Introduction
In this post I’ll demonstrate how to use the IPUMS CPS Online Data Analysis System to generate summary data from the US Census Bureau’s Current Population Survey (CPS). The tool employs the Survey Documentation and Analysis system (SDA) created at UC Berkeley.
The CPS is a monthly stratified sample survey of 60k households. It includes a wide array of statistics, some captured routinely each month, others at various intervals (such as voter registration and participation, captured every November in even-numbered years). The same households are interviewed over a four-month period, then rotated out for four months, then rotated back in for a final four months. Given its consistency, breadth, high response rate and accuracy (interviews are conducted in-person and over the phone), researchers use the CPS microdata (individual responses to surveys that have been de-identified) to study demographic and socio-economic trends among and between different population groups. It captures many of the same variables as the American Community Survey, but includes a fair number that are not.
I think the CPS is used less often by geographers, as the sample size is too small to produce reliable estimates below the state or metropolitan area levels. I find that students and researchers who are only familiar with working with summary data often don’t use it; generating your own estimates from microdata records can be time consuming.
The IPUMS project provides an online analyzer that lets you generate summary estimates from the CPS without having to handle the individual sample records. I’ve used it in undergraduate courses where students want to generate extracts of data at the regional or state level, and who are interested in variables not collected in the ACS, such as generational households for immigrants. The online analyzer doesn’t include the full CPS, but only the data that’s collected in March as part of the core CPS series, and the Annual Social & Economic Supplement (ASEC). It includes data from 1962 to the present.
To access any of the IPUMS tools, you must register and create an account, but it’s free and non-commercial. They provide an ample amount of documentation; I’ll give you the highlights for generating a basic geographic-based extract in this post.
Creating a Basic Geographic Summary Table
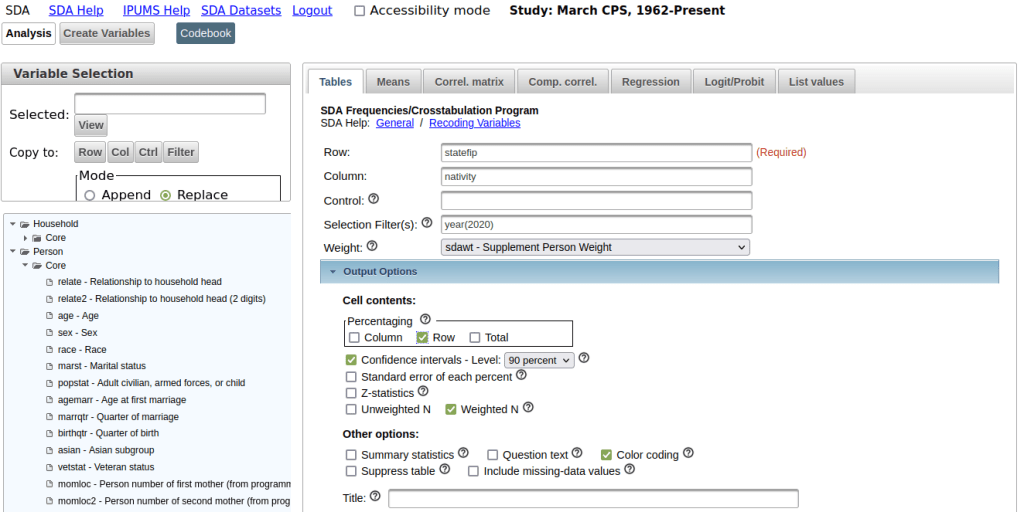
Once you launch the tool, the first thing you need to do is select some variables. You can use the drill-down folder menus at the bottom left, but I find it’s easier to hit the Codebook button and peruse the alphabetical list. Let’s say we want to generate state-level estimates for nativity for a recent year. If we go into the codebook and look-up nativity, we see it captures foreign birthplace or parentage. Also in the list is a variable called statefip, which are the two-digit codes that uniquely identify every state.

Back on the main page for the Analyzer in the tables tab, we provide the following inputs:
- Row represents our records or observations. We want a record for every state, so we enter the variable: statefip.
- Column represents our attributes or variables. In this example, it’s: nativity.
- Selection filter is used to specify that we want to generate estimates from a subset of all the responses. To generate estimates for the most recent year, we enter year as the variable and specify the filter value in parentheses: year(2020). If we didn’t specify a year, the program would use all the responses back to 1962 to generate the estimates.
- Weight is the value that’s used to weight the samples to generate the estimates. The supplemental person weight sdawt is what we’ll use, as nativity is measured for individual persons. There is a separate weight for household-level variables.
- Under the output option dropdown, we change the Percentaging option from column to row. Row calculates the percentage of the population in each nativity category within the state (row). The column option would provide the percentage of the population in each nativity category between the states. In this example, the row option makes more sense.
- For the confidence interval, check the box to display it, as this will help us gauge the precision of the estimate. The default level is 95%; I often change this to 90% as that’s what the American Community Survey uses.
- At the bottom of the screen, run the table to see the result.
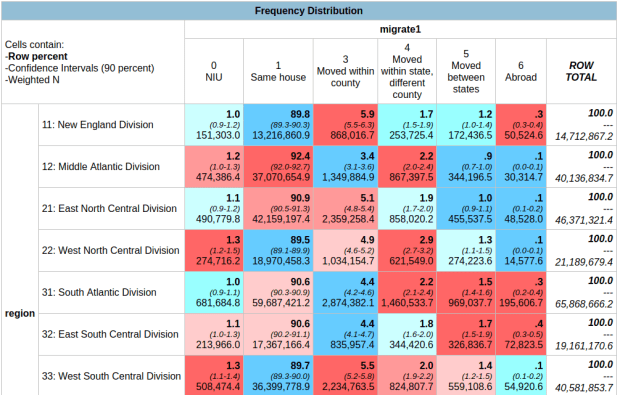
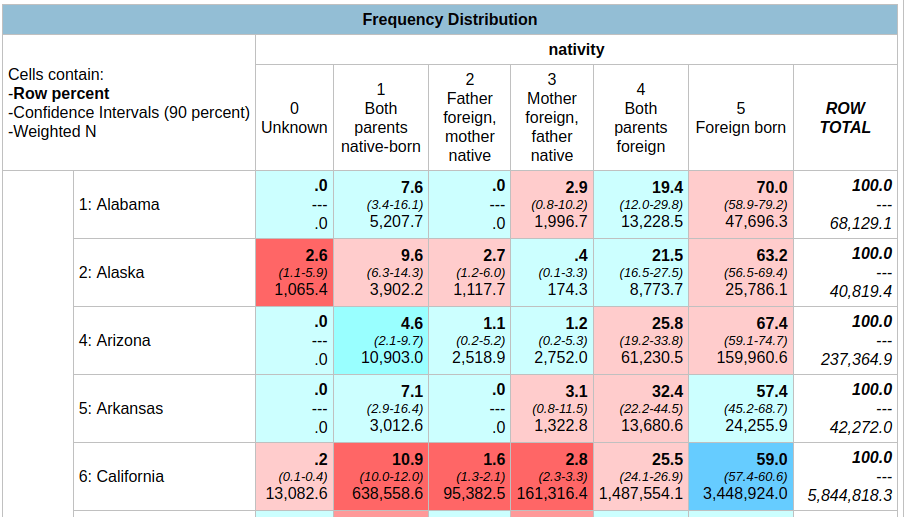
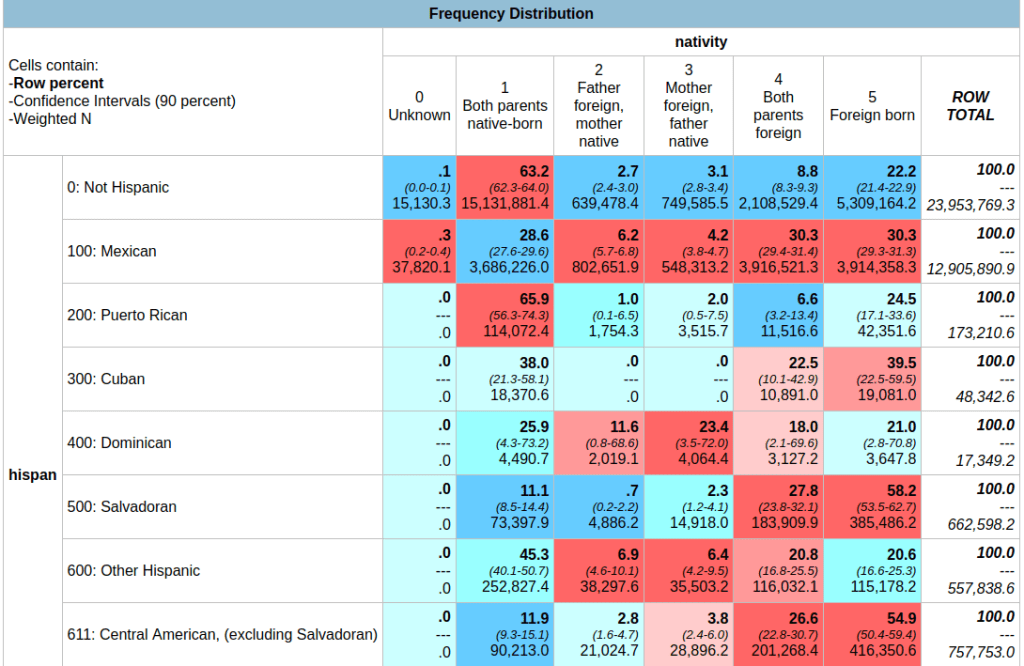
In the result, the summary of your parameters appears at the top, with the table underneath. At the top of the table, the Cells contain legend lists what appears in each of the cells in order. In this example, the row percent is first, in bold. For the first cell in Alabama: 91.0% of the total population have parents who were both born in the US, the confidence interval is 90.2% to 91.8% (and we’re 90% confident that the true value falls within this range), and the large number at the bottom is the estimated number of cases that fall in this category. Since we filtered our observations for one year, this represents the total population in that category for that year (if we check the totals in the last column against published census data, they are roughly equivalent to the total population of each state).
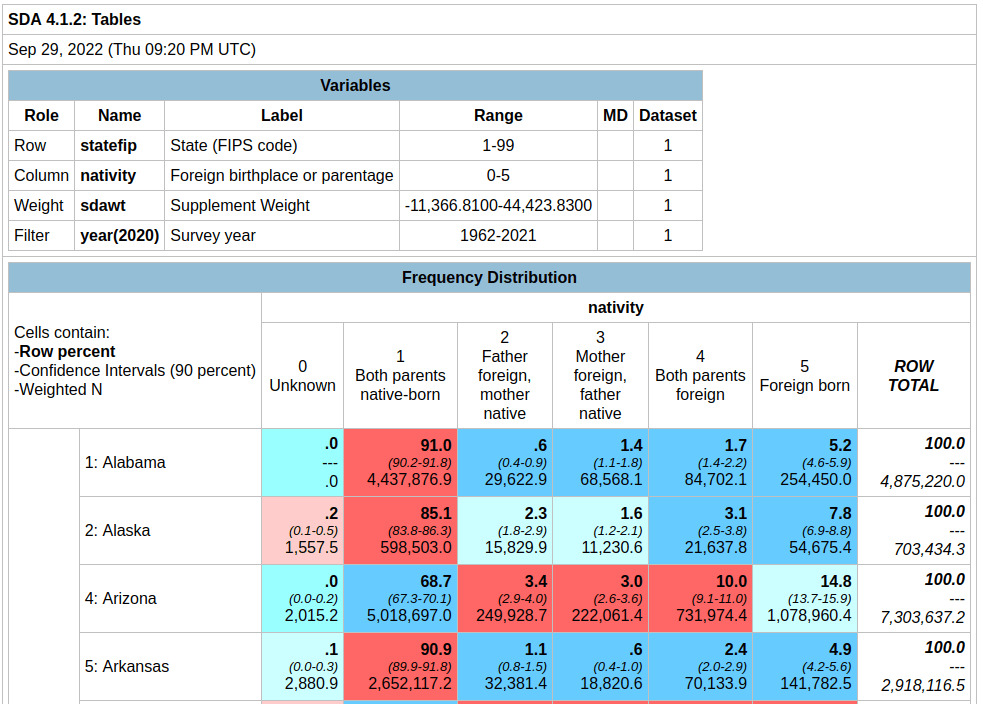
Glancing through the table, we see that Alabama and Alaska have more cases where both parents are born in the US (91.0% and 85.1%) relative to Arizona (68.7%). Arizona has a higher percentage of cases where both parents are foreign born, or the persons themselves are foreign-born. The color coding indicates the Z value (see bottom of the table for legend), which indicates how far a variable deviates from the mean, with dark red being higher than the expected mean and dark blue being lower than expected. Not surprisingly, states with fewer immigrants have higher than average values for both parents native born (Alabama, Alaska, Arkansas) while this value is lower than average for more diverse states (Arizona, California).
To capture the table, you could highlight / copy and paste the screen from the website into a spreadsheet. Or, if you return to the previous tab, at the bottom of the screen before running the table, you can choose the option to export to CSV.
Variations for Creating Detailed Crosstabs
To generate a table to show nativity for all races:
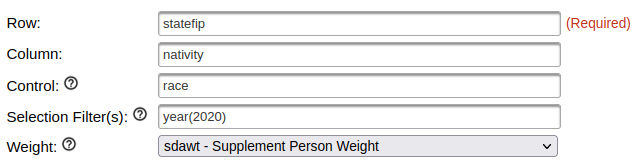
In the control box, type the variable race. The control box will generate separate tables in the results for each category in the control variable. In this case, one nativity table per racial group.
To generate a table for nativity specifically Asians:
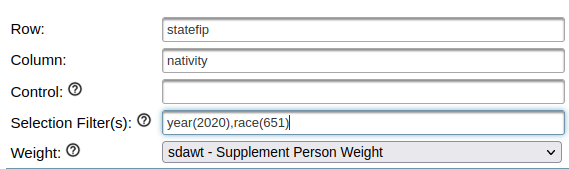
Remove race from the control box, and add it in the filter box after the year. In parentheses, enter the race code for Asians; you can find this in the codebook for race: year(2020), race(651).
Now that we’re drilling down to smaller populations, the reliability of the estimates is declining. For example, in Arkansas the estimate for Asians for both parents foreign born is 32.4%, but the value could be as low as 22.2% or as high as 44.5%. The confidence interval for California is much narrower, as the Asian population is much larger there. How can we get a better estimate?
Generate a table for nativity for Asians over a five year period:
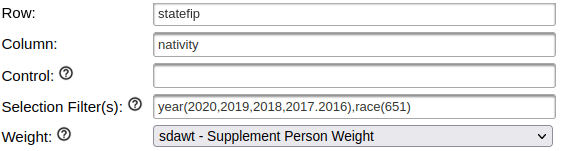
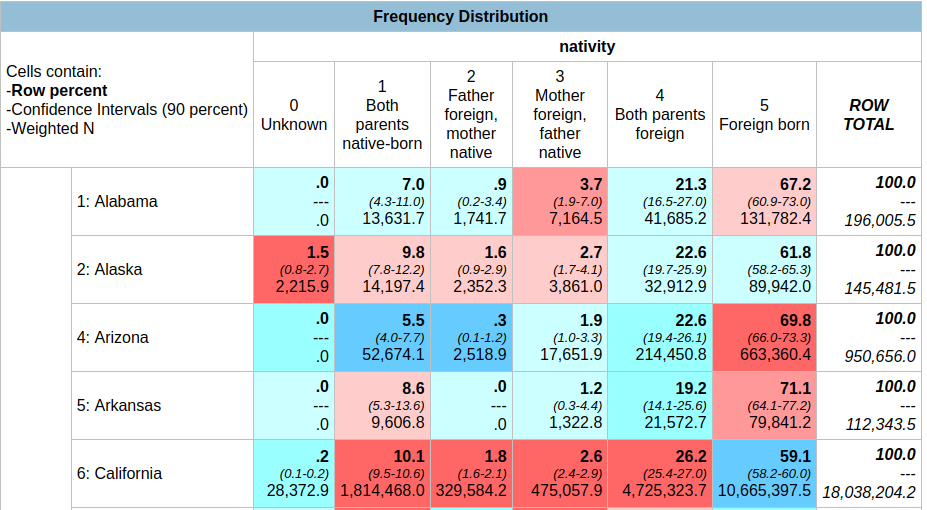
Add more years in the year filter, separated by commas. In this version, our confidence intervals are much narrower; notice for Asians for both parents foreign born in Arkansas is now 19.2% with a range of 14.1% to 25.6%. By increasing the sample pool with more years of data, we’ve increased the precision of the estimate at the cost of accepting a broader time period. One big caveat here: the Weighted N represents the total number of estimated cases, but since we are looking at five years of data instead of one it no longer represents a total population value for a single year. If we wanted to get an average annual estimate for this 5-year time period (similar to what the ACS produces), we’d have to divide each of estimates by five for a rough approximation. You can download the table and do these calculations in a spreadsheet or stats program.
You can also add control variables to a crosstab. For example, if you added sex as a control variable, you would generate separate female and male tables for the nativity by state for the Asian population over a given time period,
Example of a Profile Table
If we wanted to generate a profile for a given place as opposed to a comparison table, we can swap the variables we have in the rows and columns. For example, to see nativity for all Hispanic subgroups within California for a single year:
In this case, you could opt to calculate percentages by column instead of row, if you wanted to see percent totals across groups for the categories. You could show both in the same chart, but I find it’s difficult to read. In this last example, note the large confidence intervals and thus lower precision for smaller Hispanic groups in California (Cuban, Dominican) versus larger groups (Mexican, Salvadoran).
In short – this is handy tool if you want to generate some quick estimates and crosstabs from the CPS without having to download and weight microdata records yourself. You can create geographic data for regions, divisions, states, and metro areas. Just be mindful of confidence intervals as you drill down to smaller subgroups; you can aggregate by year, geography, or category / group to get better precision. What I’ve demonstrated is the tip of the iceberg; read the documentation and experiment with creating charts, statistical summaries, and more.


You must be logged in to post a comment.