
I have written a new report that’s just been released: US Census Data: Concepts and Applications for Supporting Research, was published as the May / June 2022 issue of the American Library Association’s Library and Technology Reports. It’s available for purchase digitally or in hard copy from the ALA from now through next year. It will also be available via EBSCOhost as full text, sometime this month. One year from now, the online version will transition to become a free and open publication available via the tech report archives.
The report was designed to be a concise primer (about 30 pages) for librarians who want to be knowledgeable with assisting researchers and students with finding, accessing, and using public summary census data, or who want to apply it to their own work as administrators or LIS researchers. But I also wrote it in such a way that it’s relevant for anyone who is interested in learning more about the census. In some respects it’s a good distillation of my “greatest hits”, drawing on work from my book, technical census-related blog posts, and earlier research that used census data to study the distribution of public libraries in the United States.
Chapter Outline
- Introduction
- Roles of the Census: in American society, the open data landscape, and library settings
- Census Concepts: geography, subject categories, tables and universes
- Datasets: decennial census, American Community Survey, Population Estimates, Business Establishments
- Accessing Data: data.census.gov, API with python, reports and data summaries
- GIS, historical research, and microdata: covers these topics plus the Current Population Survey
- The Census in Library Applications: overview of the LIS literature on site selection analysis and studying library access and user populations
I’m pleased with how it turned out, and in particular I hope that it will be used by MLIS students in data services and government information courses.
Although… I must express my displeasure with the ALA. The editorial team for the Library Technology Reports was solid. But once I finished the final reviews of the copy edits, I was put on the spot to write a short article for the American Libraries magazine, primarily to promote the report. This was not part of the contract, and I was given little direction and a month at a busy time of the school year to turn it around. I submitted a draft and never heard about it again – until I saw it in the magazine last week. They cut and revised it to focus on a narrow aspect of the census that was not the original premise, and they introduced errors to boot! As a writer I have never had an experience where I haven’t been given the opportunity to review revisions. It’s thoroughly unprofessional, and makes it difficult to defend the traditional editorial process as somehow being more accurate or thorough compared to the web posting and tweeting masses. They were apologetic, and are posting corrections. I was reluctant to contribute to the magazine to begin with, as I have a low opinion of it and think it’s deteriorated in recent years, but that’s a topic for a different discussion.
Stepping off the soapbox… I’ll be attending the ALA annual conference in DC later this month, to participate on a panel that will discuss the 2020 census, and to reconnect with some old colleagues. So if you want to talk about the census, you can buy me some coffee (or beer) and check out the report.
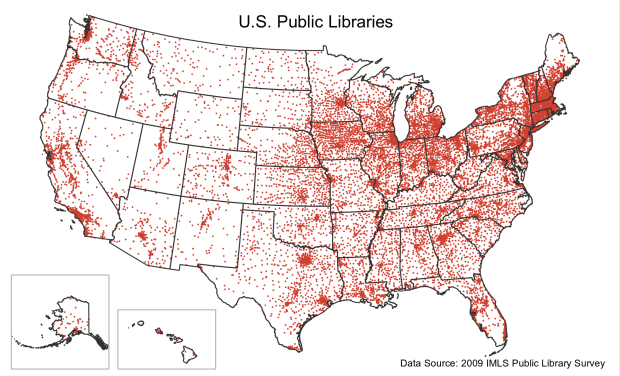
A final research and publication related note – the map that appears at the top of my post on the distribution of US public libraries from several years back has also made it into print. It appears on page 173 of The Argument Toolbox by K.J. Peters, published by Broadview Press. It was selected as an example of using visuals for communicating research findings, making compelling arguments in academic writing, and citing underlying sources to establish credibility. I’m browsing through the complimentary copy I received and it looks excellent. If you’re an academic librarian or a writing center professional and are looking for core research method guides, I would recommend checking it out.






You must be logged in to post a comment.