our scripts and processes that you can apply to your own work. I hope that more academic libraries will embrace the concept of being data creators, and would incorporate this work into their data service models (along with formally contributing to existing initiatives like the Data Rescue Project or the OpenStreetMap). Feel free to reach out with comments and feedback.
HIFLD Open, a key repository for accessing US GIS datasets on infrastructure, is shutting down on August 26, 2025. This is a revision from a previous announcement, which said that it would be live until at least Sept 30. The portal provided national layers for schools, power lines, flood plains, and more from one convenient location. DHS provides no sensible explanation for dismantling it, other than saying that hosting the site is no longer a priority for their mission (here’s a copy of an official announcement). In other words, “Public domain data for community preparedness, resiliency, research, and more” is no longer a DHS priority.
The 300 plus datasets in Open HIFLD are largely created and hosted by other agencies, and Open HIFLD was aggregating different feeds into one portal. So, much of the data will still be accessible from the original sources. It will just be harder to find.
DHS has published a crosswalk with links to alternative portals and the source feeds for each dataset, so you can access most of the data once Open HIFLD goes offline. I’ve saved a copy here, in case it also disappears. Most of these sources use ESRI REST APIs. Using ArcGIS Online or Pro, and even QGIS (for example), you can connect to these feeds, get a listing in your contents pane, and drag and drop layers into a project (many of the layers are also available via ArcGIS Online or the Living Atlas if you’re using Arc). Once you’ve added a layer to a project, you can export and save local copies.
Adding ArcGIS Rest Server for US Army Corps of Engineers Data in QGIS
If you want to download copies directly from Open HIFLD before it vanishes on Aug 26, I’ve created this spreadsheet with direct links to download pages, and to metadata records when available (some datasets don’t have metadata, and the links will bring you to an empty placeholder). Some datasets have multiple layers, and you’ll need to click on each one in a list to get to it’s download page. In some cases there won’t be a direct download link, and you’ll need to go to the source (a useful exercise, as you’ll need to remember where it is in the future). Alternatively, you can connect to the REST server (before Aug 26, 2025) in QGIS or ArcGIS, drag and drop the layers you want, and then export:
I’m coordinating with the Data Rescue Project, and we’re working on downloading copies of everything on Open HIFLD and hosting it elsewhere. I’ll provide an update once this work is complete. Even though most of these datasets will still be available from the original sources, better safe than sorry. There’s no telling what could disappear tomorrow.
The secure HIFLD site for registered users will remain available, but many of the open layers aren’t being migrated there (see the crosswalk for details). The secure site is available to DHS partners, and there are restrictions on who can get an account. It’s not exactly clear what they are, but it seems unlikely that most Open users will be eligible: “These instructions [for accessing a secure account] are for non-DHS users who support a homeland security or homeland defense mission AND whose role requires access to the Geospatial Information Infrastructure (GII) and/or any geospatial dashboards, data, or tools housed on the GII…“
Let’s say you have different sets of points, and each set represents a distinct category of features. Maybe villages where residents speak different languages, or historical events that occurred during different epochs. Beyond plotting and symbolizing the points, perhaps you would like to create areas for each set that represent generalized territory, and you’d like to see how these areas correspond. I’ll demonstrate a few approaches for achieving this, using convex hulls, attribute table calculations, and geoprocessing tools like intersection and union. A convex hull is a minimum bounding polygon, where an area is drawn around all points in a set, where the outermost points serve as vertices for creating boundaries.
I’ll use QGIS for this example, but will mention the corresponding tools in ArcGIS Pro at the end. In QGIS we’ll use the tools that are located within the Processing Toolbox (gear icon on the toolbar). Unlike the shortcut tools under the Vector menu, these tools provide more options and allow us to process multiple files at once.
Steps in QGIS
First, we need either distinct point files for each set of features, or a single file with a categorical variable that distinctly identifies different sets of features. For this example I’ll use three distinct files that I’ve generated using phony sample data. The points are in a projected coordinate system (important!) that’s appropriate for the area I’m mapping.
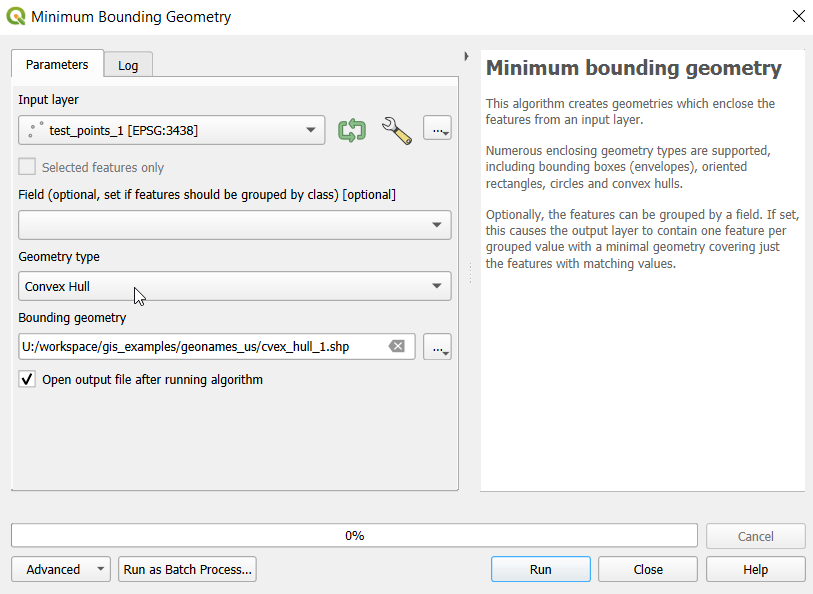
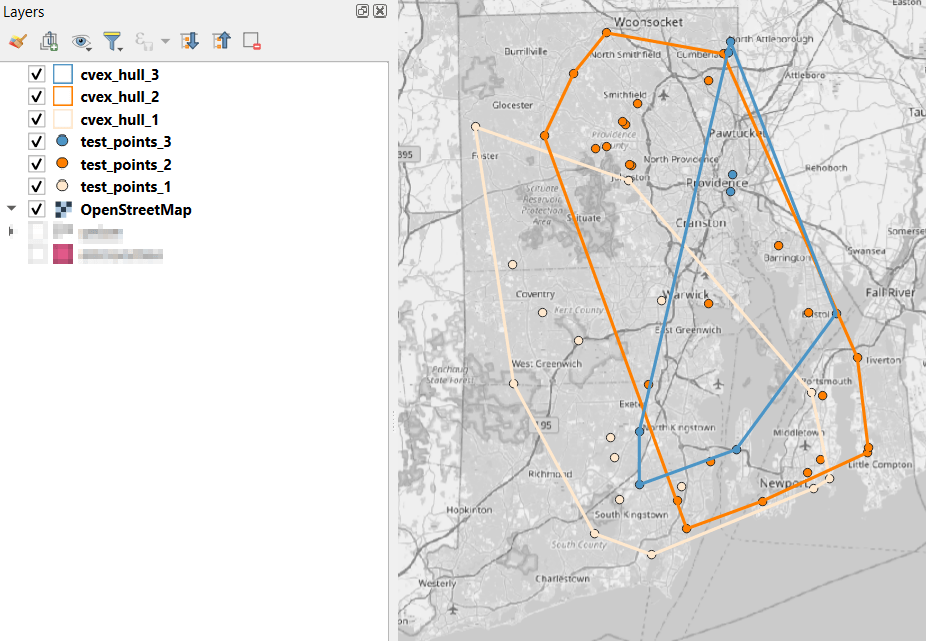
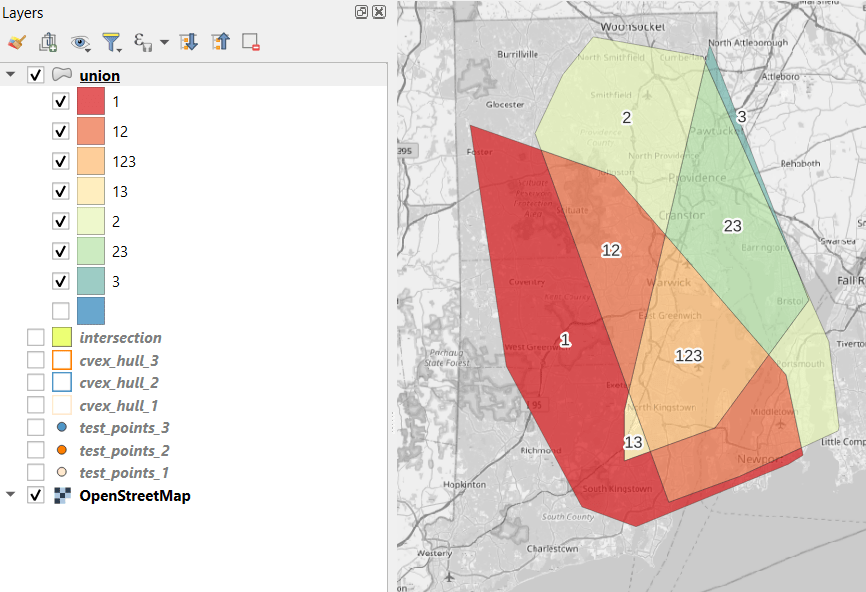
In the QGIS Processing Toolbox, we select the Minimum Bounding Geometry (MBG) tool, and under the Geometry Type specify that we want to create a convex hull. I ran this tool for each file, creating three convex hull files (alternatively, if you had one file with distinct categories, you could use the Field option to generate separate hulls for each category). I’ve symbolized the output below, making the fill hollow and assigning an outline that matches the color of the points. This gives you a good sense for the coverage areas for the points, and how they overlap.
Before running additional tools to explicitly measure overlap, we need to modify the attribute tables of the convex hulls, so we’ll have useful attributes to carry over. The MBG tool creates a new layer with an ID number, area, and perimeter. The ID is set to zero for each hull file, but we should change it to distinctly represent the file / category. With the attribute table open, we can go into an edit mode and type in a new integer value; in this case I’m assigning 1, 2, and 3 to each of the test layers. Alternatively, you could add a new field and assign it a meaningful category value.
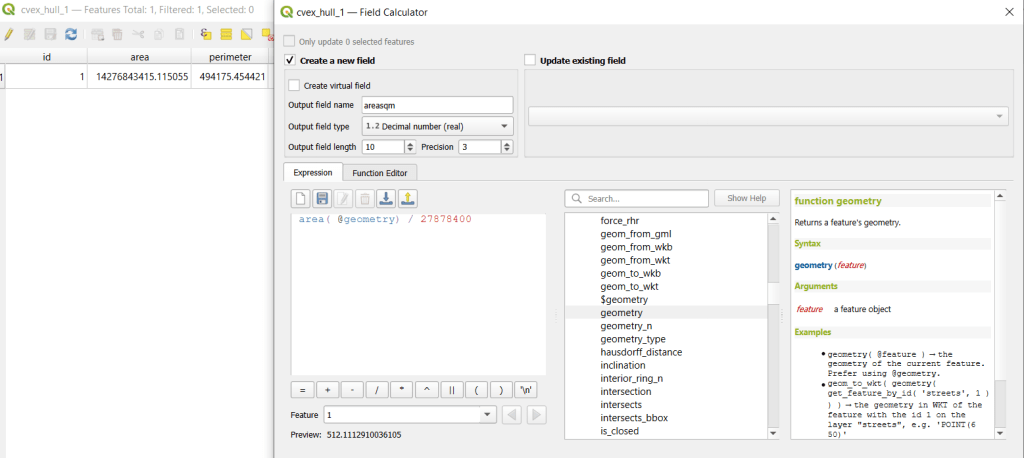
The units for area and perimeter match the units used by the map projection of the layer, which is why we want to use a projected coordinate system that uses meters or feet, and not a geographic one (like WGS 84 or NAD 83) that uses degrees. I’m using a state plane system, so the area is in square feet. To convert this to square miles, within the attribute table view I use the Field Calculator to add a new decimal field, and divide the value of the area by 27,878,400 (the number of sq feet in a sq mile; for metric units in meters, we’d divide by 1,000,000 to get sq km). We calculate the area directly from the polygon geometry:
area( @geometry) / 27878400
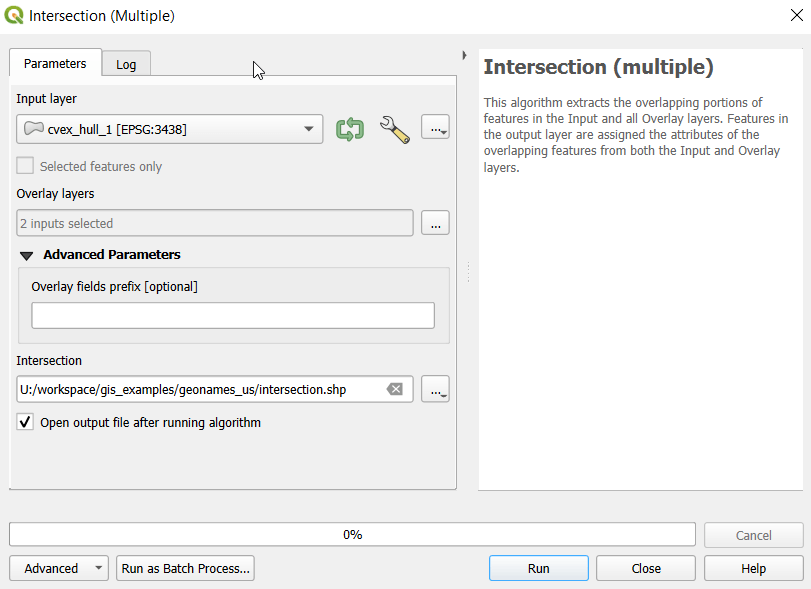
To generate the area of intersection, we go into the Processing tool box and run the Intersection (multiple) tool. The first convex hull is the input layer, while the overlay layers are the other two hull files (in the dialog box, we check the layers we want, and then use the arrow to navigate back to the tool to run it). The output is a new file with polygon(s) that cover the area where all three layers intersect. Its attribute table contains an ID, area, and perimeter field, and we can calculate a new area field in sq miles and see how it compares to the total areas. In my example, the area where all three territories intersect covers about 112 sq miles, while the areas for the individual territories are 512, 563, and 256 sq miles respectively.
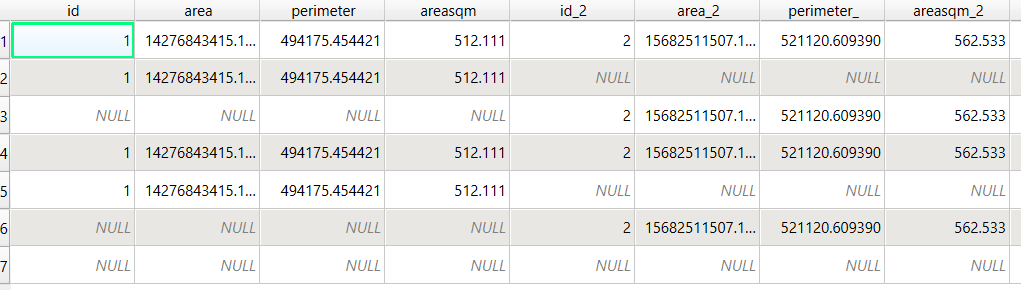
To identify distinct areas of overlap between the territories, we return to the Processing toolbox and run the Union (multiple) tool. The dialog is similar to the intersection tool, where the first hull is the union layer and the additional hulls are overlay layers. The output of this tool is a layer with distinct polygons where the hulls coincide. The attribute table for the union layer carries over the attributes from each of the three layers, with columns suffixed with underscores and sequential integers. So if a polygon consists of area covered by hulls 1 and 2, those attributes will be filled in, while the attributes of 3 will be null. As before, we can calculate an area in sq miles for the new polygons. In this case, we’d see that the area covered by hull 1 without any overlapping hulls is 240 sq miles, the largest of all territories.
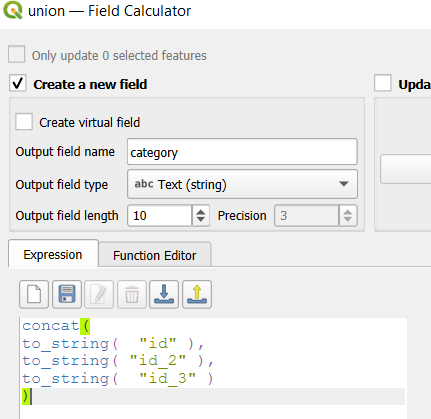
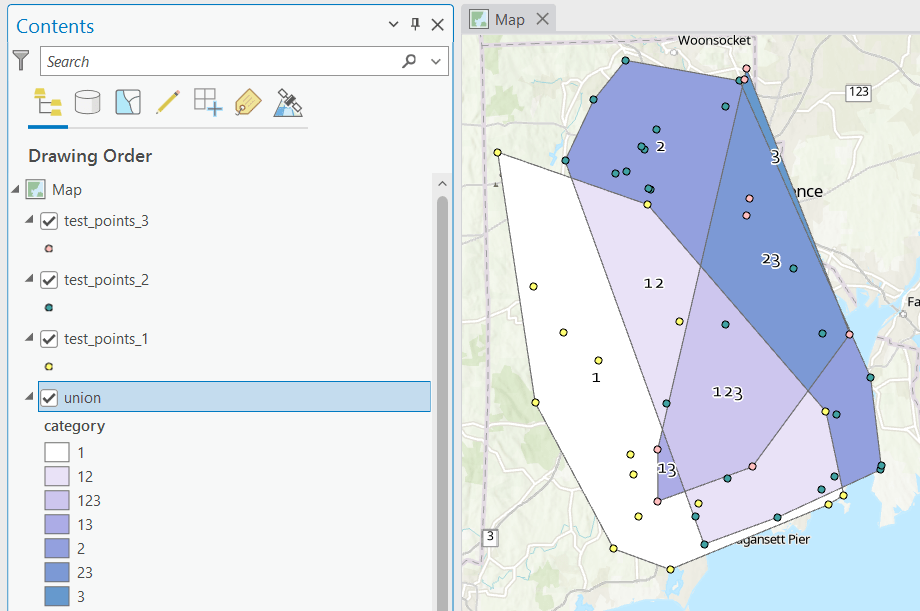
To explicitly categorize these areas, we can add a new field in the attribute table. This will be a text field, where we take the ID numbers, convert them to strings, and concatenate them. In the example above, IDs 1 and 2 would be concatenated to 12, and since the value for 3 is null, no text is appended. (Variation – if you created distinct text-based category fields instead of using the integer IDs, you could concatenate them directly without having to convert them to strings). Using the symbology tool, we can classify the data using these new categories, and can modify the color scheme to something appropriate for displaying the contributions from each area. So a polygon with category 1 includes areas covered by the first convex hull and no others, while category 12 includes areas where hulls 1 and 2 overlapped.
With the areas of the individual union pieces, we can compute the percentages of each territory that fall inside and outside various overlapping zones with the field calculator. For example, we can calculate the total area of the union file (which is NOT the sum of each hull, as there’s overlap between them), and then divide each feature by that total to get its percent total. The expression for doing this is below; the numerator has the name of the field that contains the area of each polygon in sq miles, while the denominator includes the calculation for the sum of all parts (alternatively you could use the QGIS Statistics tool to compute this, and hard code the total into the formula):
If the idea is to create areas of territory that the points exert influence on, you may want to add a buffer to each hull, to account for the fact that the outer points that form the boundaries will exert influence on both sides of the boundary. Use the Processing – Buffer tool. For the buffer distance, you can use an arbitrary value that makes sense for the circumstances. Or you can generate a relative value that represents a fraction of each convex hull’s area. The output of the buffer tool would then serve as the input to the intersection and union tools.
These examples focus on area. If the number of points that falls within the areas is important, you can use the Points in Polygon tool on each of the hulls to count points, and then do the same for the output of the intersection and union tools to get the different points counts for each set of polygons.
ArcGIS Pro Corollaries
Following the same steps above for QGIS, but with ArcGIS Pro:
In the red toolbox, the Minimum Boundary Geometry tool is used to create convex halls. It’s quite similar to the one in QGIS: specify the geometry type, and there is an option to Group (if you have one file with categories). If you leave the Add geometry characteristics box unchecked, it will still compute basic area and perimeter; the checkbox adds a bunch of additional fields.
Unlike QGIS, ArcGIS will not allow you to modify its OBJECTID field. To create a unique value for each hull, you will have to open the attribute table and use the Calculate tool to create a category field (integer or text). To ensure that you can carry it over, in ArcGIS you need to give this column a different name in each hull: cat1, cat2, cat3. Set the value at the bottom in the expression box.
You can use the calculate tool in the attribute table to generate an area column in sqft or sqkm, or use the Calculate Geometry Tool in the toolbox instead. The latter is actually simpler: create a new column, and choose Area and the output units.
The Intersect tool will create the intersection, and functions similarly to QGIS.
The Union tool creates the union, and also functions similarly.
Creating the category field in the union file is a bit more complicated, as ArcGIS assigns values of 0 instead of NULL for non-overlapping polygons. In the Calculate window, with the input file as Union and the field as category, change the Expression type to Arcade (ESRI’s scripting language). First, run an expression to concatenate the categories and convert integers to strings (if necessary). Then, replace that expression with a second one that replace the zeros with nothing.
This is a basic approach, appropriate for certain use cases where you want to generate areas from points; particularly when different point sets have a well defined category, so there’s no question of how to group them. Also appropriate where you don’t have – or don’t want – hard boundaries between sets of points and want to see areas of overlap. More sophisticated methods exist for separating points into clusters based on density, distance, and similar attributes, such as K-Means and DB Scan. You can generate non-overlapping territories for individual points using Thiessen / Voronoi polygons, and for points with a sufficiently high density, you can generate rasters with kernel tools.
I made my first foray into network routing recently, and drafted a python script and notebook that plots routes using the OpenRouteService (ORS) API. ORS is based on underlying data from the OpenStreetMap (OSM), and was created by the Heidelberg Institute for Geoinformation Technology, at Heidelberg University in Germany. They publish several routing APIs that include directions, isochrones, distance matricies, geocoding, and route optimization. You can access them via a basic REST API, but they also have a dedicated Python wrapper and an R package which makes things a bit easier. For non-programmers, there is a plugin for QGIS.
Regardless of which tool you use, you need to register for an API key first. The standard plan is free for small projects; for example you can make 2,000 direction requests per day with a limit of 40 per minute. If you’re affiliated with higher ed, government, or a non-profit and are doing non-commercial research, you can upgrade to a collaborative plan that ups the limits. It’s also possible to install OSR locally on your own server for large jobs.
I opted for Python and used the openrouteservice Python module, in conjunction with other geospatial modules including geopandas and shapely. In my script / notebook I read in two CSV files, one with origins and the other with destinations. At minimum both files must contain a header row, and attributes for unique identifier, place label, longitude, and latitude in the WGS 84 spatial reference system. The script plots a route between each origin and every destination, and outputs three shapefiles that include the origin points, destination points, and routes. Each line in the route file includes the ID and names of each origin and destination, as well as distance and travel time. The script and notebook are identical, except that the script plots the end result (points and lines) using geopanda’s plot function, while the Jupyter Notebook plots the results on a Folium map (Folium is a Python implementation of the popular Leaflet JS langauge).
After importing the modules, you define several variables that determine the output, including a general label for naming the output file (routename), and several parameters for the API including the mode of travel (driving, walking, cycling, etc), distance units (meters, kilometers, miles), and route preference (fastest or shortest). Next, you provide the positions or “column” locations of attributes in the origin and destination CSV files for the id, name, longitude, and latitude. Lastly, you specify the location of those input files and the file that contains your API key. The location and names of output files are generated automatically based on the input; all will contain today’s date stamp, and the route file name includes route mode and preference. I always use the os module’s path function to ensure the scripts are cross-platform.
import openrouteservice, os, csv, pandas as pd, geopandas as gpd
from shapely.geometry import shape
from openrouteservice.directions import directions
from openrouteservice import convert
from datetime import date
from time import sleep
# VARIABLES
# general description, used in output file
routename='scili_to_libs'
# transit modes: [“driving-car”, “driving-hgv”, “foot-walking”, “foot-hiking”, “cycling-regular”, “cycling-road”,”cycling-mountain”, “cycling-electric”,]
tmode='driving-car'
# distance units: [“m”, “km”, “mi”]
dunits='mi'
# route preference: [“fastest, “shortest”, “recommended”]
rpref='fastest'
# Column positions in csv files that contain: unique ID, name, longitude, latitude
# Origin file
ogn_id=0
ogn_name=1
ogn_long=2
ogn_lat=3
# Destination file
d_id=0
d_name=1
d_long=2
d_lat=3
# INPUTS and OUTPUTS
today=str(date.today()).replace('-','_')
keyfile='ors_key.txt'
origin_file=os.path.join('input','origins.csv') #CSV must have header row
dest_file=os.path.join('input','destinations.csv') #CSV must have header row
route_file=routename+'_'+tmode+'_'+rpref+'_'+today+'.shp'
out_file=os.path.join('output',route_file)
out_origin=os.path.join('output',os.path.basename(origin_file).split('.')[0]+'_'+today+'.shp')
out_dest=os.path.join('output',os.path.basename(dest_file).split('.')[0]+'_'+today+'.shp')
I define some general functions for reading the origin and destination files into nested lists, and for taking those lists and generating shapefiles out of them (by converting them to geopanda’s geodataframes). We read the origin and destination data in, grab the API key, set up a list to hold the routes, and create a header for the eventual output.
# For reading origin and dest files
def file_reader(infile,outlist):
with open(infile,'r') as f:
reader = csv.reader(f)
for row in reader:
rec = [i.strip() for i in row]
outlist.append(rec)
# For converting origins and destinations to geodataframes
def coords_to_gdf(data_list,long,lat,export):
"""Provide: list of places that includes a header row,
positions in list that have longitude and latitude, and
path for output file.
"""
df = pd.DataFrame(data_list[1:], columns=data_list[0])
longcol=data_list[0][long]
latcol=data_list[0][lat]
gdf = gpd.GeoDataFrame(df, geometry=gpd.points_from_xy(df[longcol], df[latcol]), crs='EPSG:4326')
gdf.to_file(export,index=True)
print('Wrote shapefile',export,'\n')
return(gdf)
origins=[]
dest=[]
file_reader(origin_file,origins)
file_reader(dest_file,dest)
# Read api key in from file
with open(keyfile) as key:
api_key=key.read().strip()
route_count=0
route_list=[]
# Column header for route output file:
header=['ogn_id','ogn_name','dest_id','dest_name','distance','travtime','route']
Here are some nested lists from my sample origin and destination CSV files:
Then the API call begins. For every record in the origin list, we iterate through each record in the destination list (in both cases starting at index 1, skipping the header row) and calculate a route. We create a tuple with each pair of origin and destination coordinates (coords), which we supply to the OSR directions API. We pass in the parameters supplied earlier, and specify instructions as False (instructions are the actual turn by turn directions returned as text).
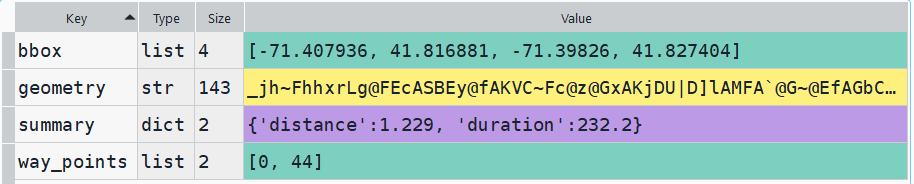
The result is returned as a JSON object, which we can manipulate like a nested Python dictionary. At the first level in the dictionary, we have three keys and values: a bounding box for the route area with a list value, metadata with a dictionary value, and routes with a list value. Dive into route, and the list contains a single dictionary, and inside that dictionary – more dictionaries that contain the values we want!
1st level, dictionary with three keys, the routes key has a single list value2nd level, the routes list has a single element, another dictionary3rd level, inside the dictionary in that list element, four keys with route data
The next step is we extract the values that we need from this container by specifying their location. For example, the distance value is inside the first list of routes, inside summary and inside distance. Travel time is in a similar spot, and we take an extra step of dividing by 60 to get minutes instead of seconds. The geometry is trickier as its encoded in some binary line format. We use OSR’s decoding function to turn it into plain text, and shapely to convert it into WKT text; we’ll need WKT in order to get the geometry into a geodataframe, and eventually output as a shapefile. Once we have the bits we need, we string them together as a list for that origin / destination pair, and append this to our route list.
# API CALL
for ogn in origins[1:]:
for d in dest[1:]:
try:
coords=((ogn[ogn_long],ogn[ogn_lat]),(d[d_long],d[d_lat]))
client = openrouteservice.Client(key=api_key)
# Take the returned object, save into nested dicts:
results = directions(client, coords,
profile=tmode,instructions=False, preference=rpref,units=dunits)
dist = results['routes'][0]['summary']['distance']
travtime=results['routes'][0]['summary']['duration']/60 # Get minutes
encoded_geom = results['routes'][0]['geometry']
decoded_geom = convert.decode_polyline(encoded_geom) #convert from binary to txt
wkt_geom=shape(decoded_geom).wkt #convert from json polyline to wkt
route=[ogn[ogn_id],ogn[ogn_name],d[d_id],d[d_name],dist,travtime,wkt_geom]
route_list.append(route)
route_count=route_count+1
if route_count%40==0: # API limit is 40 requests per minute
print('Pausing 1 minute, processed',route_count,'records...')
sleep(60)
except Exception as e:
print(str(e))
api_key=''
print('Plotted',route_count,'routes...' )
Here is some sample output for the final origin / destination pair, which contains the IDs and labels for the origin and destination, distance in miles, time in minutes, and a string of coordinates that represents the route:
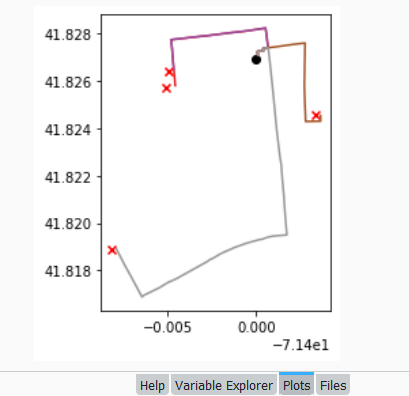
Finally, we can write the output. We convert the nested route list to a pandas dataframe and use the header row for column names, and convert that dataframe to a geodataframe, building the geometry from the WKT string, and write that out. In contrast, the origins and destinations have simple coordinates (not in WKT), and we create XY geometry from those coordinates. Writing the geodataframe out to a shapefile is straightforward, but for debugging purposes it’s helpful to see the result without having to launch GIS. We can use geopandas’s plot function to draw the resulting geometry. I’m using the Spyder IDE, which displays plots in a dedicated window (in my example the coordinate labels for the X axis look strange, as the distances I’m plotting are small).
# Create shapefiles for routes
df = pd.DataFrame(route_list, columns=header)
gdf = gpd.GeoDataFrame(df, geometry=gpd.GeoSeries.from_wkt(df["route"]),crs = 'EPSG:4326')
gdf.drop(['route'],axis=1,inplace=True) # drop the wkt text
gdf.to_file(out_file,index=True)
print('Wrote route shapefile to:',out_file,'\n')
# Create shapefiles for origins and destinations
ogdf=coords_to_gdf(origins,ogn_long,ogn_lat,out_origin)
dgdf=coords_to_gdf(dest,d_long,d_lat,out_dest)
# Plot
base=gdf.plot(column="dest_id", kind='geo',cmap="Set1")
ogdf.plot(ax=base, marker='o',color='black')
dgdf.plot(ax=base, marker='x', color='red');
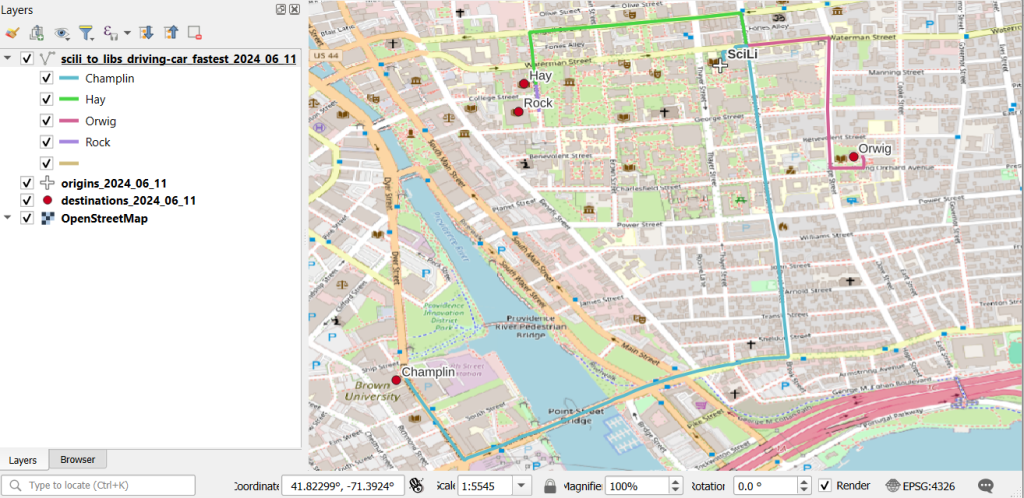
In a notebook environment we can employ something like Folium more readily, which gives us a basemap and some basic interactivity for zooming around and clicking on features to see attributes. Implementing this was a more complex than I thought it would be, and took me longer to figure out compared to the routing process. I’ll return to those details in a subsequent post…
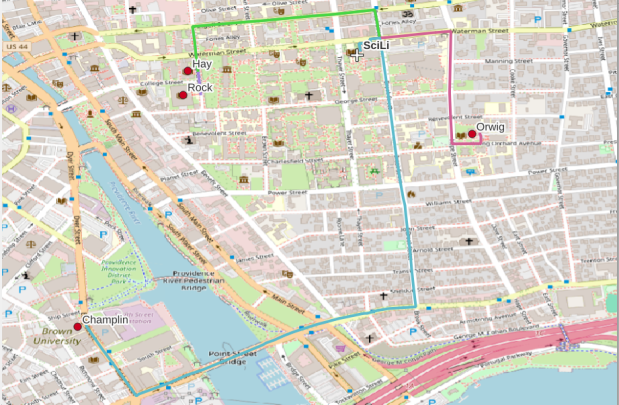
In my sample data (output rendered below in QGIS) I was plotting fastest driving distance from the Brown University Sciences Library to the other libraries in our system. Compared to Google or Apple Maps the result made sense, although the origin coordinates I used for the SciLi had an impact on the outcome (assumed you left from the loading dock behind the building as opposed to the front door as Google did, which produces different routes in this area of one-way streets). My real application was plotting distances of hundreds of miles across South America, which went well and was useful for generating different outcomes using fastest or shortest route.








You must be logged in to post a comment.