In spatial analysis, kernel density estimation (colloquially referred to as a type of “hot spot analysis”) is used to explore the intensity or clustering of point-based events. Crimes, parking tickets, traffic accidents, bird sightings, forest fires, incidents of infections disease, anything that you can plot as a point at a specific period in time can be studied using KDE. Instead of looking at these features as a distribution of discrete points, you generate a raster that represents a continuous surface of values. You can either measure the density of the incidents themselves, or the concentration of a specific attribute that is tied to those incidents (like the dollar amount of parking tickets or the number of injuries in traffic accidents).
In this post I’ll demonstrate how to do a KDE analysis in QGIS, but you can easily implement KDE in other software like ArcGIS Pro or R. Understanding the inputs you have to provide to produce a meaningful result is more important than the specific tool. This YouTube video produced by the SEER Lab at the University of Florida helped me understand what these inputs are. They used the SAGA kernel tool within QGIS, but I’ll discuss the regular QGIS tool and will cover some basic data preparation steps when working with coordinate data. The video illustrates a KDE based on a weight, where there were single points that had a count-based attribute they wanted to interpolate (number of flies in a trap). In this post I’ll cover simple density based on the number of incidents (individual noise complaints), and will conclude by demonstrating how to generate contour lines from the KDE raster.
For a summary of how KDE works, take a look at the entry for “Kernel” in the Encyclopedia of Geographic Information Science (2007) p 247-248. For a fuller treatment, I always recommend Christopher Lloyd’s Spatial Data Analysis: An Introduction to GIS Users (2010) p 93-97 by Oxford Press. There’s also an explanation in the ArcGIS Pro documentation.
Data Preparation
I visited the NYC Open Data page and pulled up the entry for 311 Service Requests. When previewing the data I used the filter option to narrow the records down to a small subset; I chose complaints that were created between June 1st and 30th 2022, where the complaint type began with “Noise”, which gave me about 75,000 records (it’s a noisy town). Then I hit the Export button and chose one of the CSV formats. CSV is a common export option from open data portals; as long as you have columns that contain latitude and longitude coordinates, you will be able to plot the records. The NYC portal allows you to filter up front; other data portals like the ones in Philly and DC package data into sets of CSV files for each year, so if you wanted to apply filters you’d use the GIS or stats package to do that post-download. If shapefiles or geoJSON are provided, that will save you the step of having to plot coordinates from a CSV.

With the CSV, I launched QGIS, went to the Data Source Manager, and selected Delimited Text. Browsed for the file I downloaded, gave the layer a common sense name, and under geometry specified Point coordinates, and confirmed that the X field was my longitude column and the Y field was latitude. Ran the tool, and the points were plotted in the basic WGS 84 longitude / latitude system in degrees, which is the system the coordinates in the data file were in (generally a safe bet for modern coordinate data, but not always the case).
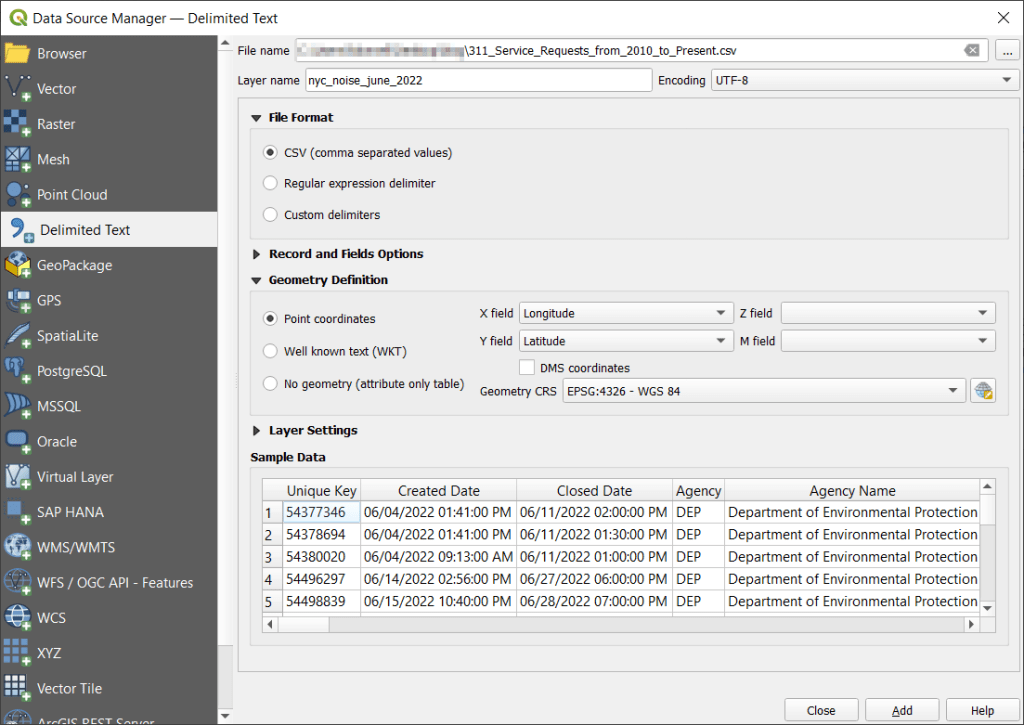
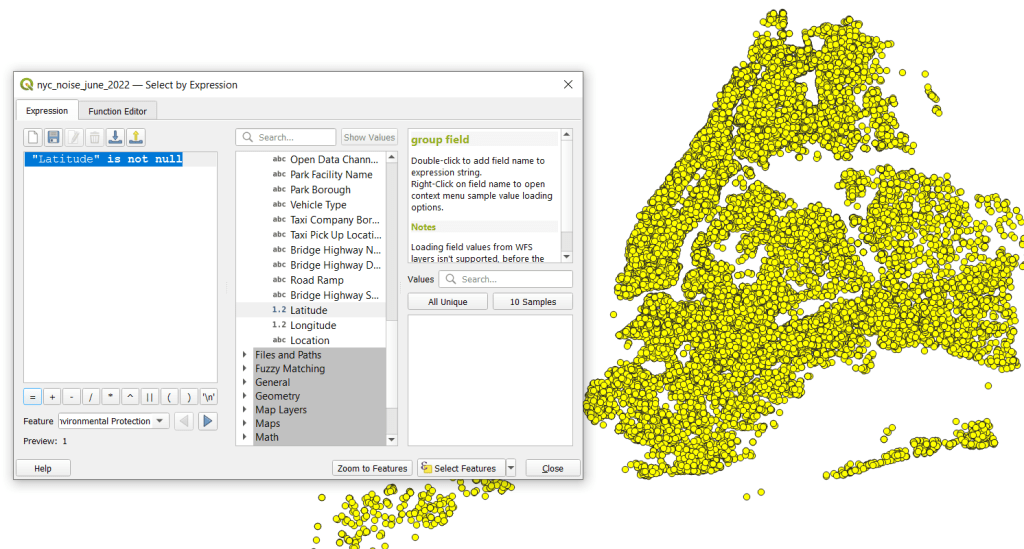
The next step was to save these plotted points in a file format that stores geometry and allows us to do spatial analysis. In doing that step, I recommend taking two additional ones. First, verify that all of the plotted data have coordinates – if there are any records where lat and long are missing, those records will be carried along into the spatial file but there will be no geometry for them, which will cause problems. I used the Select Features by Expression tool, and in the expression window typed “Latitude” is not null to select all the features that have coordinates.
Second, transform the coordinate reference system (CRS) of the layer to a projected system that uses meters or feet. When we run the kernel tool, it will ask us to specify a radius for defining the density, as well as the size of the pixels for the output raster. Using degrees doesn’t make sense, as it’s hard for us to conceptualize distances in degrees, and they are not a constant unit of measurement. If you’ve googled around and read Stack Exchange posts or watched videos where a person says “You just have to experiment and adjust these numbers until your map looks Ok”, they were working with units in fractions of degrees. This is not smart. Transform the system of your layers!
I selected the layer, right clicked, Export, Save Selected Features As. The default output is a geopackage, which is fine. Otherwise you could select ESRI shapefile, both are vector formats that store geometry. For file name I browse … and save the file in a specific folder. Beside CRS I hit the globe button, and in the CRS Selector window typed NAD83 Long Island in the filter at the top, and at the bottom I selected the NAD83 / New York Long Island (ftUS) EPSG 2263 option system in the list. Every state in the US has one or more state plane zones that you can select for making optimal maps for that area, in feet or meters. Throughout the world, you could choose an appropriate UTM zone that covers your area in meters. For countries or continents, look for an equidistant projection (meters again).
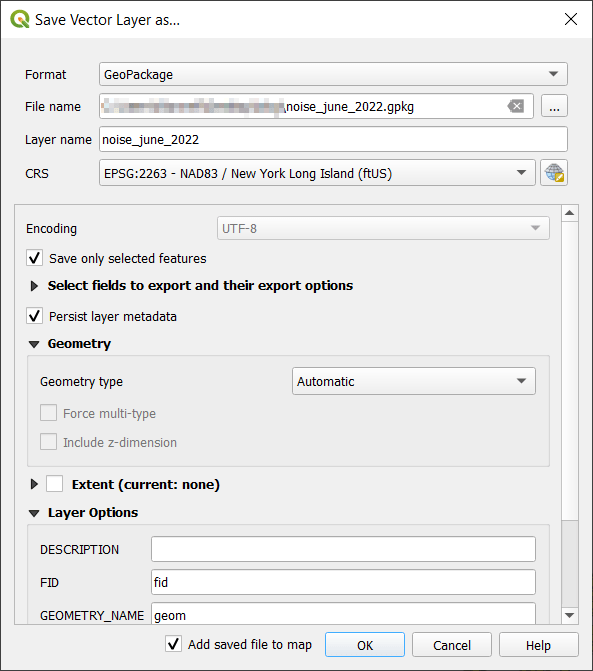
Clicked a series of Oks to create the new file. To reset my map window to match CRS of the new file, I selected that file, right clicked, Layer CRS, Set Project CRS from Layer. Removed my original CSV to avoid confusion, and saved my project.

Kernel Density Estimation
Now our data is ready. Under the Processing menu I opened the toolbox and searched for kernel to find Heatmap (Kernel Density Estimation) under the Interpolation tools. The tool asks for an input point layer, and then a radius. The radius is used to define an area for calculating a local density estimate around each point. We can use a formula to determine an ideal radius; the hopt method seems to be commonly employed for this purpose.
To use the hopt formula, we need to know the standard distance for our layer, which measures the degree to which features are dispersed around the spatial mean or center of the distribution. A nice 3rd party plugin was created for calculating this. I went to the the plugins menu, searched for the Standard Distance plugin, and added it. Searched for it in the Processing toolbox and launched it. I provided my point layer for input, and specified an output file. The other fields are optional (if we were measuring an attribute of the points instead of the density of the points, we could specify the attribute as a weight column). The output layer consists of a circle where the center is the mean center of the distribution, and the circle represents the standard deviation. The attribute table contains one record, with the standard distance attribute of 36,046.18 feet (if no feature was created, the likely problem is you have records in the point file that don’t have geometry – delete them and try again).
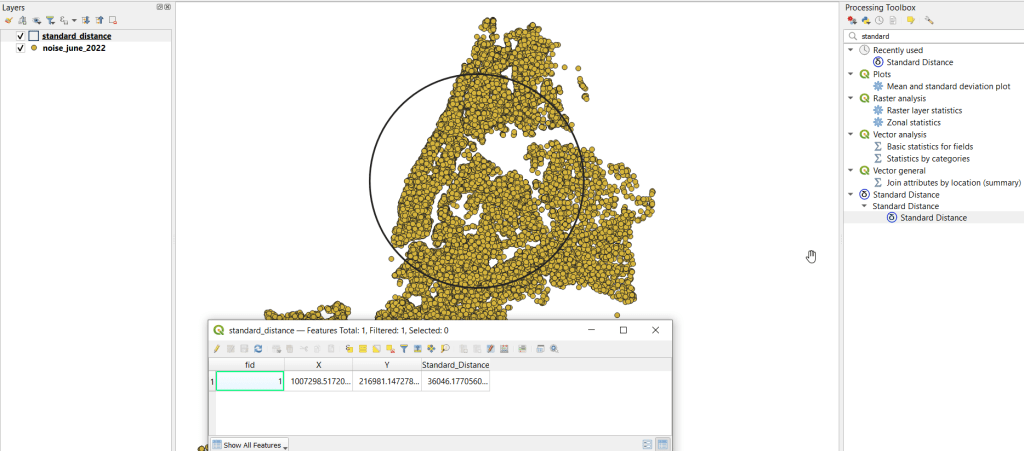
Knowing this, I used the hopt formula:
=((2/(3N))^0.25)SDWhere N is the number of features and SD is the standard distance. I used Excel to plug in these values and do the calculation.
((2/(374526))^0.25)36046.18 = 1971.33Finally, I launched the heatmap kernel tool, specified my noise points as input, and the radius as 1,971 feet. The output raster size does take some experimentation. The larger the pixel size, the coarser or more general the resolution will be. You want to choose something that makes sense based on the size of the area, the number of points, and / or some other contextual information. Just like the radius, the units are based on the map units of your layer. If I type in 100 feet for Pixel X, I see I’ll have a raster with 1,545 rows and 1,565 columns. Change it to 200 feet, and I get 773 by 783. I’ll go with 200 feet (the distance between a “standard” numbered street block in midtown Manhattan). I kept the defaults for the other options.
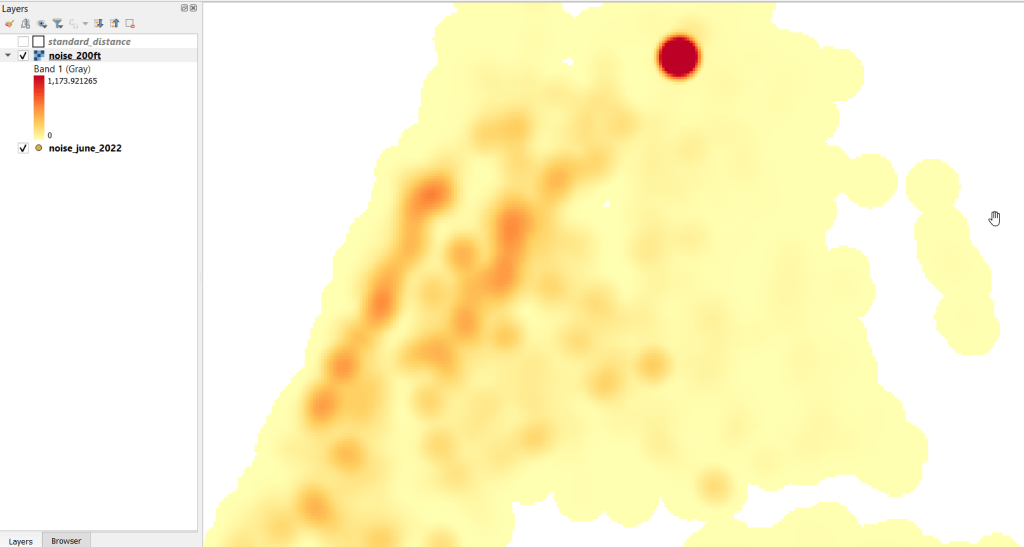
The resulting raster was initially displayed in black and white. I opened the properties and symbology menu and changed the render type from Singleband gray to Singleband pseudocolor, and kept the default yellow to red scheme. Voila!

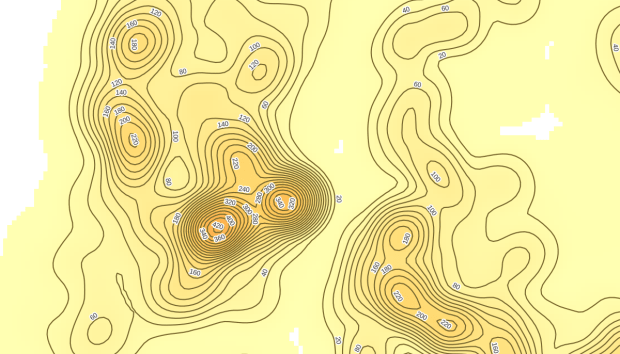
In June 2022 there were high clusters of noise complaints in north central Brooklyn, northern Manhattan, and the southwest portion of the Bronx. There’s a giant red hot spot in the north central Bronx that looks like the storm on planet Jupiter. What on earth is going on there? I flipped back to the noise point layer and selected points in that area, and discovered a single address where over 2,700 noise complaints about a loud party were filed on June 18 and 19! There’s also an address on the adjacent block that registered over 900 complaints. And yet the records do not appear to be duplicates, as they have different time stamps and closing dates. A mistake in coding this address, multiple times? A vengeful person spamming the 311 system? Or just one helluva loud party? It’s hard to say, but beware of garbage in, garbage out. Beyond this demo, I would spend more time investigating, would try omitting these complaints as outliers and run the heatmap tool again, and compare this output to different months. It’s also worth experimenting with the color classification scheme, and some different pixel sizes.
Contour Lines
Another interesting way to visualize this data would be to generate contour lines based on the kernel output. I did a search for contour in the processing toolbox, and in the contour tool I provided the kernel noise raster as the input. For intervals between contour lines I tried 20 feet, and changed the attribute name to reflect what the contour represents: COMPLAINT instead of ELEV. Generated the new file, overlaid on top of the kernel, and now you can see how it represents the “elevation” of complaints.
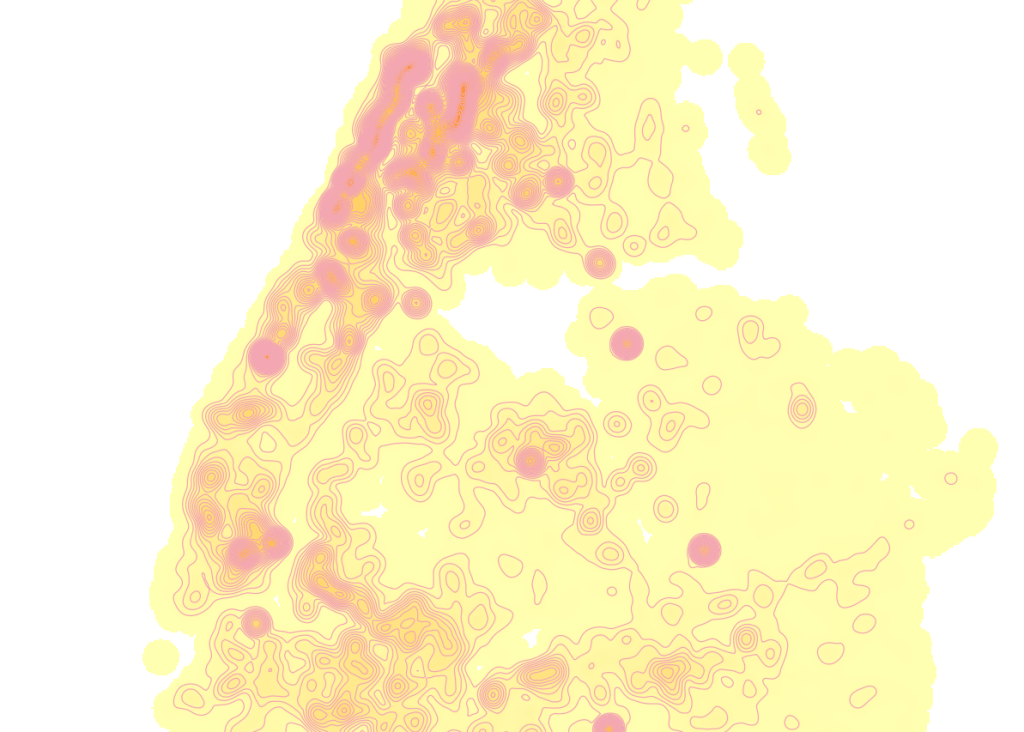
Switch the kernel off, symbolize the contours and add some labels, and throw the OpenStreetMap underneath, and now you can explore New York’s hills and valleys of noise. Or more precisely, the hills and valleys of noise complainers! In looking at these contours, it’s important to remember that they’re generated from the kernel raster’s grid cells and not from the original point layer. The raster is a generalization of the point layer, so it’s possible that if you look within the center of some of the denser circles you may not find, say, 340 or 420 actual point complaints. To generate a more precise set of contours, you would need to decrease the pixel size in the kernel tool (from say 200 feet to 100).
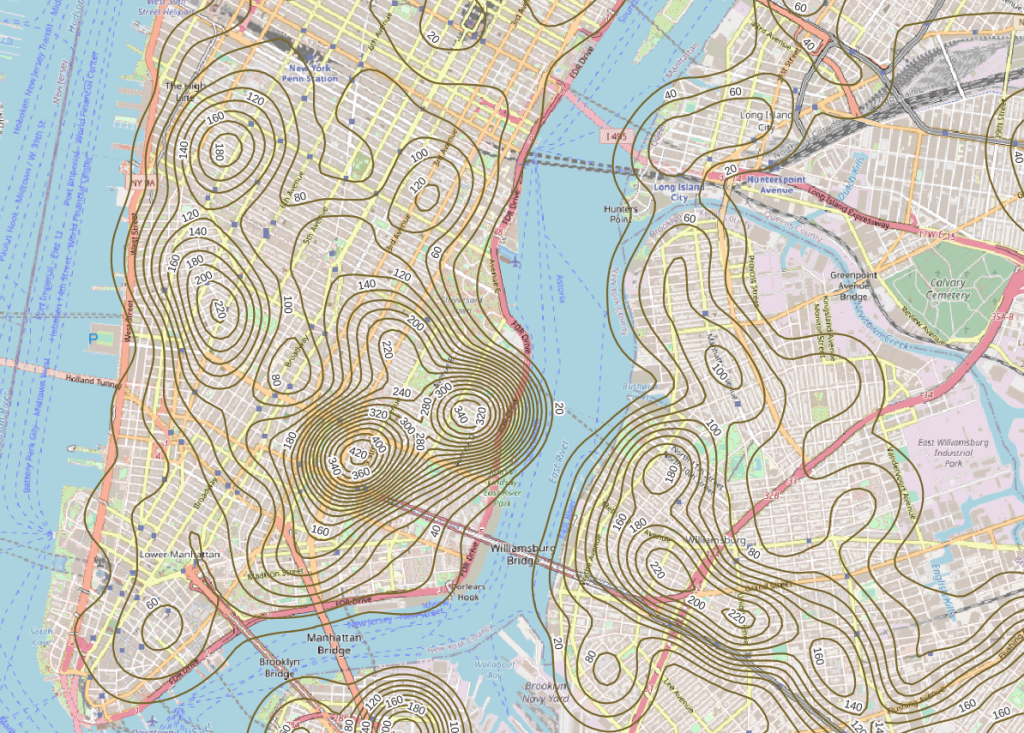
It’s interesting what you can create with just one set of points as input. Happy mapping!















You must be logged in to post a comment.