I posted the latest version of my Introduction to GIS with QGIS tutorial manual, updated for QGIS 3.44 Solothurn. The manual and sample data are freely available from my lab’s tutorials page.
This year’s changes are minor, as there weren’t major software updates that would impact the exercises. I updated the sample data as it was growing a bit stale, which necessitated updating screenshots and references in the text. I also updated the source LaTeX code to ensure the PDF meets the new federal WCAG guidelines for digital accessibility. I added a brief troubleshooting section on using QGIS with a Mac to the Introduction, as there have been a creeping number of annoying problems that have thrown my workshops off kilter (MacOS security blocking installation and writing of files to the user’s documents folder, and UI issues with the default color scheme and hiding menus in the background).
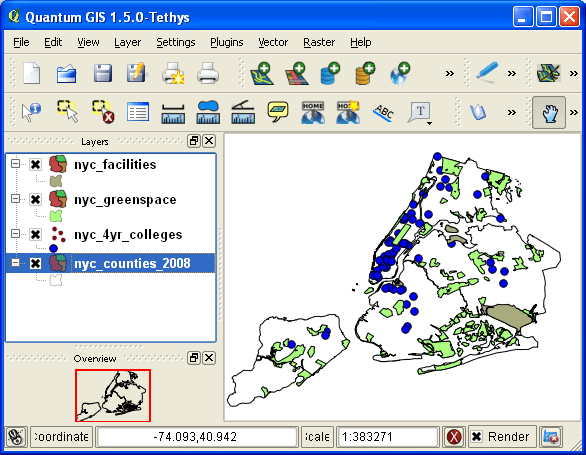
It’s hard to believe this is the 16th edition of this manual. When I wrote the first version back in 2011 (it was originally called Introduction to GIS Using Open Source Software), there was relatively little documentation on QGIS. In launching a workshop series and on-going support for it, I felt that I needed to create a basic guidebook. QGIS was far more primitive back then; converting the CRS for a GIS file required a separate command-line program, and you had to calculate natural breaks by hand! QGIS has certainly come a long way since then, and has been widely adopted. I’ve updated my materials as the software has evolved, but overall I’ve stuck to the same plan in terms of content, with modifications to the examples:
- Introduction: a general overview of the workbook, goals for the material and workshop, and updates to the manual since the previous version.
- An Overview of GIS: a short narrative that describes basic GIS concepts, and open source software.
- Exploring the Interface: explanation of the interface, adding vector data and viewing and selecting features, adding raster data, web base maps, and project files.
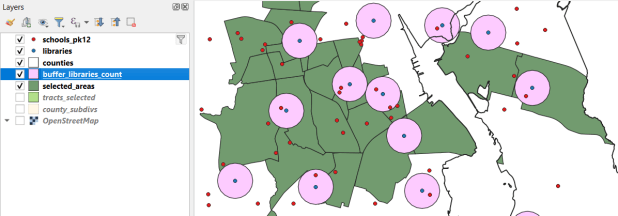
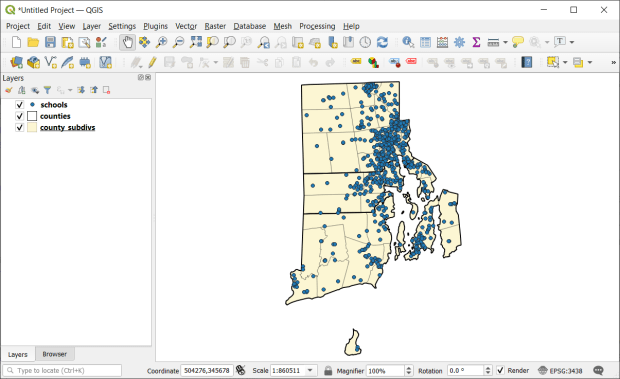
- Geographic Analysis: a cohesive case study that illustrates the process for doing an analysis while showcasing fundamental operations including: tables joins, plotting coordinate data, selecting, filtering, and deleting features, and geoprocessing tools like intersection and buffering. My original case study was locating a new comic book store in NYC, subsequently modified to locating a coffee shop, and more recently identifying public libraries in Rhode Island that met criteria for a grant to host an after school program.
- Thematic Mapping: exercise for understanding coordinate reference systems and how they function in QGIS, transforming systems, classifying data, and creating a final map layout. The original example was mapping healthcare sector employment by US state, but eventually switched to voter participation in federal elections.
- Data and Educational Resources: strategies and suggestions for finding GIS data, and recommendations for learning more through tutorials and workshops.
I’ve always used a follow-the-leader approach in teaching the workshop, where we stay together and the group does the material step by step. Everyone is a little fatigued by the end of the day, so for the thematic mapping piece we pivot to using the workbook; I demo the material and folks work on their own. I primarily wrote the book as a takeaway, so people could refer back to it after the session was over. It was also useful for self-directed learning, and the act of writing and updating it helps me internalize the material.
The last couple of years have been challenging though, and I have been thinking about what I could do differently. There have been a number of articles recently that discuss declining attention spans and students’ diminishing ability to thoughtfully engage with text (for example, in The Economist and The Atlantic). My own experiences bear this out. Increasingly, participants have a hard time following me in the session, and when I have student employees do the tutorial on their own as part of orientation, it takes them much longer and they struggle to finish. I have other workshops where I don’t use the follow-the leader approach, and instead I demo the material and everyone works on their own using the text, and once everyone finishes we move on to the next part. This works no better, as many participants wander away (mentally and physically) from the exercises and struggle to relate the text to what’s on the screen. Now, a good deal of success hinges on having good instructions, but I update them every year, and have used the same system and material in earlier years to good effect.
I have considered creating a more interactive web version of the workbook, or creating videos. The problem with both is that updating them each year would be far more time consuming; in contrast, updating the text and images in the workbook is pretty straightforward. I had one colleague suggest that my “old school” workbook fills an important niche in terms of structure and format, and is useful “as is” for deep learners. A professor I work with, who has had similar experiences in the classroom, expressed that there’s a limit to what an instructor can do; we can only simplify the material so much, and it’s up to students to rise to the occasion.
Reflecting on how I learn, I have gradually moved to videos to learn new material: whether it’s understanding a particular GIS method or tool, mastering a video game, or figuring out how to replace the belt on my clothes drier. Nothing beats a book for getting a comprehensive introduction to a topic, but the videos are helpful for targeted, stand-alone tasks. They can be comprehensive too, if they’re thoughtfully designed as part of a series. I’m definitely going to keep the workbook manual going, but am considering a video version for the future. I’ll wait until the 4.x version of QGIS becomes the new long term release (early next year) before I head in that direction, as the jump from 3.x to 4.x is more likely to come with some interface and functional changes.
The workbook has gotten a lot of miles these past 16 years, and I know others have used it for their own workshops and courses. Feel free to reach out if you have any suggestions.







{kind=link}
{kind=link}
You must be logged in to post a comment.