With the dawn of a new academic year I usually spend a little time looking back at the previous one. Since I began my position as Geospatial Data Librarian at Baruch College I’ve logged my questions, consultations, course visits, and workshops in a spreadsheet that I’ve used for creating summaries and charts. I spent a good chunk of this summer improving my Pandas skills, and put them to the test by summarizing and plotting my services data in a Jupyter Notebook instead.
Pandas is a data science module for Python that adds so many new components that it’s like a language all by itself. Its big selling point is that it adds a grid-like data structure to Python. In vanilla Python, you typically read data files into a list of lists where the big list represents the file, the individual lists represent rows, and the list elements represent values. There are no columns; to manipulate data you iterate through the sub-lists and elements by their position number. In well-structured datasets, elements in the same position in each sub-list represent attributes that would be stored in the same column.
In contrast, Pandas provides a true row and column structure called a dataframe, where you access each row by its index (a unique id) and columns by name or position. Furthermore, methods and functions that you apply to the data are automatically applied to entire rows and columns, and in some cases even to the entire dataframe, so that looping through data element by element is largely unnecessary. You’re able to treat a dataframe as if it were a spreadsheet or database table, in that you can concatenate dataframes together, merge them on their index numbers, and group records by values.
Using Pandas in concert with a Jupyter Notebook allows for an iterative approach to exploring and manipulating data, and is particularly conducive to creating plots and charts. You can use Python’s tried and true matplotlib module to build your chart bit by bit, or you can use Panda’s own plotting functions, which are wrappers around matplotlib that allow you to quickly create charts with fewer lines of code. Another plotting module called Seaborn offers a third approach.
This cheat sheet has become my indispensable reference for keeping track of the different Pandas functions and methods, and for helping me mentally navigate the different ways of doing things in Pandas versus regular Python. Plotting was a struggle at first, as I tried to figure out when to use Pandas versus matplotlib versus Seaborn. The fact that it’s possible to use all three at once to create the same plot added to my confusion! This visualization flowchart helped me sort things out. For simple stuff, I used the Pandas plot functions, but if the chart required additional customization I used matplotlib to generate the extra pieces, or the whole thing. In essence, use matplotlib for super detailed control over customization, and use Pandas plot functions as shortcuts for writing more concise code.
Preamble
I’ve stored my notebook and the data file on github (still a work in progress) if you’d like to take a closer look (the notebook is the ipynb file). I’m going to address a portion of what’s in the notebook in this post.
First and foremost you need to import pandas and matplotlib’s pyplot. The %matplotlib inline trick tells the notebook to display all charts that you generate with matplotlib; otherwise it just creates them without displaying them. The plt.style.use() lets you apply a global style (chart colors, background, grid lines etc) to all plots in your notebook. This convenient style sheet reference demonstrates what they all look like.
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('seaborn-muted')
Web Stats
I’ll start with the simplest example. My spreadsheet doesn’t contain web stats, so I needed to hard code these into the notebook. To create a dataframe you build it column by column, and add the index last. In a notebook you don’t need to use a print function to see the data, you simply enter the name of the object that you want to display:
geoportal=pd.DataFrame({'Page Views' : [29500, 37254, 40421, 33527],
'Unique Views' : [23052, 29285, 31668, 26418],
'Downloads' : [3561, 6807, 6682, 5208]},
index=['2015.16','2016.17','2017.18','2018.19'])
geoportal
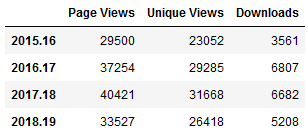
The plot was pretty darn simple, using Panda’s DataFrame.plot you specify the type of chart (bar in this case), pass in a few arguments, and voila! Pandas automatically uses the index for the x axis (academic years in this case) and will attempt to plot all columns on the y axis. If this isn’t desirable you can set x and y in the arguments. The default legend placement isn’t ideal in this example, but we’ll see how to change it later. plt.savefig() saves the chart as an image file outside the notebook.
geoportal.plot.bar(rot=0, title='Baruch Geoportal')
plt.savefig('webfig.png')

Questions and Consultations
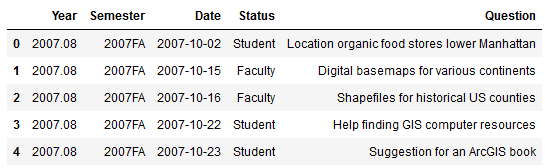
The rest of my data is stored in an Excel spreadsheet. You can quickly read spreadsheets into a dataframe by specifying the file and sheet, and the head() command previews the top records.
questions = pd.read_excel('RefLog.xlsx', sheet_name='Questions')
questions.head()
I used the groupby method to summarize the number of questions by semester, indicating what column to use for grouping, and how to aggregate. In this example I use .size() which counts all records (another method called count is similar except it does not count null values). Since this result returns just a single column, Pandas returns a data type called a sequence, which is a single-column dataframe with an index (similar to a dictionary key-value pair in vanilla Python). If I want a new dataframe, I can explicitly feed in the columns, reset the index and set it to the year. You can plot data from either type.
#Summarize as a series
questions_sem=questions.groupby(by='Semester').size()
#Summarize as a dataframe
questions_yr=questions[['Year','Question']].groupby(by='Year').size().reset_index(name='Questions').set_index('Year')
questions_yr
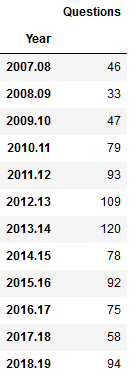
As before, the plot is pretty simple, but in this case when saving the figure I specify bounding box tight so the labels don’t get cut off (I rotated them 45 degrees for legibility).
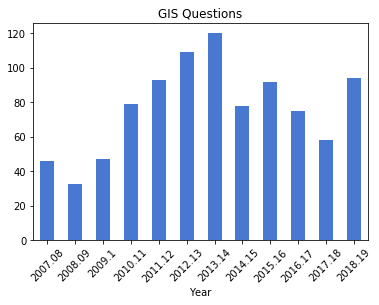
questions_yr.plot.bar(rot=45, legend=None, title="GIS Questions")
plt.savefig('questions.png',bbox_inches='tight')
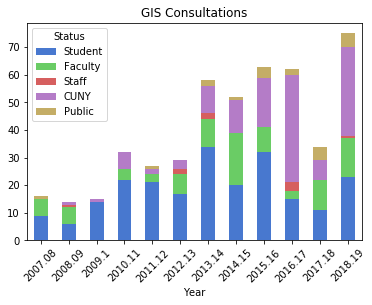
To create a stacked bar chart that shows the number of questions and the status of the person who asked them, I can create a new dataframe where I group by both year and status. One of the initial challenges in learning how to plot data is figuring out what structure is appropriate. After some experimentation, I figured out that each status needs to be as column in order to plot it. I used the following with the unstack method to pivot the data:
questions_status2=questions[['Year','Question','Status']]\ .groupby(by=['Year','Status']).size().unstack() questions_status2
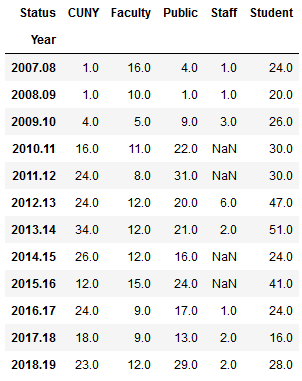
questions_status2[['Student','Faculty','Staff','CUNY','Public']]\
.plot.bar(stacked=True, rot=45, title="GIS Questions")
plt.savefig('questions_status.png',bbox_inches='tight')

Explicitly stating the columns isn’t necessary, but it allows you to specify the order in which they appear in the chart. I have another worksheet that lists my consultations, that I read in, transform, and plot using the same statements:
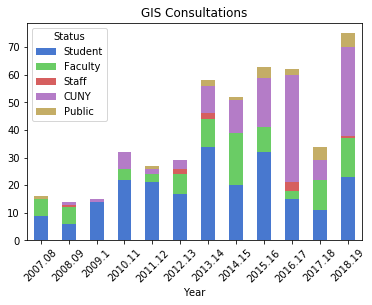
Questions represent emails or phone calls that I’ve received, while consultations are in- person, one-on-one sessions. Both the questions and consultations are specific to demographic, geospatial, or GIS-related topics. Students, faculty, and staff refer to people affiliated with my college (Baruch), while the CUNY category captures affiliates from all the other schools in the university regardless of their status. Public captures anyone outside the university.
The initial patterns are similar: the number of questions was low for my initial three years, and then began to take off in the 2010-11 academic year. This coincided with my movement out of the library’s Information Services Division and into the Graduate Services Division, where I was able to devote more time to providing my specialized services and less time providing general ones (i.e. the reference desk, visiting freshmen English composition classes). 2010-11 was also the year I introduced my day-long introductory GIS workshops which led to an increase in business, particularly from other CUNY campuses.
Another turning point was 2014-15 but the data diverges; the number of questions dips and hasn’t returned to to the peak I hit in 2013-14, while consultations remain consistently high. This is the year that I moved into the GIS Lab, and was able to provide better on-going in-person support. It was also the year I received tenure and promotion, which immediately resulted in a heavy increase in service commitments, i.e. serving on various college committees that took me away from my work (while I have graduate assistants that help with consultations, questions are sent directly to me). 2017-18 is a big divot on both charts as this was the year I was away on sabbatical to write my book (my grad assistant Janine held down the fort at the lab while I monitored questions from home), but there was a solid rebound in 2018-19.
Course Visits and Workshop Stats
I frequently visit public policy, journalism, and other courses to give lectures on census data and GIS, and for these charts I wanted to show the number of classes I visited and attendance on one chart. After loading my teaching data in, I excluded records that represented my GIS workshops by using the query method. Since I wanted to create two different aggregates – a count and a sum – I applied the .agg method after using groupby:
classes_yr=classes[['Year','Class','Attendance']].groupby('Year').agg({'Class':'count', 'Attendance':'sum'})
classes_yr

As best as I could tell, the Pandas plot function couldn’t handle a line and bar on the same chart with a secondary Y axis, so I used matplotlib instead, building the chart one piece at a time:
plt.figure()
ax = classes_yr['Attendance'].plot(secondary_y=True, marker='o', color='orange')
ax = classes_yr['Class'].plot(kind='bar', title='Course Visits', rot=45)
ax.set_ylabel('Courses')
plt.ylabel('Attendance')
plt.savefig('courses.png',bbox_inches='tight')
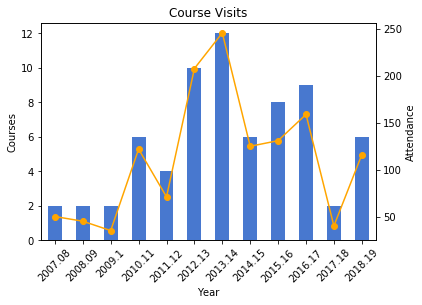
The courses I visit are consistently mid-sized with about 20 students a piece, so visits and attendance track pretty closely. The pattern is similar to my questions and consultations, initially low, rising as I gained independence, dropping once I hit tenure and service commitments, then gradually rising until the 2017-18 sabbatical year.
For the GIS workshops (stored in greater detail in a separate worksheet) I wanted to create two charts: a summary of attendance for each year by status, and another showing the schools that participants came from. Since attendance will vary by the number of workshops, I also wanted to incorporate the number of sessions into the first chart. After loading in the data:
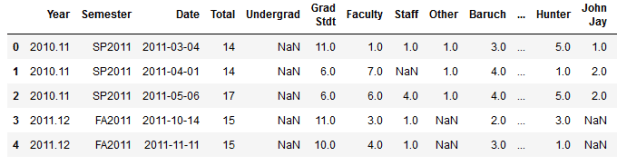 and creating a grouped summary:
and creating a grouped summary:

I created an independent sequence for the labels using string methods:
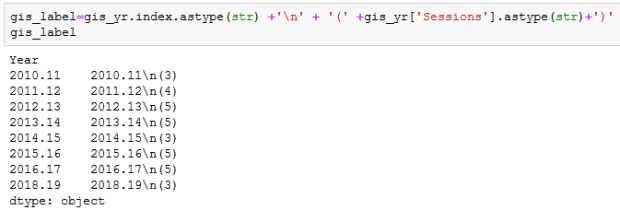
and I used matplotlib so I could set different tick labels and move the legend, as the default placement blocked portions of the bars:
plt.figure()
ax=gis_yr[['Undergrad','Grad Stdt','Faculty','Staff','Other']].plot.bar\
(stacked=True, rot=25, title="GIS Workshops")
ax.set_xticklabels(gis_label)
ax.set_xlabel('Year (# Sessions)')
ax.set_ylabel('Attendance')
plt.legend(loc='upper center', bbox_to_anchor=(1, 1))
plt.savefig('workshops.png',bbox_inches='tight')
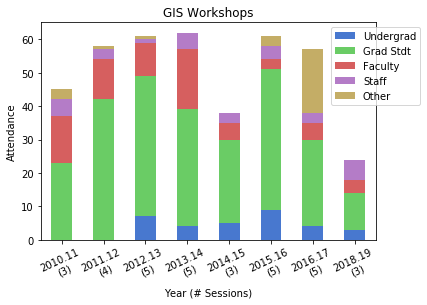
For the workshops, the status includes all CUNY members regardless of school, while Other is anyone not affiliated with CUNY. Graduate students have always comprised the largest share of participants. Once again, there is the tenure dip in 2014-15 (fewer sessions) and no sessions during 2017-18 sabbatical. 2016-17 was an exceptional year as one of our sessions was held at the FOSS4G conference, so there are lots of participants from the Other category. The latest year was disappointing, as bad weather impacted attendance at two of the sessions.
I wanted to create a pie chart to show participation by CUNY school, but to make it aesthetically pleasing I needed to remove schools with few participants and add them to an Other CUNY category. Otherwise there would be tiny wedges with unreadable labels. After creating a subset of the workshops dataframe that summed values only for the school columns, I iterated through the schools to sum attendance to a variable, dropped those schools, and added the sum to the other category (see the notebook for details). I used the Pandas plot function to create the pie chart, and used the autopct argument to display percentages in the wedges. I also specified a figure size, which you can do for any chart (and becomes important when you decide to embed them in documents):
gis_total=gis_schools.sum()
gis_schools.plot.pie(legend=False, figsize=(6,6), \
title='Workshop Participants by School \n ({} Participants in Total)'.format(gis_total), autopct='%i%%')
plt.ylabel("")
plt.savefig('schools.png',bbox_inches='tight')

One-third of participants were from my college, and one-fourth were from the Graduate Center, which is our nearest CUNY neighbor with a large population of master’s and PhD students who are keenly interested in learning GIS. The next biggest contributors are Hunter and Lehman Colleges, which are the two CUNY schools that have geography departments with GIS programs; Hunter is also close to Baruch, and we took a road trip to offer some sessions on Lehman’s campus.
Wrap Up
What I like about this approach is that you can summarize and reconfigure data without messing with the original source, and you can clearly see what your formulas are as they’re not hidden beneath the resulting values. These are both hazards when working directly within spreadsheets. While it takes time to learn these new functions and to grapple with finding work-arounds for exceptions, I don’t think it’s any less difficult than trying to accomplish the same things in a spreadsheet. I’ve always found spreadsheet charting to be rather clumsy, where you’re forced to cycle through numerous windows or to click on minuscule pieces of a chart to access hidden settings that you need. The Pandas / notebook approach makes a lot of sense for iterative data exploration, summation, and visualization, although I’ll continue to rely on regular Python for projects that fall outside this specific domain.
