I posted the latest version of my Introduction to GIS with QGIS tutorial manual, updated for QGIS 3.44 Solothurn. The manual and sample data are freely available from my lab’s tutorials page.
This year’s changes are minor, as there weren’t major software updates that would impact the exercises. I updated the sample data as it was growing a bit stale, which necessitated updating screenshots and references in the text. I also updated the source LaTeX code to ensure the PDF meets the new federal WCAG guidelines for digital accessibility. I added a brief troubleshooting section on using QGIS with a Mac to the Introduction, as there have been a creeping number of annoying problems that have thrown my workshops off kilter (MacOS security blocking installation and writing of files to the user’s documents folder, and UI issues with the default color scheme and hiding menus in the background).
It’s hard to believe this is the 16th edition of this manual. When I wrote the first version back in 2011 (it was originally called Introduction to GIS Using Open Source Software), there was relatively little documentation on QGIS. In launching a workshop series and on-going support for it, I felt that I needed to create a basic guidebook. QGIS was far more primitive back then; converting the CRS for a GIS file required a separate command-line program, and you had to calculate natural breaks by hand! QGIS has certainly come a long way since then, and has been widely adopted. I’ve updated my materials as the software has evolved, but overall I’ve stuck to the same plan in terms of content, with modifications to the examples:
Introduction: a general overview of the workbook, goals for the material and workshop, and updates to the manual since the previous version.
An Overview of GIS: a short narrative that describes basic GIS concepts, and open source software.
Exploring the Interface: explanation of the interface, adding vector data and viewing and selecting features, adding raster data, web base maps, and project files.
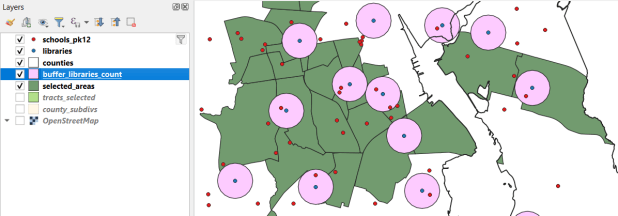
Geographic Analysis: a cohesive case study that illustrates the process for doing an analysis while showcasing fundamental operations including: tables joins, plotting coordinate data, selecting, filtering, and deleting features, and geoprocessing tools like intersection and buffering. My original case study was locating a new comic book store in NYC, subsequently modified to locating a coffee shop, and more recently identifying public libraries in Rhode Island that met criteria for a grant to host an after school program.
Thematic Mapping: exercise for understanding coordinate reference systems and how they function in QGIS, transforming systems, classifying data, and creating a final map layout. The original example was mapping healthcare sector employment by US state, but eventually switched to voter participation in federal elections.
Data and Educational Resources: strategies and suggestions for finding GIS data, and recommendations for learning more through tutorials and workshops.
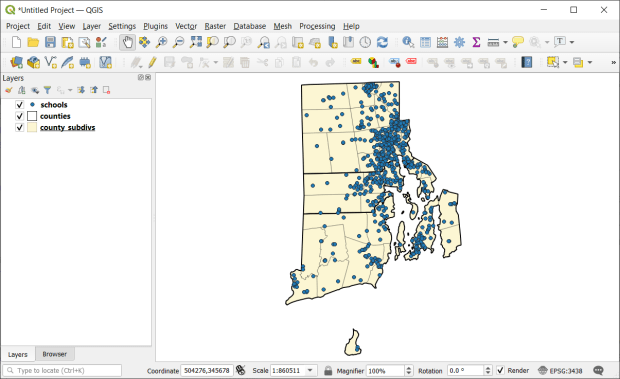
QGIS 3.44 Solothurn interface in Windows 11, used for the 16th edition of the manual in 2026
I’ve always used a follow-the-leader approach in teaching the workshop, where we stay together and the group does the material step by step. Everyone is a little fatigued by the end of the day, so for the thematic mapping piece we pivot to using the workbook; I demo the material and folks work on their own. I primarily wrote the book as a takeaway, so people could refer back to it after the session was over. It was also useful for self-directed learning, and the act of writing and updating it helps me internalize the material.
The last couple of years have been challenging though, and I have been thinking about what I could do differently. There have been a number of articles recently that discuss declining attention spans and students’ diminishing ability to thoughtfully engage with text (for example, in The Economist and The Atlantic). My own experiences bear this out. Increasingly, participants have a hard time following me in the session, and when I have student employees do the tutorial on their own as part of orientation, it takes them much longer and they struggle to finish. I have other workshops where I don’t use the follow-the leader approach, and instead I demo the material and everyone works on their own using the text, and once everyone finishes we move on to the next part. This works no better, as many participants wander away (mentally and physically) from the exercises and struggle to relate the text to what’s on the screen. Now, a good deal of success hinges on having good instructions, but I update them every year, and have used the same system and material in earlier years to good effect.
I have considered creating a more interactive web version of the workbook, or creating videos. The problem with both is that updating them each year would be far more time consuming; in contrast, updating the text and images in the workbook is pretty straightforward. I had one colleague suggest that my “old school” workbook fills an important niche in terms of structure and format, and is useful “as is” for deep learners. A professor I work with, who has had similar experiences in the classroom, expressed that there’s a limit to what an instructor can do; we can only simplify the material so much, and it’s up to students to rise to the occasion.
Reflecting on how I learn, I have gradually moved to videos to learn new material: whether it’s understanding a particular GIS method or tool, mastering a video game, or figuring out how to replace the belt on my clothes drier. Nothing beats a book for getting a comprehensive introduction to a topic, but the videos are helpful for targeted, stand-alone tasks. They can be comprehensive too, if they’re thoughtfully designed as part of a series. I’m definitely going to keep the workbook manual going, but am considering a video version for the future. I’ll wait until the 4.x version of QGIS becomes the new long term release (early next year) before I head in that direction, as the jump from 3.x to 4.x is more likely to come with some interface and functional changes.
The workbook has gotten a lot of miles these past 16 years, and I know others have used it for their own workshops and courses. Feel free to reach out if you have any suggestions.
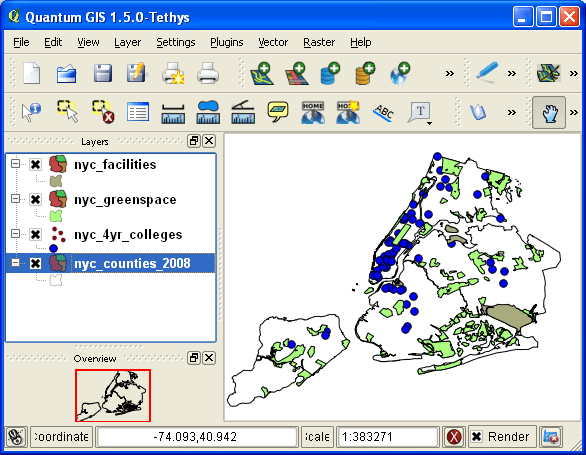
QGIS 1.5 Tethys interface in Windows XP, used for the 1st edition of the manual in 2011
I recently revisited a project from a few years ago, where I needed to extract temperature and precipitation data from a raster at specific points on specific dates. I used python to iterate through the points and pull up a raster for matching attribute dates, and Rasterio to overlay the raster and extract the climate data at those points. I was working with PRISM’s daily climate rasters for the US, where each nation-wide file represented a specific variable and date, and the date was embedded in the filename. I wrote a separate program to clip the raster to my area of interest prior to processing.
This time around, I am working with global climate data from ERA5, produced by the European Centre for Medium-Range Weather Forecasts (ECMWF). I needed to extract all monthly mean temperature and total precipitation values for a series of points within a range of years. Each point also had a specific date associated with it, and I had to store the month / year in which that date fell in a dedicated column. The ERA5 data is packaged in a single GRIB file, where each observation is stored in sequential bands. So if you download two full years worth of data, band 1 would contain January of year 1, while band 24 holds December of year 2. This process was going to be a bit simpler than my previous project, with a few new things to learn.
There are multiple versions of ERA5; I was using the monthly averages but you can also get daily and hourly versions. The cell resolution was 1/4 of a degree, and the CRS is WGS 84. When downloading the data, you have the option to grab multiple variables at once, so you could combine temperature and precipitation in one raster and they’d be stored in sequence (all temperature values first, all precipitation values second). To make the process a little more predictable, I opted for two downloads and stored the variables in separate files. The download interface gives you the option to clip the global image to bounding coordinates, which is quite convenient and saves you some extra work. This project is in Sierra Leone in Africa, and I eyeballed a web map to get appropriate bounds.
I follow my standard approach, creating separate input and output folders for storing the data, and placing variables that need to be modified prior to execution at the top of the script. The point file can be a geopackage or shapefile in the WGS 84 CRS, and we specify which raster to read and mark whether it’s temperature or precipitation. The point file must have three variables: a unique ID, a label of some kind, and a date. We store the date of the first observation in the raster as a separate variable, and create a boolean variable where we specify the format of the date in the point file; standard_date is True if the date is stored as YYYY-MM-DD or False if it’s DD-MM-YYYY.
import os,csv,sys,rasterio
import numpy as np
import matplotlib.pyplot as plt
import geopandas as gpd
from rasterio.plot import show
from rasterio.crs import CRS
from datetime import datetime as dt
from datetime import date
""" VARIABLES - MUST UPDATE THESE VALUES """
# Point file, raster file, name of the variable in the raster
point_file='test_points.gpkg'
raster_file='temp_2018_2025_sl.grib'
varname='temp' # 'temp' or 'precip'
# Column names in point file that contain: unique ID, name, and date
obnum='OBS_NUM'
obname='OBS_NAME'
obdate='OBS_DATE'
#The first period in the ERA data write as YYYY-MM
startdate='2018-01' # YYYY-MM
# True means dates in point file are YYYY-MM-DD, False means DD-MM-YYYY
standard_date=False # True or False
I wrote a function to convert the units of the raster’s temperature (Kelvin to Celsius) and precipitation (meters to millimeters) values. We establish all the paths for reading and writing files, and read the point file into a Geopandas geodataframe (see my earlier post for a basic Geopandas introduction). If the column with the unique identifier is not unique, we bail out of the program. We do likewise if the variable name is incorrect.
""" MAIN PROGRAM """
def convert_units(varname,value):
# Convert temperature from Kelvin to Celsius
if varname=='temp':
newval=value-272.15
# Convert precipitation from meters to millimeters
elif varname=='precip':
newval=value*1000
else:
newval=value
return newval
# Estabish paths, read files
yearmonth=np.datetime64(startdate)
point_path=os.path.join('input',point_file)
raster_path=os.path.join('input',raster_file)
outfolder='output'
if not os.path.exists(outfolder):
os.makedirs(outfolder)
point_data = gpd.read_file(point_path)
# Conditions for exiting the program
if point_data[obnum].is_unique is True:
pass
else:
print('\n FAIL: unique ID column in the input file contains duplicate values, cannot proceed.')
sys.exit()
if varname in ('temp','precip'):
pass
else:
print('\n FAIL: variable name must be set to either "temp" or "precip"')
sys.exit()
We’re going to use Rasterio to pull the climate value from the raster row and column that each point intersects. Since each band has an identical structure, we only need to find the matching row and column once, and then we can apply it for each band. We create a dictionary to hold our results, open the raster, and iterate through the points, getting the X and Y coordinates from each point and using them to look up the row and column. We add a record to our result dictionary, where the key is the unique ID of the point, and the value is another dictionary with several key / value pairs (observation name, observation date, raster row, and raster column).
# Dictionary holds results, key is unique ID from point file, value is
# another dictionary with column and observation names as keys
result_dict={}
# Identify and save the raster row and column for each point
with rasterio.open(raster_path,'r+') as raster:
raster.crs = CRS.from_epsg(4326)
for idx in point_data.index:
xcoord=point_data['geometry'][idx].x
ycoord=point_data['geometry'][idx].y
row, col = raster.index(xcoord,ycoord)
result_dict[point_data[obnum][idx]]={
obname:point_data[obname][idx],
obdate:point_data[obdate][idx],
'RASTER_ROW':row,
'RASTER_COL':col}
Now, we can open the raster and iterate through each band. For each band, we loop through the keys (the points) in the results dictionary and get the raster row and column number. If the row or column falls outside the raster’s bounds (i.e. the point is not in our study area), we save the year/month climate value as None. Otherwise, we obtain the climate value for that year/month (remember we hardcoded our start date at the top of the script), convert the units and save it. The year/month becomes the key with the prefix ‘YM-‘, so YM-2019-01 (this data will ultimately be stored in a table, and best practice dictates that column names should be strings and should not begin with integers). Before we move to the next band, we update our year / month value by 1 so we can proceed to the next one; Python’s timedelta function allows us to do math on dates, so if we add 1 month to 2019-12 the result is 2020-01.
# Iterate through raster bands, extract the climate value,
# store in column named for Year-Month, handle points outside the raster
with rasterio.open(raster_path,'r+') as raster:
raster.crs = CRS.from_epsg(4326)
for band_index in range(1, raster.count + 1):
for k,v in result_dict.items():
rrow=v['RASTER_ROW']
rcol=v['RASTER_COL']
if any ([rrow < 0, rrow >= raster.height,
rcol < 0, rcol >= raster.width]):
result_dict[k]['YM-'+str(yearmonth)]=None
else:
climval=raster.read(band_index)[rrow,rcol]
climval_new=round(convert_units(varname,climval.item()),4)
result_dict[k]['YM-'+str(yearmonth)]=climval_new
yearmonth=yearmonth+np.timedelta64(1, 'M')
The next block identifies the year/month that matches the date for each point, and saves that value in a dedicated column. We identify whether we are using a standard date or not (specified at the top of the script). If it was not standard (DD-MM-YYYY), we convert it to standard (YYYY-MM-DD). We use the datetime function to get just the year / month from the observation date, so we can look it up in our results dictionary and pull the matching value. If our observation date falls outside the range of our raster data, we record None.
# Iterate through results, find matching climate value for the
# observation date in the point file, handle dates outside the raster
for k,v in result_dict.items():
if standard_date is False: # handles dd-mm-yyyy dates
formatdate=dt.strptime(v[obdate].strip(),'%m/%d/%Y').date()
numdate=np.datetime64(formatdate)
else:
numdate=v[obdate] # handles yyyy-mm-dd dates
obyrmonth='YM-'+np.datetime_as_string(numdate, unit='M').item()
if obyrmonth in v:
matchdate=v[obyrmonth]
else:
matchdate=None
result_dict[k]['MATCH_VALUE']=matchdate
Here’s a sample of the first record in the results dictionary:
{0:
{'OBS_NAME': 'alfa',
'OBS_DATE': '1/1/2019',
'RASTER_ROW': 9,
'RASTER_COL': 7,
'YM-2018-01': 28.4781,
'YM-2018-02': 29.6963,
'YM-2018-03': 28.9622,
...
'YM-2025-12': 26.6185,
'MATCH_VALUE': 28.7401},
}
The last bit writes our output. We want to use the keys in our dictionary as our header row, but they are repeated for every point and we only need them once. So we pull the first entry out of the dictionary and convert its keys to a list, and then insert the name of the observation variable as the first list element (since it doesn’t appear in our dictionary). Then we proceed to flatten our dictionary out to a list, with one record for each point. We do a quick plot of the points and the first band (just for show), and use the CSV module to write the data out. We name the output file using the variable’s name (provided at the beginning) and today’s date.
# Converts dictionary to list for output
firstkey=next(iter(result_dict))
header=list(result_dict[firstkey].keys())
header.insert(0,obnum)
result_list=[header]
for k,v in result_dict.items():
record=[k]
for k2, v2 in v.items():
record.append(v2)
result_list.append(record)
# Plot the points over the first raster that was processed to see visual
with rasterio.open(raster_path,'r+') as raster:
raster.crs = CRS.from_epsg(4326)
fig, ax = plt.subplots(figsize=(12,12))
point_data.plot(ax=ax, color='black')
show((raster,1), ax=ax)
# Output results to CSV file
today=str(date.today())
outfile=varname+'_'+today+'.csv'
outpath=os.path.join(outfolder,outfile)
with open(outpath, 'w', newline='') as writefile:
writer=csv.writer(writefile, quoting=csv.QUOTE_MINIMAL, delimiter=',')
writer.writerows(result_list)
count_r=len(result_list)
count_c=len(result_list[0])
print('\n Done, wrote {} rows with {} values for {} data to {}'.format(count_r,count_c,varname,outpath))
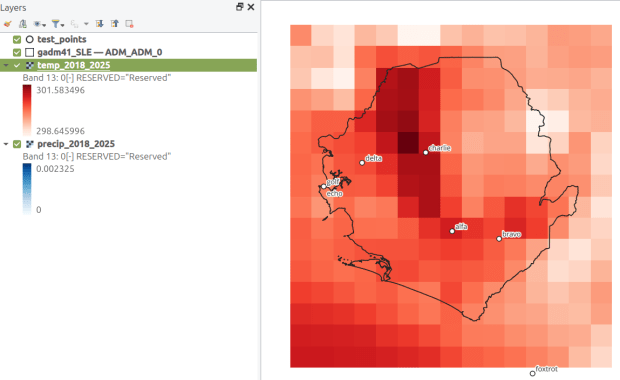
This gives us temperature; the next step would be to modify the variables at the top of the script to read in and process the precipitation raster. Geospatial python makes it super easy to automate these tasks and perform them quickly. My use of desktop GIS was limited to examining the GRIB file at the beginning so I could understand how it was structured, and creating a visualization at the end so I could verify my results (see the QGIS screenshot in the header of this post).
I’m fortunate to be on sabbatical for much of this summer, and am working on a project where I’m measuring the effectiveness of comparing census American Community Survey estimates over time. I’ve written a lot of Python code over the past six weeks, and thought I’d share some general tips for working with bigger datasets.
For my project, I’m looking at 317 variables stored in 25 tables for over 406,000 individual geographic areas; approximately 129.5 million data points. Multiply that by two, as I’m comparing two time periods. While this wouldn’t fall into the realm of what data scientists would consider as ‘big data’, it is big enough that you have to think strategically about how handle it, so you don’t run out of memory or have to wait hours while tasks grind away. While you could take advantage of parallel processing, or find access to a high performance computer, with this amount of data you can stick with a decent laptop, if you take steps to ensure that it doesn’t go kaput.
While the following suggestions may seem obvious to experienced programmers, it should be helpful to novices. I work with a lot of students whose exposure to Python programming is using Google Colab with Pandas. While that’s a fine place to start, the basic approaches you learn in an intro course will fall flat once you start working with datasets that are this big.
Don’t use a notebook. Ipython notebooks like Jupyter or Colab are popular, and are great for doing iterative analysis, visualization, and annotation of your work. But they run via web browsers which introduce extra overhead memory-wise. Iterative notebooks are unnecessary if you’re processing lots of data and don’t need to see step by step results. Use a traditional development environment instead (Spyder is my favorite – see the pic in this post’s header).
Don’t rely so much on Pandas DataFrames. They offer convenience as you can explicitly reference rows and columns, and reading and writing data to and from files is straightforward. But DataFrames can hog memory, and processing them can be inefficient (depending on what you’re doing). Instead of loading all your data from a file into a frame, and then making a copy of it where you filter out records you don’t need, it’s more efficient to read a file line by line and omit records while reading. Appending records to a DataFrame one at a time is terribly slow. Instead, use Python’s basic CSV module for reading and append records to nested lists. When you reach the point where a DataFrame would be easier for subsequent steps, you can convert the nested list to a frame. The basic Python data structures – lists, dictionaries, and sets – give you a lot of power at less cost. Novices would benefit from learning how to use these structures effectively, rather than relying on DataFrames for everything. Case in point: after loading a csv file with 406,000 records and 49 columns into a Pandas DataFrame, the frame consumed 240 MB of memory. Loading that same file with the csv module into a nested list, the list consumed about 3 MB.
Reads a file, skips the header row, adds a key / value pair to a dictionary for each row using the first and second value (assuming the key value is unique).
import os, csv
keep_ids={}
with open(recskeep_file,'r') as csv_file:
reader=csv.reader(csv_file,delimiter='\t')
next(reader)
for row in reader:
keep_ids[row[0]]=row[1]
Or, save all the records as a list in a nested list, while keeping the header row in a separate list.
records=[]
with open(recskeep_file,'r') as csv_file:
reader=csv.reader(csv_file,delimiter='\t')
header=next(reader)
for row in reader:
records.append(row)]
Delete big variables when you’re done with them. The files I was reading were segmented in twos: one file for estimates, and one for margins of error for those same estimates. I read each into separate, nested lists while filtering for records I wanted. I had to associate each set with a header row, filter by columns, and then join the two together. Arguably that part was easier to do with DataFrames, so at that stage I read both into separate frames, filtered by column, and joined the two. Once I had the joined frame as a distinct copy, I deleted the two individual frames to save memory.
Take out the garbage. Python automatically frees up memory when it can, but you can force the issue by emptying deleted objects from memory by calling the garbage collection module. After I deleted the two DataFrames in the previous step, I explicitly called gc.collect() to free up the space.
...
del est_df
del moe_df
gc.collect()
Write as you read. There’s no way I could read all my data in and hold it in memory before writing it all out. Instead I had to iterate – in my case the data is segmented by data tables, which were logical collections of variables. After I read and processed one table, I wrote it out as a file, then moved on to the next one. The variable that held the table was overwritten each time by the next table, and never grew in size beyond the table I was actively processing.
Take a break. You can use the sleep module to build in brief pauses between big operations. This can give your program time to “catch up”, finishing one task and freeing up some juice before proceeding to the next one.
time.sleep(3)
Write several small scripts, not one big one. The process for reading, processing, and writing my files was going to be one of the longer processes that I had to run. It’s also one that I’d likely not have to repeat if all went well. In contrast, there were subsequent analytical tasks that I knew would require a lot of back and forth, and revision. So I wrote several scripts to handle individual parts of the process, to avoid having to repeat a lot of long, unnecessary tasks.
Lean on a database for heavy stuff. Relational databases can handle large, structured data more efficiently compared to scripts reading data from text files. I installed PostgreSQL on my laptop to operate as a localhost database server. After I created my filtered, processed CSV files, I wrote a second program that loaded them into the database using Psycopg2, a Python module that interacts with PostgreSQL (this is a good tutorial that demonstrates how it works). SQL statements can be long, but you can use Python to iteratively write the statements for you, by building strings and filling placeholders in with the format method. This gives you two options. Option 1, you execute the SQL statements from within Python. This is what I did when I loaded my processed CSV files; I used Python to iterate and read the files into memory, wrote CREATE TABLE and INSERT statements in the script, and then inserted the data from Python’s data structures into the database. Option 2, is you can use Python to write a SQL transaction statement, save the transaction as a SQL text file, and then load it in the database and run it. I followed this approach later in my process, where I had to iterate through two sets of 25 tables for each year, and perform calculations to create a host of new variables. It was much quicker to do these operations within the database rather than have Python do them, and executing the SQL script as a separate process made it easier for me to debug problems.
Connect to a database, save SQL statement as a string, loops through a list of variables IDs, and for each variable format the string by passing the values in as parameters, execute the statement and fetch the result – fetchone() in this case, but could also fetchmany():
# Database connection parameters
pgdb='acs_timeseries'
pguser='postgres'
pgpswd='password'
pgport='5432'
pghost='localhost'
pgschema='public'
conpg = psycopg2.connect(database=pgdb, user=pguser, password=pgpswd,
host=pghost, port=pgport)
curpg=conpg.cursor()
sql_varname="SELECT var_lbl from acs{}_variables_mod WHERE var_id='{}'"
year='2019'
for v in varids:
# Get labels associated with variables
qvarname=sql_varname.format(year, v)
curpg.execute(qvarname)
vname=curpg.fetchone()[0]
... #do stuff...
curpg.close()
When using Psycopg2, don’t use the executemany() function. When performing an INSERT statement, you can have the module executeone() statement at a time, or executemany(). But the latter was excruciatingly slow – in my case it ran overnight before it finished. Instead I found this trick called mogrify, where you convert your INSERT arguments into one enormous string, and pass that to the mogrify() function. This was lightning fast, but because the text string is massive I ran out of memory if my tables were too big. My solution was to split tables in half if the number of columns exceeded a certain number, and pass them in one after the other.
Use the database and script for what they do best. Once I finished my processing, I was ready to begin analyzing. I needed to do several different cross-tabulations on the entire dataset, which was segmented into 25 tables. PostgreSQL is able to summarize data quickly, but it would be cumbersome to union all these tables together, and calculating percent totals in SQL for groups of data is a pain. Python with Pandas would be much better at the latter, but there’s no way I could load a giant flat file of my data into Python to use as the basis for all my summaries. So, I figured out the minimal level of grouping that I would need to do, which would still allow me to run summaries on the output for different combinations of groups (i.e. in total and by types of geography, tables, types of variables, and by variables). I used Python to write and execute GROUP BY statements in the database, iterating over each table and appending the result to a nested list, where one record represented a summary count for a variable by table and geography type. This gave me a manageable number of records. Since the GROUP BY operation took some time, I did that in one script to produce output files. Creating different summaries and reports was a more iterative process that required many revisions, but was quick to execute, so I performed those operations in a subsequent script.
Instead of 386 mil records for (406k geographies * 317 variables * 3 categories), about 18k summary counts for 19 groups of geography
Lastly, while writing and perfecting your script, run it against a sample of your data and not the entire dataset! This will save you time and needless frustration. If I have to iterate through hundreds of files, I’ll begin by creating a list that has a couple of file names in it and iterate over those. If I have a giant nested list of records to loop through, I’ll take a slice and just go through the first ten. Once I’m confident that all is well, then I’ll go back and make changes to execute the program on everything.
In my previous post, I summarized several efforts to rescue and preserve US federal government datasets that are being removed from the internet. In this post, I’ll provide a basic primer on screen scraping with Python, which is what I’ve used to capture datasets in participating in the Data Rescue Project. Screen scraping can employed to many ends, such as capturing text on web pages so it can be analyzed, or taking statistics embedded in HTML tables and saving them in machine readable formats. In the context of this post, screen scraping is an approach for downloading data and documentation files stored on websites.
There are several benefits to using a scripting approach for this work. It saves you from the tedious task of clicking and downloading files one by one. The script serves as documentation for what you did, and allows you to easily repeat the process in the future, if the datasets continue to exist and are updated. A scripted, screen-scraping approach may not be best or necessary if the website and datasets are relatively small and simple, or conversely if the site is complicated and difficult to scrape given the technology it employs. In both cases, manual downloading may be quicker, especially with a team of volunteers. Furthermore, if it seems clear that the dataset or website are not going to be updated, or are going to vanish, then the benefit of repeating the process in the future is moot.
In this example, we’ll assume that screen scraping is the way to go, and we’ll use Python to do it. I’ll address a few alternatives to this approach at the end, the primary one being using an API if and when it’s available, and will share links to working code that colleagues and I have written to save datasets.
You should only apply these approaches to public, open data. Capturing restricted or proprietary information violates licenses, terms of service, and in some cases privacy constraints, and is not condoned by any of the rescue projects. Even if the data is public, bear in mind that scraping can put undue pressure on web servers. For large websites, plan accordingly by building pauses into the process, breaking up the work into segments, or running programs at non-peak times (overnight). When writing and testing scripts, don’t repeat the process over and over again on the entire website; run your tests on samples until you get everything working.
Screen Scraping Basics
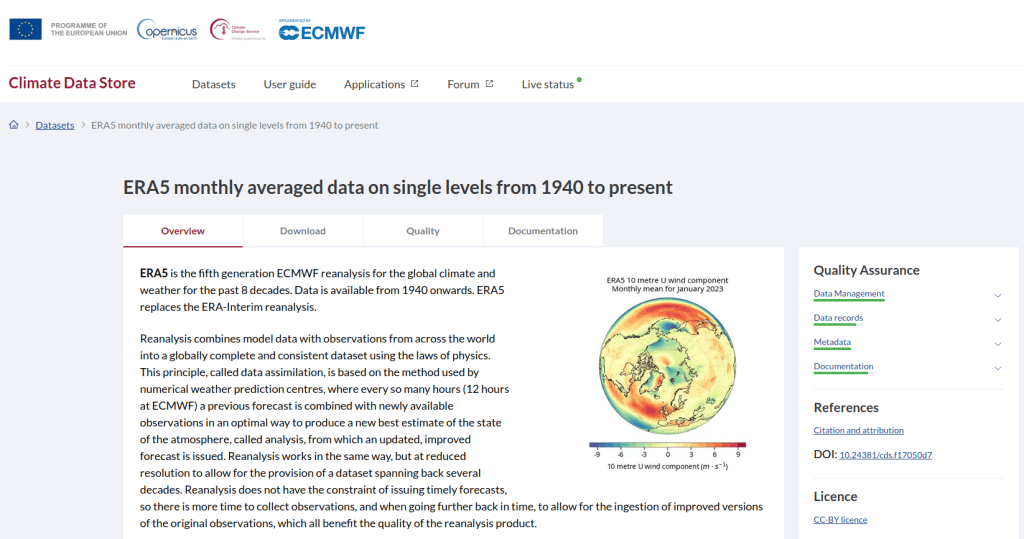
The first step is to explore the website where the data is hosted, to identify the best pages to use as a source and determine the feasibility of the approach. Many websites will have feature rich, user friendly pages that make it easy to view extracts of data and visualize it, such as the NOAA climate website below.
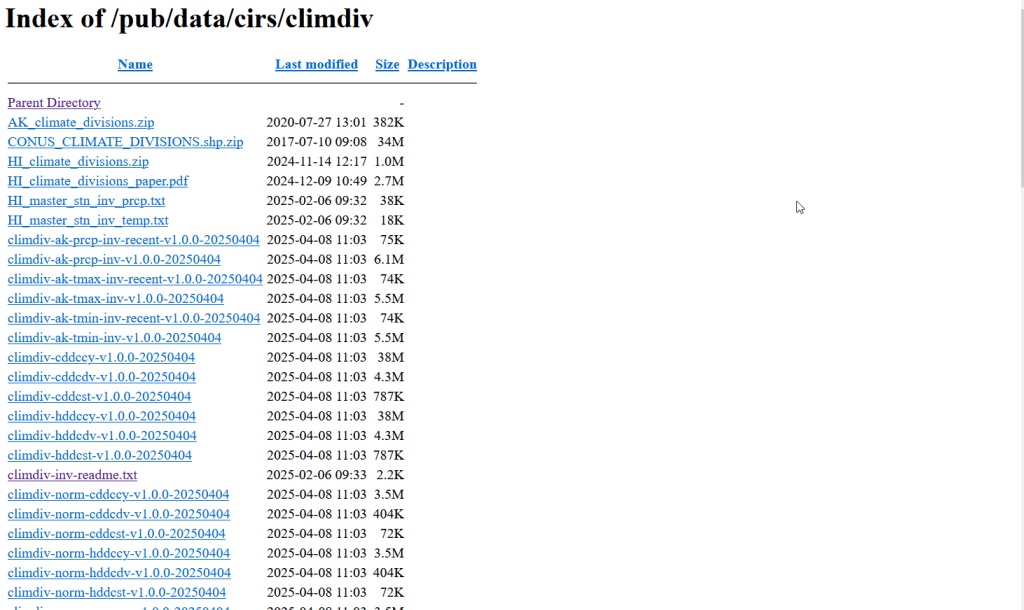
While easy to use, these pages can be complex and tedious to scrape. Always look for an option for bulk downloading datasets. They may lead you to a page sitting behind the scenes of the fancy website, such as the NOAA file directory below. Saving data from a page like this is fairly straightforward.
For the benefit of those of you who are not 1990s era people like myself and may not be familiar with working with HTML, the example below illustrates a simple webpage. With any browser, you can right click on a page and View the Source, to see the HTML code and stylesheets behind the page, which the browser processes and renders to display the site. HTML is a markup language where text is enclosed in tags that tell us something about the content within the tags, and which can be used for displaying the content in different ways. HTML is also hierarchical, so that content can be nested. For example, there is a head section that contains preliminary content about the page, and a body section that encloses the main content. Within the body there can be divisions, and anchor tags that represent links. In this example, one of these anchors is a link to a data file that we want to download.
We can use Python to parse these tags and pull out desired content. There are four core modules I always use: Requests for downloading content, os for creating folders and working with paths, Beautiful Soup for screen scraping, and datetime for creating time stamps. In the code below, we begin by importing the modules and saving the url of the page we wish to scrape as a variable.
In most Python environments (unless you’ve modified some settings) it’s assumed that your current working directory is the folder where your Python script is stored. When you download files, they will automatically be stored in that folder. To keep things tidy, I always create a subfolder named with the date; I use the date function from datetime to retrieve today’s date, append that date to the word “downloaded-‘, and use the os module to create a subfolder with that name. If we run the program at a later date it will save everything in a new folder, rather than overwriting existing files.
import requests, os
from bs4 import BeautifulSoup as soup
from datetime import date
url='https://www.page.gov'
today = str(date.today())
outfolder='downloaded-'+today
if not os.path.exists(outfolder):
os.makedirs(outfolder)
webpage=requests.get(url).content
soup_page=soup(webpage,'html.parser')
page_title = soup_page.title.text
container=soup_page.find('div',{'class':'content'})
links=container.findAll('a')
The final block in this example captures data from the website. We use requests to get the content stored at the url (the webpage), and then we pass this to Beautiful Soup, which parses all the HTML using their tags. Once parsed, we can retrieve specific objects. For example, we can save the page title (the text that appears in the heading of your browser for a particular site) as a variable. We also grab the section of the page that contains the links we want to capture by looking for a specific div or id tag. This isn’t strictly necessary for simple pages like this one, but speeds up processing for larger, more complex pages. Lastly, we can search through that specific container to find all the anchor tags, or links.
Once we have the links, we loop through and save the ones we want. My preference is to store them in a dictionary as key / value pairs, where the key is the name of the file, and the value is the file’s URL. We iterate through the links we saved, and with the soup we determine if the link has an ‘href’ attribute. If it does, we see if it ends with .zip, which is the data file. This skips any link that’s not a file we want, including links that go to other webpages as opposed to files. In practice, I provide a list of several file types here such as .zip, .csv, .txt, .xlsx, .pdf, etc to capture anything that could be data or documentation. If we find the zip, we split the link’s attributes from one string of text into a list of strings that are separated by the backslash, and grab the last element, which is the name of the file. Lastly, we add this to our datalinks dictionary; in this example, we’d have: {'data.zip':'https://www.page.gov/data.zip'}.
datalinks={}
for lnk in links:
if 'href' in lnk.attrs:
if lnk.attrs['href'].endswith(('.zip')):
fname=lnk.attrs['href'].split('/')[-1]
datalinks[fname]=lnk.attrs['href']
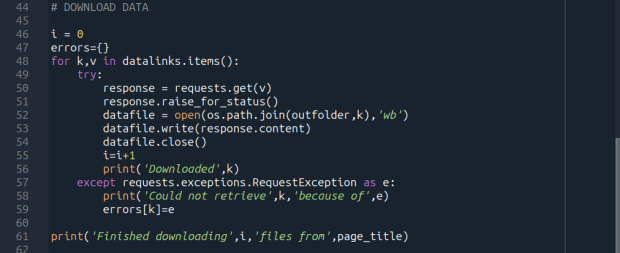
Time to download! We loop through each key (file name) and value (url) in our dictionary. We use the requests module to try and get the url (v), but if there’s a problem with the website or the link is invalid we bail out. If successful, we use the os module to go to our output folder and we supply the name of the file from the website (k) as the name of the file that we want to store on our computer. The ‘wb’ parameter specifies that we’re writing bytes to a file. I always like to keep count of the number of files I’ve done with an iterator (i) so I can print messages to a screen or a log file.
i = 0
for k,v in datalinks.items():
try:
response=requests.get(v)
response.raise_for_status()
dfile=open(os.path.join(outfolder,k),'wb')
dfile.write(response.content)
dfile.close()
i=i+1
print('Downloaded',k)
except requests.exceptions.RequestException as e:
print('Could not get',k,'because of',e)
print('Downloaded',i,'files from',page_title)
It’s important to save documentation too, so people can understand how the data was created and structured. In addition to saving pdf and text files, you can also save a vanilla copy of the website; I use a generic name with a date stamp. This saves the basic HTML text of the page, but not any images, documents, or styling. Which is usually good enough for providing documentation.
As mentioned previously, you don’t want to place undue burden on the webserver. With the time module, you can use the sleep function and add a pause to your script for a fixed amount of time, usually at the end of a loop, or after your iterator has recorded a certain number of files. The random module allows you to supply a random time value within a range, if you want to vary the length of the pause.
import time
from random import randint
# Pause fixed amount
time.sleep(5)
# Pause random amount within a range
time.sleep(randint(10,20))
Screen Scraping Caveats
Those are the basics! Now here are the primary exceptions. The first problem is that links to files may not be absolute links that contain the entire path to a file. Sometimes they’re relative, containing a reference to just the subfolder and file. The requests module won’t be able to find these, so we have to take the extra step of building the full path, as in the example below. You can do this by identifying what the relative path starts with (unless they’re all relative and the same), and you create the absolute by adding (concatenating) the root url and the relative one contained in the soup.
<div class='content'>
<p>Paragraph with text.</p>
<a href='/us/data.zip'/>
</div>
url='https://www.page.gov'
datalinks={}
for lnk in links:
if lnk.attrs['href'].endswith(('.zip')):
if lnk.attrs['href'].startswith('/us/'):
fname=lnk.attrs['href'].split('/')[-1]
datalinks[fname]=url+lnk.attrs['href']
...
In other cases, a link to a data file may not lead directly to the file, but leads to another web page where that file is stored. We can embed another scraping block into a loop; retrieve and start scraping the main page, then once you find a link go to that page, and repeat retrieval and scraping. In these cases, it’s best to save these steps in a function, so you can call the function multiple times instead of repeating the same code.
<div class='content'>
<p>Paragraph with text.</p>
<a href='https://www.page.gov/us/'>
</div>
Some websites will have dedicated pages where they embed a parameter in the url, such as codes for countries or states. If you know what these are, you can define them in a list, and iterate through that list by formatting the url to insert the code, and then scrape that page. If a page uses a unique integer as an ID and you know what the upper limit is, you can use for i in range(1,n) to step through each page (but make sure you handle exceptions, in case an integer isn’t used or is missing).
codes=['us','ca','mx']
url='https://www.page.gov/{}'
for c in codes:
webpage=requests.get(url.format(c)).content
soup_page=soup(webpage,'html.parser')
...
For complicated sites with several pages, you might not want to dump all the files into the same folder. Instead, as you iterate through pages, you can create a dedicated folder for that iteration. Using the example above, if there is a page for each country code, you can create a folder for that code and when writing files, use the path module to store files in that folder for that iteration.
codes=['us','ca','mx']
for c in codes:
...
cfolder=os.path.join(outfolder,c)
if not os.path.exists(cfolder):
os.makedirs(cfolder)
...
response=requests.get(v)
response.raise_for_status()
dfile=open(os.path.join(cfolder,k),'wb')
dfile.write(response.content)
dfile.close()
For websites with lots of files, or with a few big files, you may run out of memory during the download process and your script will go kaput. To avoid this, you can stream a file in chunks instead of trying to download it in one go. Use the request module’s iter_content function, and supply a reasonable chunk size in bytes (10000000 bytes is 10 MB).
...
try:
with requests.get(v,stream=True) as response:
response.raise_for_status()
fpath=os.path.join(outfolder,k)
with open(fpath,'wb') as writefile:
for chunk in response.iter_content(chunk_size=10000000):
writefile.write(chunk)
i=i+1
print('Downloaded',k)
except requests.exceptions.RequestException as e:
print('Could not get',fname,'because of',e)
If you view the page source for a website, and don’t actually see the anchor links and file names in the HTML, you’re probably dealing with a page that employs JavaScript, which is a show stopper if you’re using Beautiful Soup. There may be a dropdown menu or option you have to choose first, in order to render the actual page (and you may be able to use the page parameters trick above, if the url on each page varies). But you may be stuck; instead of links, there may be download buttons you have to press or a dropdown menu option you have to choose in order to download the file.
One option would be to use a Python module called Selenium, which allows you to automate the process of using a web browser, to open a page, find a button, and click it. I’ve tried Selenium with some success, but find that it’s complex and clunky for screen scraping. It’s browser dependent (you’re automating the use of a browser, and they’re all different), and you’re forced to incorporate lots of pauses; waiting for a page to load before attempting to parse it, and dealing with pop up menus in the browser as you attempt to download multiple files, etc.
Another option that I’m not familiar with, and thus haven’t tried, would be to use JavaScript since that’s what the page uses. Most browsers have web developer console add-ons that allow you to execute snippets of JavaScript code in order to do something on a page. So some automation may be possible.
Using an API
You may be able to avoid scraping altogether if the data is made available via an API. With a REST API, you pass parameters into a base link to make a specific request. Using requests, you go to that URL, and instead of getting a web page you get the data that you’ve asked for, usually packaged in a JSON type object within your program (Python or another scripting language). Some APIs retrieve documents or dataset files, that you can stream and download as described previously. But most APIs for statistical data retrieve individual data records, which you would store in a nested list or dictionary and then write out to a CSV. The example below grabs the total population for four large cities in Rhode Island from 2020 decennial census public redistricting dataset.
import requests,csv
year='2020'
dsource='dec' # survey
dseries='pl' # dataset
cols='NAME,P1_001N' # variables
state='44' # geocodes for states
place='19180,54640,59000,74300' # geocodes for places
outfile='census_pop2020.csv'
keyfile='census_key.txt'
with open(keyfile) as key:
api_key=key.read().strip()
base_url = f'https://api.census.gov/data/{year}/{dsource}/{dseries}'
# for sub-geography within larger geography - geographies must nest
data_url = f'{base_url}?get={cols}&for=place:{place}&in=state:{state}&key={api_key}'
response=requests.get(data_url)
popdata=response.json()
for record in popdata:
print(record)
with open(outfile, 'w', newline='') as writefile:
writer=csv.writer(writefile, quoting=csv.QUOTE_MINIMAL, delimiter=',')
writer.writerows(popdata)
The benefit of an API is that it’s designed to retrieve machine readable data, and might be easier than scraping pages that have complex interfaces. The major downside is, if you’re forced to download individual records as opposed to entire files, the process can take a long time, to the point where it may be infeasible if the datasets are too large. It’s always worth checking to see if there is a bulk download option as that could be easier and more efficient (for example, the Census Bureau has an FTP site for downloading datasets in their entirety). Using an API also requires you to invest time in studying how it works, so you can build the appropriate links and ensure that you’re capturing everything.
Conclusion
Screen scraping will vary from website to website, but once you have enough examples it becomes easy to resample your code. You’ll always need to modify the Beautiful Soup step based on the structure of the individual pages, but the requests downloading step is more rote and may not require much modification. While I use Python, you can use other languages like R to achieve similar results.
Visit my library’s US Federal Government Data Backup GitHub for working examples of code that I and colleagues have used to capture datasets. In my programs I’ve added extra components, like writing a basic metadata file and error logs, which I haven’t covered in this post. The NOAA County at a Glance, IRS-SOI, and IMLS, scripts are basic examples, and the IMLS ones include some of the caveats I’ve described. The NOAA lake and sea level rise scripts are far more complex, and include cycling through many pages, creating multiple folders, streaming downloads, and encapsulating processes into functions. The USAID DHS Indicators scripts used APIs that retrieved files, while the USAID DHS SDR script used Selenium to step through a series of JavaScript pages.
You’ll find scripts but no datasets in the GitHub repo due to file size limitations. If you’re a member of an institution that has access to GLOBUS, you can access the data files by following the instructions at the top of the page. Otherwise, we’ve contributed all of our datasets to DataLumos (except for the sea level rise data, I’m working with another university to host that).
Last semester we completed a project to create a crosswalk between census geographies and local geographies in Providence, RI. Crosswalks are used for relating two disparate sets of geography, so that you can compile data that’s published for one set of geography in another. Many cities have locally-defined jurisdictions like wards or community districts, as well as informally defined areas like neighborhoods. When you’re working with US Census data, you use small statistical areas that the Bureau defines and publishes data for; blocks, block groups, census tracts, and perhaps ZCTAs and PUMAs. A crosswalk allows you to apportion data that’s published for census areas, to create estimates for local areas (there are also crosswalks that are used for relating census geography that changes over time, such as the IPUMS crosswalks).
How the Crosswalk Works
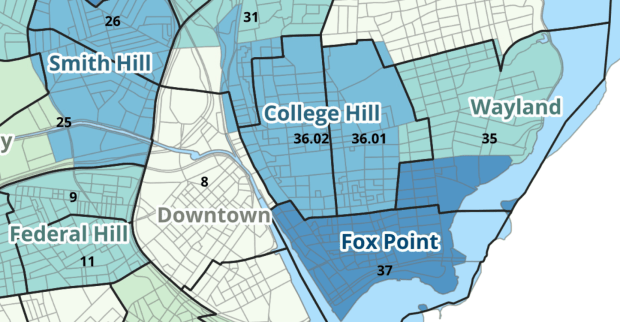
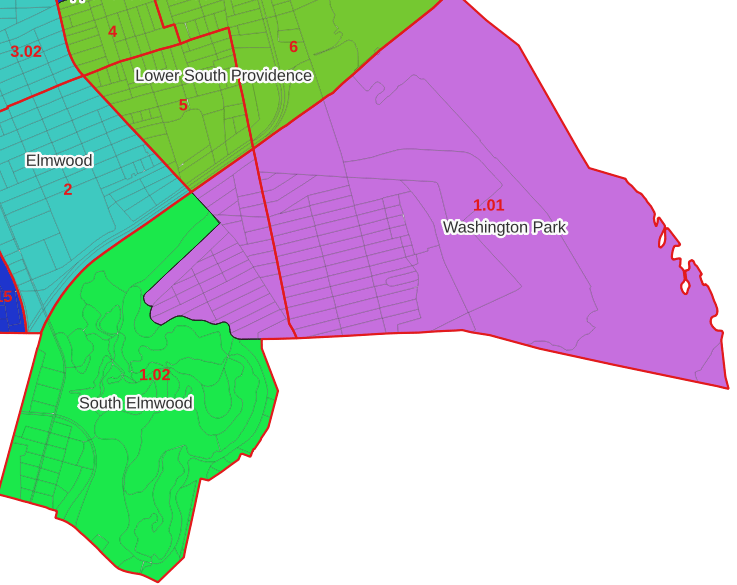
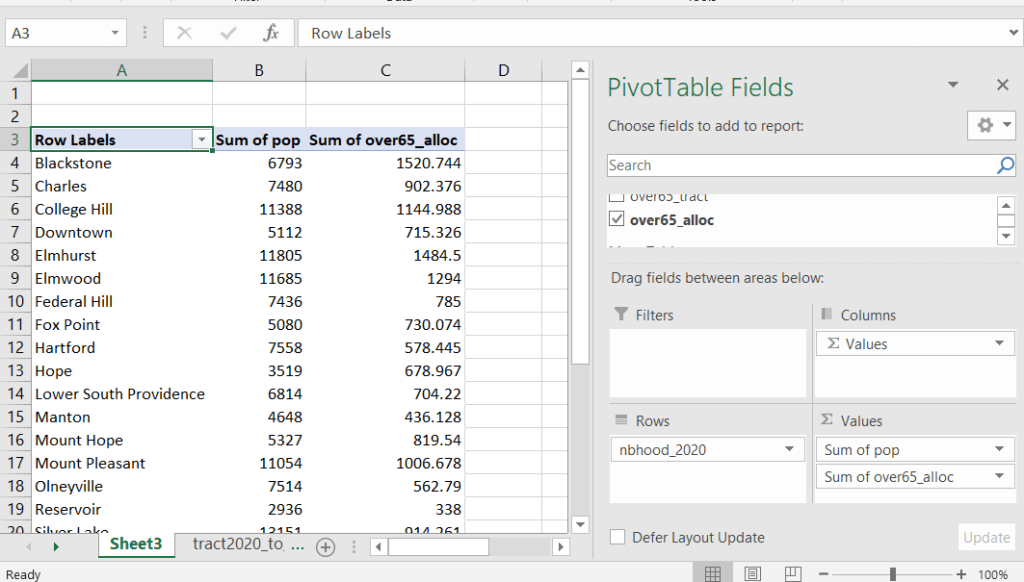
For example, in the Providence Census Geography Crosswalk we have two crosswalks that allow you to take census tract data, and convert it to either neighborhoods or wards. I’ll refer to the neighborhoods in this post. In the crosswalk table, there is one record for each portion of a tract that overlaps a neighborhood. For each record, there are attribute columns that indicate the count and the percentage of a tract’s population, housing units, land area, and total area that fall within a given neighborhood. If a tract appears just once in the table, that means it is located entirely within one neighborhood. In the image below, we see that tract 1.01 appears in the table once, and its population percentage is 1. That means that it falls entirely within the Washington Park neighborhood, and 100% of its population is in that neighborhood. In contrast, tract 1.02 appears in the table twice, which means it’s split between two neighborhoods. Its pct_pop column indicates that 31.5% of its population is in South Elmwood, while 68.5% is in Washington Park. The population count represents the number of people from that tract that are in that neighborhood.
Looking at the map below, we can see that census tract 1.01 falls entirely within Washington Park, and tract 1.02 is split between Washington Park and South Elmwood. To generate estimates for Washington Park, we would sum data for tract 1.01 and the portion of tract 1.02 that falls within it. Estimates for South Elmwood would be based solely on the portion of tract 1.02 that falls within it. With the crosswalk, “portion” can be defined as the percentage of the tract’s population, housing units, land area, or total area that falls within a neighborhood.
The primary purpose of the crosswalk is to generate census data estimates for neighborhoods. You apportion tract data to neighborhoods using an allocation factor (population, housing units, or area) and aggregate the result. For example, if we have a census tract table from the 2020 census with the population that’s 65 years and older, we can use the crosswalk to generate neighborhood-level estimates of the 65+ population. To do that, we would:
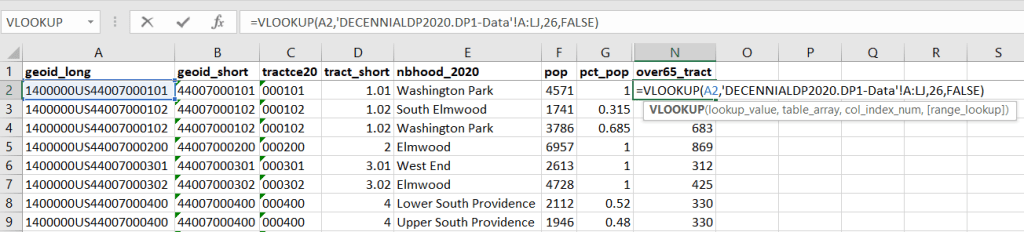
Join the data table to the crosswalk using the tract’s unique ID; the crosswalk has both the long and short form of the GEOIDs used by the Census Bureau. So for each crosswalk record, we would associate the 65+ population for the entire tract with it.
Multiply the 65+ population by one of the allocation columns – the percent population in this example. This would give us an estimate of the 65+ population that live in that tract / neighborhood piece.
Group or aggregate this product by the neighborhood name, to obtain a neighborhood-level table of the 65+ population.
Round decimals to whole numbers.
To do the calculations in a spreadsheet, you would import the appropriate crosswalk sheet into the workbook that contains the census data that you want to apportion, so that they appear as separate sheets in the same workbook. In the crosswalk worksheet, use the VLOOKUP formula and reference the GEOID to “join” the census tract data to the crosswalk. The formula requires: cell containing the ID value you wish to look up, the range of cells in a worksheet that you will search through, the number of the column that contains the value you wish to retrieve (column A is 1, Z is 26, etc.), and the parameter “FALSE” to get an exact match. It is assumed that the look up value in the target table (the matching ID) appears in the first column (A).
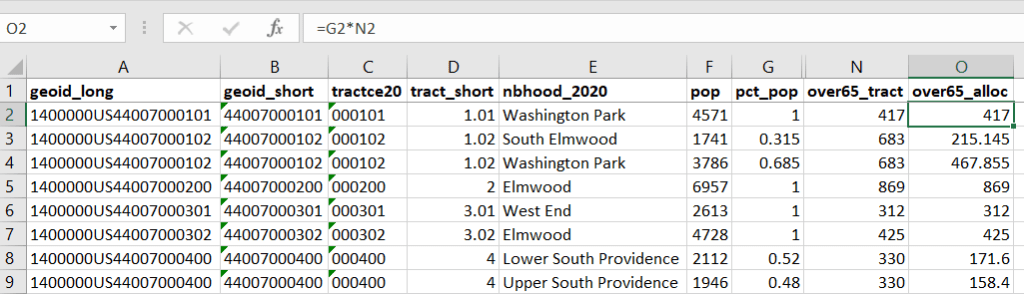
The tract data is now repeated for each tract / neighborhood segment. Next, use formulas to multiply the allocation percentage (pct_pop in this example) by the census data value (over 65 pop for the entire tract) to create an allocated estimate for each tract / neighborhood piece.
Then you can generate a pivot table (on the Insert ribbon in Excel) where you group and sum that allocated result by neighborhood (neighborhoods as rows, census data as summed values in columns). Final step is to round the estimates.
This process is okay for small projects where you have a few estimates you want to quickly tabulate, but it doesn’t scale well. I’d use a relational database instead; import the crosswalk and census data table into SQLite, where you can easily do a left join, calculated field, and then a group by statement. Or, use the joining / calculating / aggregating equivalents in Python or R.
I used the percentage of population as the allocation factor in this example. If the census data you’re apportioning pertains to housing units, you could use the housing units percentage instead. In any case, there is an implicit assumption that the data you are apportioning has the same distribution as the allocation factor. In reality this may not be true; the distribution of children, seniors, homeowners, people in poverty etc. may vary from the total population’s distribution. It’s important to bear in mind that you’re creating an estimate. If you are apportioning American Community Survey data this process gets more complicated, as the ACS statistics are fuzzy estimates. You’d also need to apportion the margin of error (MOE) and create a new MOE for the neighborhood-level estimates.
The Providence crosswalk has some additional sheets that allow you to go from tracts, ZCTAs, or blocks to neighborhoods or wards. The tract crosswalk is by far the most useful. The ZCTA crosswalk was an exercise in futility; I created it to demonstrate the complete lack of correlation between ZCTAs and the other geographies, and recommend against using it (we also produced a series of maps to visually demonstrate the relationship between all the geographies). There is a limited amount of data published at the block level, but I included it in the crosswalk for another reason…
Creating the Crosswalk
I used census blocks to create the crosswalk. They are the smallest unit of census geography, and nest within all other census geographies. I used GIS to assign each block to a neighborhood or ward based on the geography the block fell within, and then aggregated the blocks into distinct tract / ward and tract / neighborhood combinations. Then I calculated the allocation factors, the percentage of the tract’s total attributes that fell in a particular neighborhood or ward. This operation was straightforward for the wards; the city constructed them using 2020 census blocks, so the blocks nested or fit perfectly within the wards.
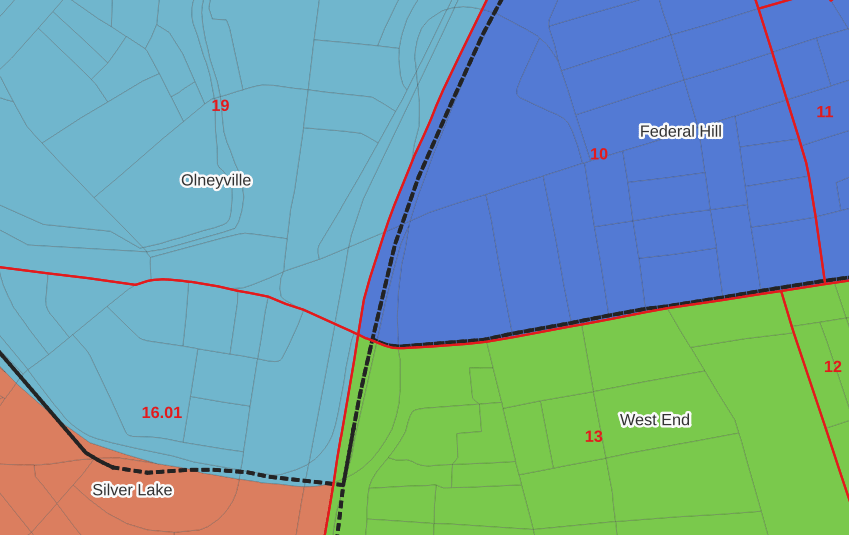
The neighborhoods were more complicated, as these were older boundaries that didn’t correspond to the 2020 blocks, and there were many instances where blocks were split between neighborhoods. My approach was to create a new set of neighborhood boundaries based on the 2020 blocks, and then use those new boundaries to create the crosswalk. I began with a spatial join, assigning each block a neighborhood ID based on where the center of the block fell. Then, I manually inspected the borders between each neighborhood, to determine whether I should manually re-assign a block. In almost all instances, blocks I reassigned were unpopulated and consisted of slivers that contained large highways, or blocks of greenspace or water. I struck a balance between remaining as faithful to the original boundaries as possible, while avoiding the separation of unpopulated blocks from a tract IF the rest of the blocks in that tract fell entirely within one neighborhood. In two cases where I had to assign a populated block, I used satellite imagery to determine that the population of the block lived entirely on one side of a neighborhood boundary, and made the assignment accordingly.
In the example below, 2020 tract boundaries are shown in red, 2020 block boundaries are light grey, original neighborhood boundaries are shown with dotted black lines, and reconstituted neighborhoods using 2020 blocks are shown in different colors. The boundaries of Federal Hill and the West End are shifted west, to incorporate thin unpopulated blocks that contain expressways. These empty blocks are part of tracts (10 and 13) that fall entirely within these neighborhoods; so splitting them off to adjacent Olneyville and Silver Lake didn’t make sense (as there would be no population or homes to apportion). Reassigning them doesn’t change the fact that the true boundary between these neighborhoods is still the expressway. We also see an example between Olneyville and Silver Lake where the old neighborhood boundary was just poorly aligned, and in this case blocks are assigned based on where the center of the block fell.
Creating the crosswalk from the ground up with blocks was the best approach for accounting how population is distributed within larger areas. It was primarily an aggregation-based approach, where I could sum blocks that fell within geographies. This approach allowed me to generate allocation factors for population and housing units, since this data was published with the blocks and could be carried along.
Conversely, in GIS 101 you would learn how to calculate the percentage of an area that falls within another area. You could use that approach to create a tract-level crosswalk based on area, i.e. if a tract’s area is split 50/50 between two neighborhoods, we’ll apportion its population 50/50. While this top down approach is simpler to implement, it’s far less ideal because you often can’t assume that population and area are equally distributed. Reconsider the example we began with: 31.5% of tract 1.02’s population is in South Elmwood, while 68.5% is in Washington Park. In contrast, 75.3% of tract 1.02’s land area is in South Elmwood, versus only 24.7% in Washington Park! If we apportioned our census data by area instead of population, we’d get a dramatically different, and less accurate, result. Roger Williams Park is primarily located in the portion of tract 1.02 that falls within Elmwood; it covers a lot of land but includes zero people.
Why can’t we just simply aggregate block-level census data to neighborhoods and skip the whole apportionment step? The answer is that there isn’t much data published at the block level. There’s a small set of tables that capture basic demographic variables as part of the decennial census, and that’s it. There was a sharp reduction in the number of block-level tables in the 2020 census due to new privacy regulations, and the ACS isn’t published at the block-level at all. While you can use the block-level table in the crosswalk to join and aggregate block data, in most cases you’ll need to work with tract-data and apportion it.
I used spatial SQL to create the crosswalks in Spatialite and QGIS , and if you’re interested in seeing all the gory details you can look at the code and spatial database in source folder of the project’s GitHub repo. I always prefer SQL for spatial join and aggregation operations, as I can write a single block of code instead of running 4 or 5 different of desktop GIS tools in a sequence. I’ll be updating the project this semester to include additional geographies (block groups – the level between blocks and tracts), and perhaps an introductory tutorial for using it (there are some basic docs at present).
Last month I cobbled together bits and pieces of geospatial Python code I’ve written in various scripts into one cohesive example. You can script, automate, and document a lot of GIS operations with Python, and if you use a combination of Pandas, GeoPandas, and Shapely you don’t even need to have desktop GIS software installed (packages like ArcPy and PyQGIS rely on their underlying base software).
I’ve created a GitHub repository that contains sample data, a basic Python script, and a Jupyter Notebook (same code and examples, in two different formats). The script covers these fundamental operations: reading shapefiles into a geodataframe, reading coordinate data into a dataframe and creating geometry, getting coordinate reference system (CRS) information and transforming the CRS of a geodataframe, generating line geometry from groups and sequences of points, measuring length, spatially joining polygons and points to assign the attributes of one to the other, plotting geodataframes to create a basic map, and exporting geodataframes out as shapefiles.
A Pandas dataframe is a Python structure for tabular data that allows you to store and manipulate data in rows and columns. Like a database, Pandas columns are assigned explicit data types (text, integers, decimals, dates, etc). A GeoPandas geodataframe adds a special geometry column for holding and manipulating coordinate data that’s encoded as point, line, or polygon objects (either single or multi). Similar to a spatial database, the geometry column is referenced with standard coordinate reference system definitions, and there are many different spatial functions that you can apply to the geometry. GeoPandas allows you to work with vector GIS datasets; there are wholly different third-party modules for working with rasters (Rasterio for instance – see this post for examples).
First, you’ll likely have to install the packages Pandas, GeoPandas, and Shapely with pip or your distro’s package handler. Then you can import them. The Shapely package is used for building geometry from other geometry. Matplotlib is used for plotting, but isn’t strictly necessary depending on how detailed you want your plots to be (you could simply use Panda’s own plot library).
import os, pandas as pd
import geopandas as gpd
from shapely.geometry import LineString
import matplotlib.pyplot as plt
%matplotlib inline
Reading a shapefile into a geodataframe is a piece of cake with read_file. We use path.join from the os module to build paths that work in any operating system. Reading in a polygon file of Rhode Island counties:
If you have coordinate data in a CSV file, there’s a two step process where you load the coordinates as numbers into a dataframe, and then convert the dataframe and coordinates into a geodataframe with actual point geometry. Pandas / GeoPandas makes assumptions about the column types when you read a CSV, but you have the option to explicitly define them. In this example I define the Census Bureau’s IDs as strings to avoid dropping leading zeros (an annoying and perennial problem). The points_from_xy function takes the longitude and latitude (in that order!) and creates the points; you also have to define what system the coordinates are presently in. This sample data came from the US Census Bureau, so they’re in NAD 83 (EPSG 4269) which is what most federal agencies use. For other modern coordinate data, WGS 84 (EPSG 4326) is usually a safe bet. GeoPandas relies on the EPSG / ESRI CRS library, and familiarity with these codes is a must for working with spatial data.
In the output below, you can see the distinction between the coordinates, stored separately in two numeric columns, and point-based geometry in the geometry column. The sample data consists of eleven point locations, ten in Rhode Island and one in Connecticut, labeled alfa through kilo. Each point is assigned to a group labeled a, b, or c.
You can obtain the CRS metadata for a geodataframe with this simple command:
gdf_cnty.crs
You can also get the bounding box for the geometry:
gdf_cnty.total_bounds
These commands are helpful for determining whether different geodataframes share the same CRS. If they don’t, you can transform the CRS of one to match the other. The geometry in the frames must share the same CRS if you want to interact with the data. In this example, we transform our points from NAD 83 to the RI State Plane zone that the counties are in with to_crs; the EPSG code is 3438.
gdf_pnts.to_crs(3438,inplace=True)
gdf_pnts.crs
If our points represent a sequence of events, we can do a points to lines operation to create paths. In this example our points are ordered in the correct sequence; if this was not the case, we’d sort the frame on a sequence column first. If there are different events or individuals in the table that have an identifying field, we use this as the group field to create distinct lines. We use lambda to repeat Shapely’s LineString function across the points to build the lines, and then assign them to a new geodataframe. Then we add a column where we compute the length of the lines; this RI CRS uses feet for units, so we divide by 5,280 feet to get miles. The Panda’s loc function grabs all the rows and a subset of the columns to display them on the screen (we could save them to a new geodataframe if we wanted to subset rows or columns).
To assign every point the attributes of the polygon (county) that it intersects with , we do a spatial join with the sjoin function. Here we take all attributes from the points frame, and a select number of columns from the polygon frame; we have to take the geometry from both frames to do the join. In this example we do a left join, keeping all the points on the left regardless of whether they have a matching polygon on the right. There’s one point that falls oustide of RI, so it will be assigned null values on the right. We rename a few of the columns, and use loc again to display a subset of them to the screen.
To see what’s going on, we can generate a basic plot to display the polygons, points, and lines. I used matplotlib to create a figure and axes, and then placed each layer one on top of the other. We could opt to simply use Pandas / GeoPandas internal plotting instead as illustrated in this tutorial, which works for basic plots. If we want more flexibility or need additional functions we can call on matplotlib. In this example the default placement for the tick marks (coordinates in the state plane system) was bad, and the only way I could fix them was by rotating the labels, which required matplotlib.
Exporting the results out a shapefiles is also pretty straightforward with to_file. Shapefiles come with many limitations, such as a limit on ten characters for column names. You can opt to export to a variety of other vector formats, such a geopackages or geoJSON.











You must be logged in to post a comment.