It’s been awhile since I’ve written a post that showcases different GIS datasets. So in this one, I’ll provide an overview of some free and open data sources that I’ve learned about and worked with this past spring semester. The topics in these series include: global land use and land cover, US heat and temperature, detailed population data for India, and public health in low and middle income countries.
The GLAD lab at the Department of Geographical Sciences at the University of Maryland produces over a dozen GIS datasets related to global land use, land cover, and change in land surface over time. Last semester I had folks who were interested in looking at recent global change in cropland and forest. GLAD publishes rasters that include point-in-time coverage, period averages, and net change and loss over the period 2000 to 2020. Much of the data is generated from LANDSAT, and resolution varies from 30m to 3km. Other series include tropical forest cover and change, tree canopies, forest lost due to fires, a few non-global datasets that focus on specific regions, and LANDSAT imagery that’s been processed so it’s ready for LULC analysis.
Most of the sets have been divided up into tiles and segmented based on what they’re depicting (change in crops, forest, etc). The download process is basic point and click, and for larger sets they provide a list of tifs in a text file so you can automate downloading by writing a basic script. Alternatively, they also publish datasets via Google Earth Engine.
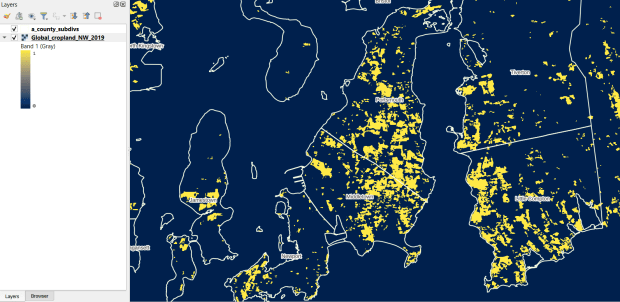
GLAD Cropland Extent in 2019 in QGIS, Zoomed in to Optimal Resolution in SE Rhode Island
For the past few years, the Trust for Public Land has published an annual heat severity index. This layer represents the relative heat severity for 30m pixels for every city in the United States; depicting where areas of cities are hotter than the average temperature for that same city as a whole (i.e. the surface temperature for each pixel relative to the general air temperature reading for the entire city). Severity is measured on a scale of 1 to 5, with 1 being a relatively mild and 5 being severe heat. The index is generated from a Heat Anomalies raster which they also provide; it contains the relative degrees Fahrenheit difference between any given pixel and the mean heat value for the city in which the pixel is located. Both datasets are generated from 30-meter Landsat 8 imagery, band 10 (ground-level thermal sensor) from summertime images.
The dataset is published as an ArcGIS image service. The easiest way to access it is by to adding it from the Living Atlas to ArcGIS Pro (or Online), and then export the service from there as a raster feature class (while doing so, you can also clip the layer to a smaller area of interest). It’s possible that you can also connect to it as an ArcGIS REST Server in QGIS, but I haven’t tried. While there are files that go back to 2019, the methodology has changed over time, so studying this as a national, annual time series is not appropriate. The coverage area expanded from just large, incorporated cities in earlier years to the entire US in recent years.
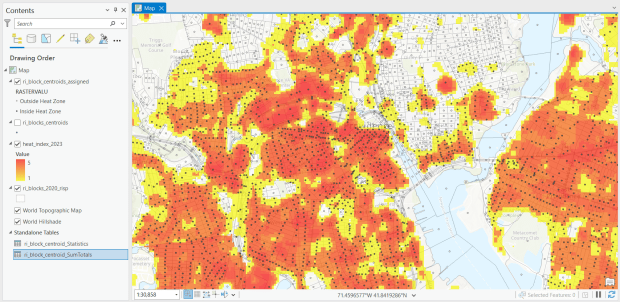
US Heat Severity Index 2023 in ArcGIS Pro, Providence and Adjacent Areas with Census Blocks
Created and hosted by the Development Data Lab (a collaborative project created by academic researchers from several universities), the Socioeconomic High-resolution Rural-Urban Geographic Platform for India (SHRUG) is an open access repository consisting of datasets for India’s medium to small geographies (districts, subdistricts, constituencies, towns, and villages), linked together with a set of common geographic IDs. Getting geographically detailed census data for India is challenging as you have to purchase it through 3rd party vendors, and comparing data across time is tough given the complex sets of administrative subdivisions and constant revisions to geographic identifiers. SHRUG makes it easy and open source, providing boundaries from the 2011 census and a unique ID that links geographies together and across time, back to 1991. In addition to the census, there are also environmental and election datasets.
Polygon boundaries can be downloaded as shapefiles or geopackages, and tabular data is available in CSV and DTA (STATA) formats. Researchers can also contribute data created from their own research to the repository.
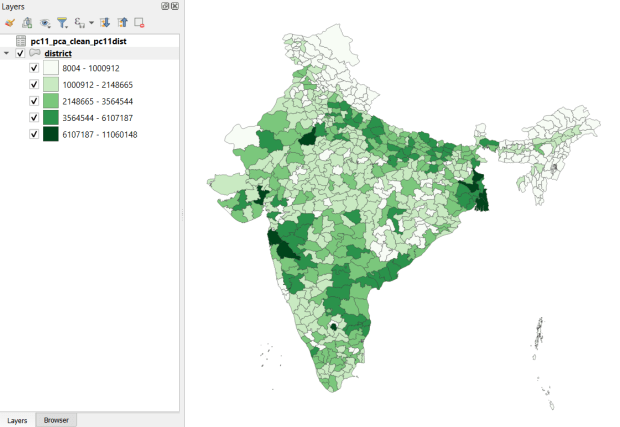
SHRUG India Districts Total Population Data from 2011 Census in QGIS
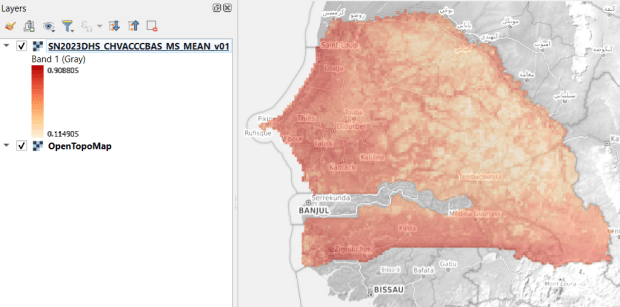
USAID published the detailed Demographic and Health Surveys (DHS) as far back as the mid 1980s for many of the world’s low and middle income countries. The surveys captured information about fertility, family planning, maternal and child health, gender, HIV/AIDS, literacy, malaria, nutrition, and sanitation. A selection of different countries were surveyed each year, and for most countries data was captured at two or three different points in time over a 40 year period. While researchers had to submit proposals and request access to the microdata (individual person and household level responses), the agency generated population-level estimates for countries and country subdivisions that were readily downloadable. They also generated rasters that interpolated certain variables across the surface of a country (the header image for this post is a raster of Senegal in 2023, illustrating the percentage of children aged 12-36 months who are vaccinated for eight fundamental diseases, including measles and polio). The rasters, boundary files, and a selection of survey indicators pre-joined to country and subdivision boundaries were published in their Spatial Data Repository. You could access the full range of population indicators as tables from a point and click website, or alternatively via API.
I’m writing in the past tense, as USAID has been decimated and de-funded by DOGE. There is currently no way to request access to the microdata. The summary data is still available on the USAID website (via links in the previous paragraph), but who knows for how long. As part of the Data Rescue Project, I captured both the Spatial Data Repository and the Indicators data, and posted them on DataLumos, an archive of archived federal government datasets. You can download these datasets in bulk from DataLumos, from the links under the title for this section. Unfortunately this series is now an archive of data that will be frozen in time, with no updates expected. The loss of these surveys is not only detrimental to researchers and policymakers, but to millions of the world’s most vulnerable people, whose health and well-being were secured and improved thanks to the information this data provided.
USAID Country Subdivisions in QGIS where Recent Data is Available on % Children who are Vaccinated
In my previous post, I summarized several efforts to rescue and preserve US federal government datasets that are being removed from the internet. In this post, I’ll provide a basic primer on screen scraping with Python, which is what I’ve used to capture datasets in participating in the Data Rescue Project. Screen scraping can employed to many ends, such as capturing text on web pages so it can be analyzed, or taking statistics embedded in HTML tables and saving them in machine readable formats. In the context of this post, screen scraping is an approach for downloading data and documentation files stored on websites.
There are several benefits to using a scripting approach for this work. It saves you from the tedious task of clicking and downloading files one by one. The script serves as documentation for what you did, and allows you to easily repeat the process in the future, if the datasets continue to exist and are updated. A scripted, screen-scraping approach may not be best or necessary if the website and datasets are relatively small and simple, or conversely if the site is complicated and difficult to scrape given the technology it employs. In both cases, manual downloading may be quicker, especially with a team of volunteers. Furthermore, if it seems clear that the dataset or website are not going to be updated, or are going to vanish, then the benefit of repeating the process in the future is moot.
In this example, we’ll assume that screen scraping is the way to go, and we’ll use Python to do it. I’ll address a few alternatives to this approach at the end, the primary one being using an API if and when it’s available, and will share links to working code that colleagues and I have written to save datasets.
You should only apply these approaches to public, open data. Capturing restricted or proprietary information violates licenses, terms of service, and in some cases privacy constraints, and is not condoned by any of the rescue projects. Even if the data is public, bear in mind that scraping can put undue pressure on web servers. For large websites, plan accordingly by building pauses into the process, breaking up the work into segments, or running programs at non-peak times (overnight). When writing and testing scripts, don’t repeat the process over and over again on the entire website; run your tests on samples until you get everything working.
Screen Scraping Basics
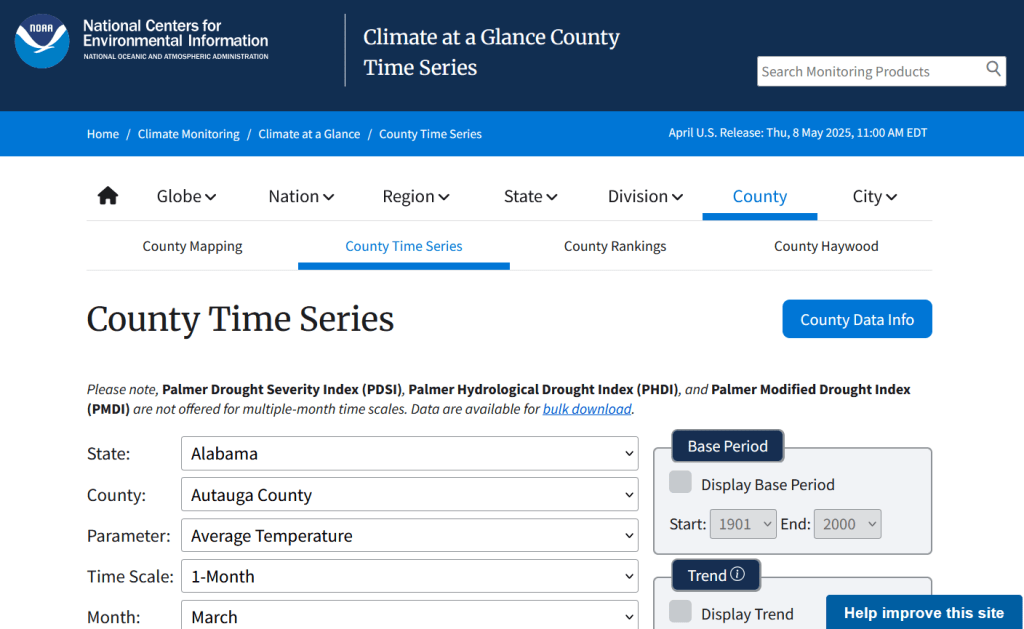
The first step is to explore the website where the data is hosted, to identify the best pages to use as a source and determine the feasibility of the approach. Many websites will have feature rich, user friendly pages that make it easy to view extracts of data and visualize it, such as the NOAA climate website below.
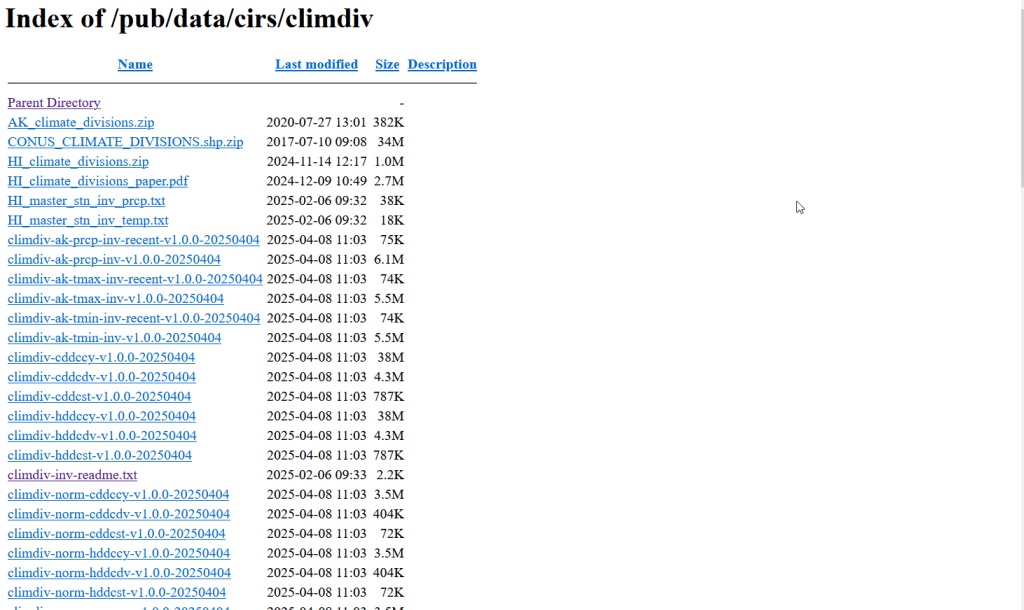
While easy to use, these pages can be complex and tedious to scrape. Always look for an option for bulk downloading datasets. They may lead you to a page sitting behind the scenes of the fancy website, such as the NOAA file directory below. Saving data from a page like this is fairly straightforward.
For the benefit of those of you who are not 1990s era people like myself and may not be familiar with working with HTML, the example below illustrates a simple webpage. With any browser, you can right click on a page and View the Source, to see the HTML code and stylesheets behind the page, which the browser processes and renders to display the site. HTML is a markup language where text is enclosed in tags that tell us something about the content within the tags, and which can be used for displaying the content in different ways. HTML is also hierarchical, so that content can be nested. For example, there is a head section that contains preliminary content about the page, and a body section that encloses the main content. Within the body there can be divisions, and anchor tags that represent links. In this example, one of these anchors is a link to a data file that we want to download.
We can use Python to parse these tags and pull out desired content. There are four core modules I always use: Requests for downloading content, os for creating folders and working with paths, Beautiful Soup for screen scraping, and datetime for creating time stamps. In the code below, we begin by importing the modules and saving the url of the page we wish to scrape as a variable.
In most Python environments (unless you’ve modified some settings) it’s assumed that your current working directory is the folder where your Python script is stored. When you download files, they will automatically be stored in that folder. To keep things tidy, I always create a subfolder named with the date; I use the date function from datetime to retrieve today’s date, append that date to the word “downloaded-‘, and use the os module to create a subfolder with that name. If we run the program at a later date it will save everything in a new folder, rather than overwriting existing files.
import requests, os
from bs4 import BeautifulSoup as soup
from datetime import date
url='https://www.page.gov'
today = str(date.today())
outfolder='downloaded-'+today
if not os.path.exists(outfolder):
os.makedirs(outfolder)
webpage=requests.get(url).content
soup_page=soup(webpage,'html.parser')
page_title = soup_page.title.text
container=soup_page.find('div',{'class':'content'})
links=container.findAll('a')
The final block in this example captures data from the website. We use requests to get the content stored at the url (the webpage), and then we pass this to Beautiful Soup, which parses all the HTML using their tags. Once parsed, we can retrieve specific objects. For example, we can save the page title (the text that appears in the heading of your browser for a particular site) as a variable. We also grab the section of the page that contains the links we want to capture by looking for a specific div or id tag. This isn’t strictly necessary for simple pages like this one, but speeds up processing for larger, more complex pages. Lastly, we can search through that specific container to find all the anchor tags, or links.
Once we have the links, we loop through and save the ones we want. My preference is to store them in a dictionary as key / value pairs, where the key is the name of the file, and the value is the file’s URL. We iterate through the links we saved, and with the soup we determine if the link has an ‘href’ attribute. If it does, we see if it ends with .zip, which is the data file. This skips any link that’s not a file we want, including links that go to other webpages as opposed to files. In practice, I provide a list of several file types here such as .zip, .csv, .txt, .xlsx, .pdf, etc to capture anything that could be data or documentation. If we find the zip, we split the link’s attributes from one string of text into a list of strings that are separated by the backslash, and grab the last element, which is the name of the file. Lastly, we add this to our datalinks dictionary; in this example, we’d have: {'data.zip':'https://www.page.gov/data.zip'}.
datalinks={}
for lnk in links:
if 'href' in lnk.attrs:
if lnk.attrs['href'].endswith(('.zip')):
fname=lnk.attrs['href'].split('/')[-1]
datalinks[fname]=lnk.attrs['href']
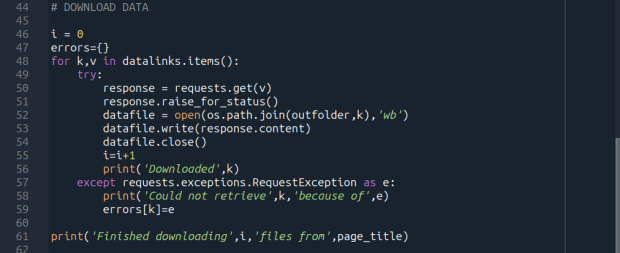
Time to download! We loop through each key (file name) and value (url) in our dictionary. We use the requests module to try and get the url (v), but if there’s a problem with the website or the link is invalid we bail out. If successful, we use the os module to go to our output folder and we supply the name of the file from the website (k) as the name of the file that we want to store on our computer. The ‘wb’ parameter specifies that we’re writing bytes to a file. I always like to keep count of the number of files I’ve done with an iterator (i) so I can print messages to a screen or a log file.
i = 0
for k,v in datalinks.items():
try:
response=requests.get(v)
response.raise_for_status()
dfile=open(os.path.join(outfolder,k),'wb')
dfile.write(response.content)
dfile.close()
i=i+1
print('Downloaded',k)
except requests.exceptions.RequestException as e:
print('Could not get',k,'because of',e)
print('Downloaded',i,'files from',page_title)
It’s important to save documentation too, so people can understand how the data was created and structured. In addition to saving pdf and text files, you can also save a vanilla copy of the website; I use a generic name with a date stamp. This saves the basic HTML text of the page, but not any images, documents, or styling. Which is usually good enough for providing documentation.
As mentioned previously, you don’t want to place undue burden on the webserver. With the time module, you can use the sleep function and add a pause to your script for a fixed amount of time, usually at the end of a loop, or after your iterator has recorded a certain number of files. The random module allows you to supply a random time value within a range, if you want to vary the length of the pause.
import time
from random import randint
# Pause fixed amount
time.sleep(5)
# Pause random amount within a range
time.sleep(randint(10,20))
Screen Scraping Caveats
Those are the basics! Now here are the primary exceptions. The first problem is that links to files may not be absolute links that contain the entire path to a file. Sometimes they’re relative, containing a reference to just the subfolder and file. The requests module won’t be able to find these, so we have to take the extra step of building the full path, as in the example below. You can do this by identifying what the relative path starts with (unless they’re all relative and the same), and you create the absolute by adding (concatenating) the root url and the relative one contained in the soup.
<div class='content'>
<p>Paragraph with text.</p>
<a href='/us/data.zip'/>
</div>
url='https://www.page.gov'
datalinks={}
for lnk in links:
if lnk.attrs['href'].endswith(('.zip')):
if lnk.attrs['href'].startswith('/us/'):
fname=lnk.attrs['href'].split('/')[-1]
datalinks[fname]=url+lnk.attrs['href']
...
In other cases, a link to a data file may not lead directly to the file, but leads to another web page where that file is stored. We can embed another scraping block into a loop; retrieve and start scraping the main page, then once you find a link go to that page, and repeat retrieval and scraping. In these cases, it’s best to save these steps in a function, so you can call the function multiple times instead of repeating the same code.
<div class='content'>
<p>Paragraph with text.</p>
<a href='https://www.page.gov/us/'>
</div>
Some websites will have dedicated pages where they embed a parameter in the url, such as codes for countries or states. If you know what these are, you can define them in a list, and iterate through that list by formatting the url to insert the code, and then scrape that page. If a page uses a unique integer as an ID and you know what the upper limit is, you can use for i in range(1,n) to step through each page (but make sure you handle exceptions, in case an integer isn’t used or is missing).
codes=['us','ca','mx']
url='https://www.page.gov/{}'
for c in codes:
webpage=requests.get(url.format(c)).content
soup_page=soup(webpage,'html.parser')
...
For complicated sites with several pages, you might not want to dump all the files into the same folder. Instead, as you iterate through pages, you can create a dedicated folder for that iteration. Using the example above, if there is a page for each country code, you can create a folder for that code and when writing files, use the path module to store files in that folder for that iteration.
codes=['us','ca','mx']
for c in codes:
...
cfolder=os.path.join(outfolder,c)
if not os.path.exists(cfolder):
os.makedirs(cfolder)
...
response=requests.get(v)
response.raise_for_status()
dfile=open(os.path.join(cfolder,k),'wb')
dfile.write(response.content)
dfile.close()
For websites with lots of files, or with a few big files, you may run out of memory during the download process and your script will go kaput. To avoid this, you can stream a file in chunks instead of trying to download it in one go. Use the request module’s iter_content function, and supply a reasonable chunk size in bytes (10000000 bytes is 10 MB).
...
try:
with requests.get(v,stream=True) as response:
response.raise_for_status()
fpath=os.path.join(outfolder,k)
with open(fpath,'wb') as writefile:
for chunk in response.iter_content(chunk_size=10000000):
writefile.write(chunk)
i=i+1
print('Downloaded',k)
except requests.exceptions.RequestException as e:
print('Could not get',fname,'because of',e)
If you view the page source for a website, and don’t actually see the anchor links and file names in the HTML, you’re probably dealing with a page that employs JavaScript, which is a show stopper if you’re using Beautiful Soup. There may be a dropdown menu or option you have to choose first, in order to render the actual page (and you may be able to use the page parameters trick above, if the url on each page varies). But you may be stuck; instead of links, there may be download buttons you have to press or a dropdown menu option you have to choose in order to download the file.
One option would be to use a Python module called Selenium, which allows you to automate the process of using a web browser, to open a page, find a button, and click it. I’ve tried Selenium with some success, but find that it’s complex and clunky for screen scraping. It’s browser dependent (you’re automating the use of a browser, and they’re all different), and you’re forced to incorporate lots of pauses; waiting for a page to load before attempting to parse it, and dealing with pop up menus in the browser as you attempt to download multiple files, etc.
Another option that I’m not familiar with, and thus haven’t tried, would be to use JavaScript since that’s what the page uses. Most browsers have web developer console add-ons that allow you to execute snippets of JavaScript code in order to do something on a page. So some automation may be possible.
Using an API
You may be able to avoid scraping altogether if the data is made available via an API. With a REST API, you pass parameters into a base link to make a specific request. Using requests, you go to that URL, and instead of getting a web page you get the data that you’ve asked for, usually packaged in a JSON type object within your program (Python or another scripting language). Some APIs retrieve documents or dataset files, that you can stream and download as described previously. But most APIs for statistical data retrieve individual data records, which you would store in a nested list or dictionary and then write out to a CSV. The example below grabs the total population for four large cities in Rhode Island from 2020 decennial census public redistricting dataset.
import requests,csv
year='2020'
dsource='dec' # survey
dseries='pl' # dataset
cols='NAME,P1_001N' # variables
state='44' # geocodes for states
place='19180,54640,59000,74300' # geocodes for places
outfile='census_pop2020.csv'
keyfile='census_key.txt'
with open(keyfile) as key:
api_key=key.read().strip()
base_url = f'https://api.census.gov/data/{year}/{dsource}/{dseries}'
# for sub-geography within larger geography - geographies must nest
data_url = f'{base_url}?get={cols}&for=place:{place}&in=state:{state}&key={api_key}'
response=requests.get(data_url)
popdata=response.json()
for record in popdata:
print(record)
with open(outfile, 'w', newline='') as writefile:
writer=csv.writer(writefile, quoting=csv.QUOTE_MINIMAL, delimiter=',')
writer.writerows(popdata)
The benefit of an API is that it’s designed to retrieve machine readable data, and might be easier than scraping pages that have complex interfaces. The major downside is, if you’re forced to download individual records as opposed to entire files, the process can take a long time, to the point where it may be infeasible if the datasets are too large. It’s always worth checking to see if there is a bulk download option as that could be easier and more efficient (for example, the Census Bureau has an FTP site for downloading datasets in their entirety). Using an API also requires you to invest time in studying how it works, so you can build the appropriate links and ensure that you’re capturing everything.
Conclusion
Screen scraping will vary from website to website, but once you have enough examples it becomes easy to resample your code. You’ll always need to modify the Beautiful Soup step based on the structure of the individual pages, but the requests downloading step is more rote and may not require much modification. While I use Python, you can use other languages like R to achieve similar results.
Visit my library’s US Federal Government Data Backup GitHub for working examples of code that I and colleagues have used to capture datasets. In my programs I’ve added extra components, like writing a basic metadata file and error logs, which I haven’t covered in this post. The NOAA County at a Glance, IRS-SOI, and IMLS, scripts are basic examples, and the IMLS ones include some of the caveats I’ve described. The NOAA lake and sea level rise scripts are far more complex, and include cycling through many pages, creating multiple folders, streaming downloads, and encapsulating processes into functions. The USAID DHS Indicators scripts used APIs that retrieved files, while the USAID DHS SDR script used Selenium to step through a series of JavaScript pages.
You’ll find scripts but no datasets in the GitHub repo due to file size limitations. If you’re a member of an institution that has access to GLOBUS, you can access the data files by following the instructions at the top of the page. Otherwise, we’ve contributed all of our datasets to DataLumos (except for the sea level rise data, I’m working with another university to host that).
There’s been a lot of turmoil emanating from Washington DC lately. One development that’s been more under the radar than others has been the modification or removal of US federal government datasets from the internet (for some news, see these articles in the New Yorker, Salon, Forbes, and CEN). In some cases, this is the intentional scrubbing or deletion of datasets that focus on topics the current administration doesn’t particularly like, such as climate and public health. In other cases, the dismemberment of agencies and bureaus makes data unavailable, as there’s no one left to maintain or administer it. While most government data is still available via functioning portals, most of the faculty and researchers I work with can identify at least a few series they rely on that have disappeared.
Librarians, archivists, researchers, professors, and non-profits across the country (and even in other parts of the world), have established rescue projects, where they are actively downloading and saving data in repositories. I’ve been participating in these efforts since January, and will outline some of the initiatives in this post.
The Internet Archive
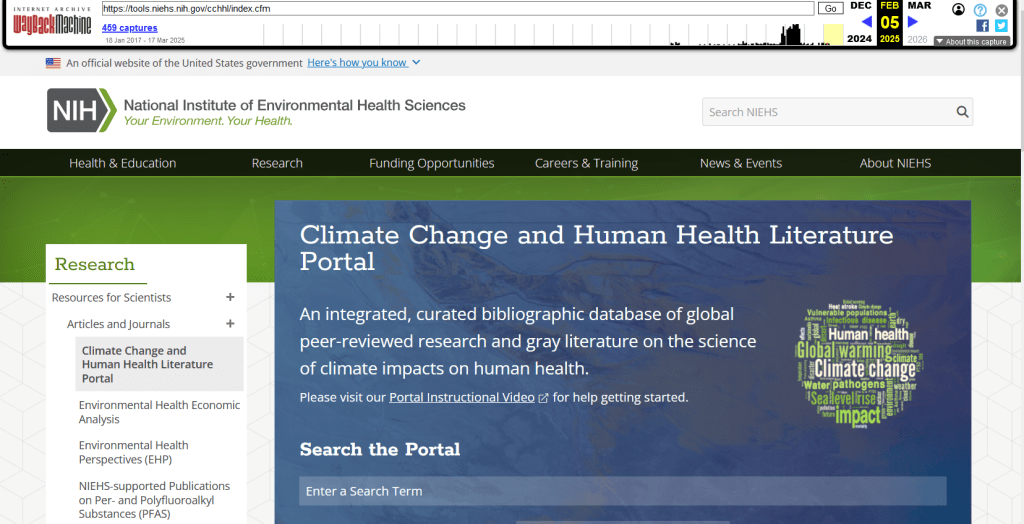
The place of last resort for finding deleted web content is the Internet Archive. This large, non-profit project has been around as long as the web has existed, with the goal of creating a historic archive of the internet. It uses web crawlers or spiders to creep across the web and make copies of websites. With the Wayback Machine, you can enter a URL and find previous copies of web pages, including sites that no longer exist. You’re presented with a calendar page where you can scroll by year and month to select a date when a page was captured, which opens up a copy.
This allows you to see the content, navigate through the old website, and in many cases download files that were stored on those pages. It’s a great resource, but it can’t capture everything; given the variety and complexity of web pages and evolving web technologies, some websites can’t be saved in working order (either partially or entirely). Content that was generated and presented dynamically with JavaScript, or was pulled and presented from a database, is often not preserved, as are restricted pages that required log-ins.
An archived copy of the NIEHS page (the actual website was deleted in mid February 2025)
The Internet Archive also hosts a number of special collections where folks have saved documents, images, sound and video, and software. For example, you can find many research articles that are available in PubMed from the PubMed Central collection, a ton of documents from the USDA’s National Agricultural Library, and about 100 GB of data someone captured from the CDC in January 2025. A large project called the End of Term Archive was launched in 2008 to capture what federal government websites looked like at the end of each presidential term. The pages are saved in a special collection in the IA.
Data Rescue Project
Dozens of new data archiving projects were launched at the end of 2024 and beginning of 2025 with the intention of saving federal datasets. The Data Rescue Project is one of the larger efforts, which has been driven by data librarians and archivists with non-profit partners. Professional groups including IASSIST, ICPSR, RDAP, the Data Curation Network, and the Safeguarding Research & Culture project have been active organizers and participators. While this will be an oversimplification, I’ll summarize the project as having two goals
The first goal is to keep track of what the other archiving projects are, and what they have saved. To this end, they created the Data Rescue Tracker, which has two modules. The Downloads List is an archive of datasets that have been saved, with details about where the data came from and locations of archived copies. The Maintainers List is a catalog of all the different preservation projects, with links to their home pages. There is also a narrative page with a comprehensive list of links to the various rescue efforts, data repositories, alternate sources for government data, and tools and resources you can use to save and archive data.
The Data Rescue Tracker Downloads List
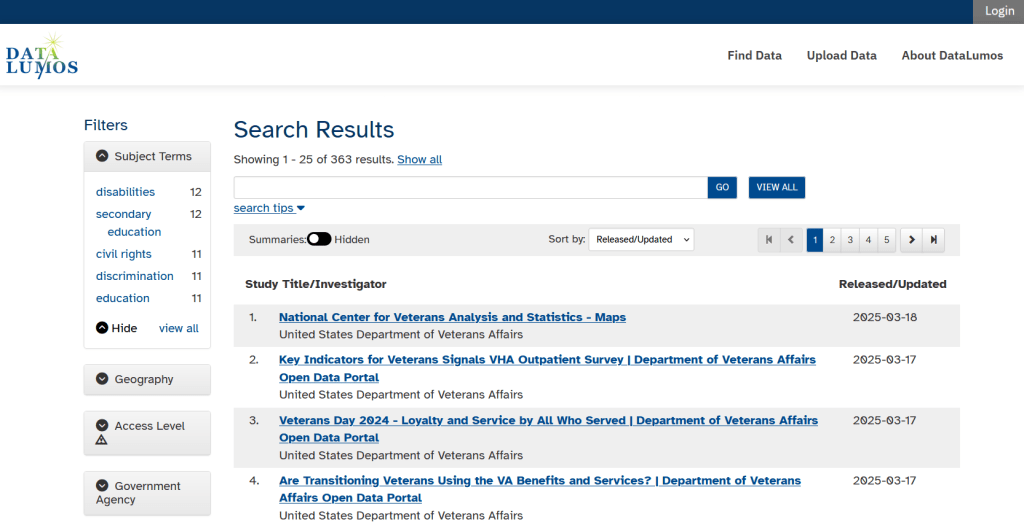
The second goal is to contribute to the effort of saving and archiving data. The team maintains an online spreadsheet with tabs for agencies that contain lists of datasets and URLs that are currently prioritized for saving. Volunteers sign up for a dataset, and then go out and get it. Some folks are manually downloading and saving files (pointing and clicking), while others write short screen scraping scripts to automate the process. The Data Rescue Project has partnered with ICPSR, a preeminent social science research center and repository in the US, at the University of Michigan. They created a repository called DataLumos, which was launched specifically for hosting extracts of US federal government data. Once data is captured, volunteers organize it and generate metadata records prior to submitting it to DataLumos (provided that the datasets are not too big).
DataLumos archive for federal government datasets, maintained by ICPSR
Most of the datasets that DRP is focused on are related to the social sciences and public policy. The Data Rescue Project coordinates with the Environmental and Government Data Initiative and the Public Environmental Data Partners (which I believe are driven by non-profit and academic partners), who are saving data related to the environment and health. They have their own workflows and internal tracking spreadsheets, and are archiving datasets in various places depending on how large they are. Data may be submitted to the Internet Archive, the Harvard Dataverse, GitHub, SciOp, and Zenodo (you can find out where in the Data Rescue Tracker Download’s List).
Mega Projects
There are different approaches for tackling these data preservation efforts. For the Data Rescue Project and related efforts, it’s like attacking the problem with millions of ants. Individual people are coordinating with one another in thousands of manual and semi-automated download efforts. A different approach would be to attack the problem with a small herd of elephants, who can employ larger resources and an automated approach.
For example, the Harvard Law School Library Innovation Lab launched the Archive of data.gov, a large project to crawl and download everything that’s in data.gov, the US federal government’s centralized data repository. It mirrors all the data files stored there and is updated regularly. The benefit of this approach is that it captures a comprehensive amount of data in one go, and can be readily updated. The primary limitation is that there are many cases where a dataset is not actually stored in data.gov, but is referenced in a catalog record with a link that goes out to a specific agency’s website. These datasets are not captured with this approach.
If trying to find back-ups is a bit bewildering, there’s a tool that can help. Boston University’s School of Public Health and Center for Health Data Science have created a find lost* data search engine, which crawls across the Harvard Project, DataLumos, the Data Rescue Project, and others.
Beyond the immediate data preservation projects that have sprung up recently, there are a number of large, on-going projects that serve as repositories for current and historical datasets. Some, like IPUMS at the University of Minnesota and the Election Lab at MIT focus on specific datasets (census data for the former, election results data for the latter). There are also more heterogeneous repositories like ICPSR (including OpenICPSR which doesn’t require a subscription), and university-based repositories like the Harvard Dataverse (which includes some special collections of federal data extracts, like CAFE). There are also private-sector partners that have an equal stake in preserving and providing access to government data, including PolicyMap and the Social Explorer.
Wrap-up
I’ve been practicing my Python screen scraping skills these past few months, and will share some tips in a subsequent post. I’ve been busy contributing data to these projects and coordinating a response on my campus. We’ve created a short list of data archives and alternative sources, which captures many of the sources I’ve mentioned here plus a few others. My library colleagues in the health and medical sciences have created a list of alternatives to government medical databases including PubMed and ClinicalTrials.gov
Having access to a public and robust federal statistical system is a non-partisan issue that we should all be concerned about. Our Constitution justifies (in several sections) that we should have such a system, and we have a large body of federal laws that require it. Like many other public goods, the federal statistical system contributes to providing a solid foundation on which our society and economy rest, and helps drive innovation in business, policy, science, and medicine. It’s up to us to protect and preserve it.
I’m often asked about what the best approaches are for comparing US census data over time, to account for changes in census geography and to limit the amount of data processing you have to do in stitching data from different census years together. Census geography changes significantly each decade, and by and large the Census Bureau does not compile and publish historical comparison tables.
My primary suggestion is to use the National Historical Geographic Information System or NHGIS (I’ll mention some additional suggestions at the end of this post). Maintained by IPUMS at the University of Minnesota, NHGIS is the repository for all historic US census summary data from 1790 to present. While most of the data in the archive is published nominally (the format and structure in which the data was originally published), they do publish a set of Time Series Tables that compile multiple years of census data in one table. These tables come in two formats:
Nominal tables: the data is published “as is”, based on the boundaries that existed at each point in time. If a geography was added or dropped over the course of the years, it falls in or out of the table in the given year that the change occurred. With a few exceptions, the earliest nominal tables begin with the 1970 census and are published for eight geographies: nation, regions, divisions, states, counties, census tracts, county subdivisions, and places.
Standardized tables: the data has been normalized, where a geography for a single time period serves as the basis for all data in the table. The NHGIS is currently using 2010 as the basis, so that data prior and subsequent to 2010 has been modified to fit within the 2010 boundaries. This is achieved by aggregating block or block group data from each period to fit within the 2010 boundaries, and apportioning the data in cases where a block or group is split by a boundary. The earliest standardized tables begin with the 1990 census, and cover the basic 100% count data. Data is published for ten geographies: states, counties, census tracts, block groups, county subdivisions, places, congressional districts (as defined for the 110th-112th Congresses, 2007-2013), core based statistical areas (using 2009 metro area definitions), urban areas, and ZIP Code Tabulation Areas (ZCTAs).
Included in the documentation is a full list of time series tables, and whether they are available in nominal or standardized format. The availability of specific time periods and geographies varies. As of late 2024, the availability of standardized tables that include the 2020 census is currently limited to what was published in the early Public Redistricting Files. This will likely change in the near future to include additional 2020 data, and it’s possible that the standardized geography will eventually switch from 2010 to 2020 geography.
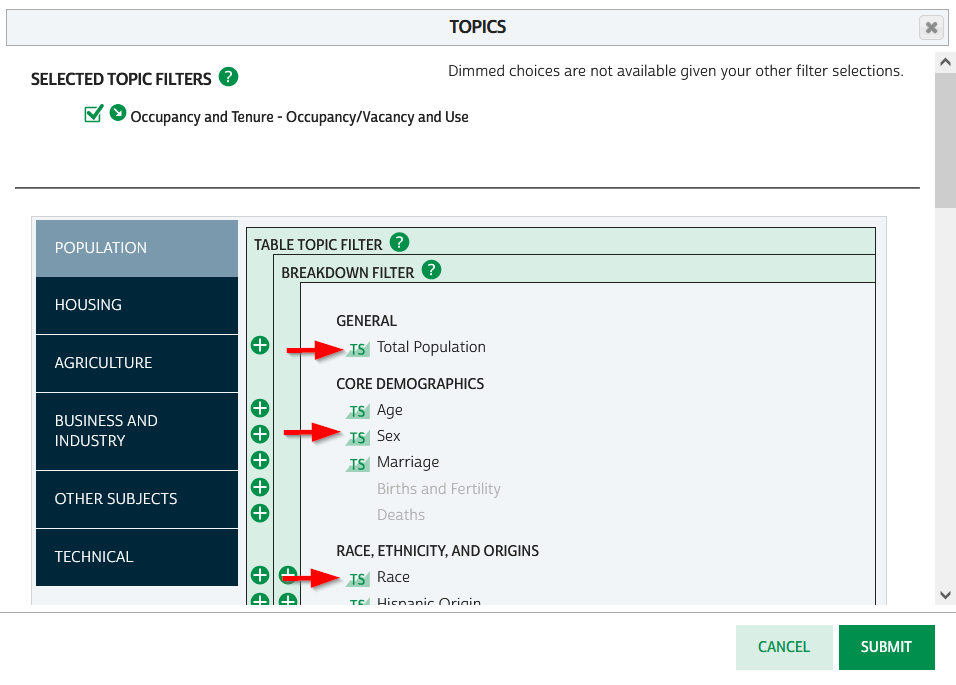
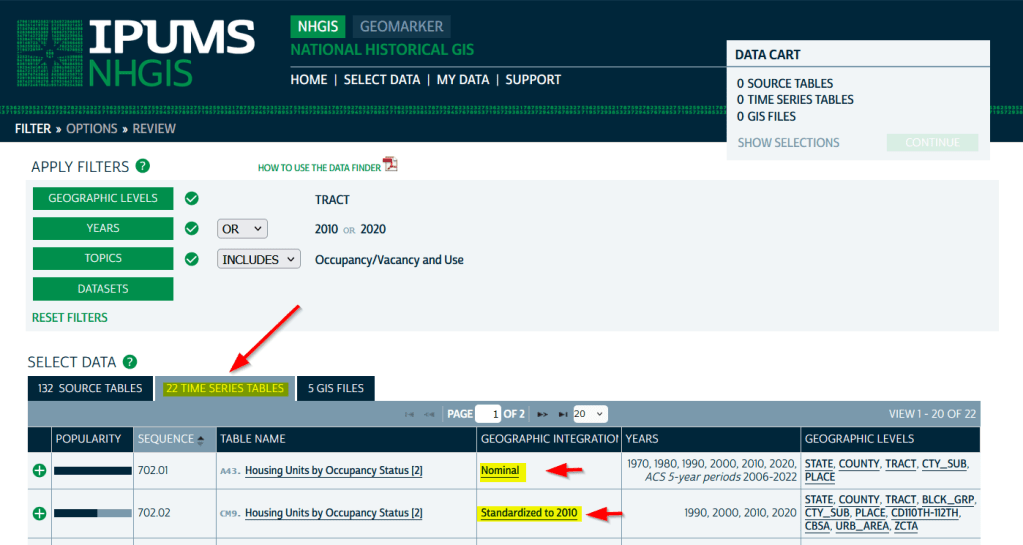
To access the Time Series Tables, you can browse the NHGIS without an account but you’ll need to create one in order to download anything. Once you launch NHGIS click on the Topics filter. In the list of topics, any topic under the Population or Housing category that has a “TS” flag next to it has at least one time series table. In the example below, I’ve used the filters to select census tracts for Geographic Level, 2010 and 2020 for Years, and Housing – Occupancy and Vacancy status as my Topic.
In the results at the bottom, the original Source Tables from each census are shown in the first tab. The Time Series Tables can be viewed by selecting the adjacent tab. The first two tables in this example are Housing Units by Occupancy Status. Clicking on the name of the tables reveals the variables that are included, and the source for the statistics. The first table is a nominal one that stretches from 1970 to the most recent ACS. The second table is a standardized one that covers 1990 to 2020. I’ve checked both boxes to add these to my cart.
The third tab in the results are GIS Files. If we want to map standardized data, we would choose just the boundaries for the standardized year, as all of the data in the table has been modified to fit these boundaries. If we were mapping nominal data, we would need to download boundary files for each time period and map them separately (unless they were stable geographies like states that haven’t changed since 1970).
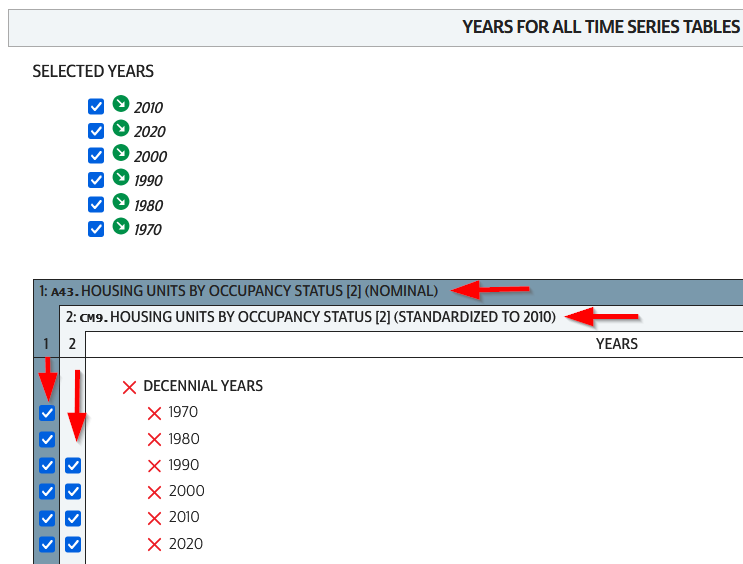
We hit the Continue button in the Cart panel when we’re ready to download. By default the extract will only include years and geographies we have filtered for. To add additional years or geos we can add them on this next screen. I’ve modified my list to get all available decennial years for each table. Note that if you’re going to select 5-year ACS data for nominal tables, choose only a few non-overlapping periods. In most cases you can’t filter geographies (i.e. select tracts within a state), you have to take them all. On the final screen you choose your structure; CSV is usually best, as is Time varies by column. Once you submit your request you’ll be prompted to log in if you haven’t already done so. Wait a bit for the extract to compile, then you can download the table and codebook.
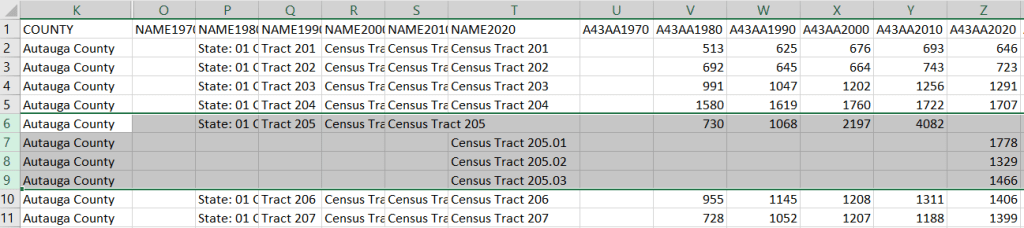
A portion of the nominal table is depicted below. This table includes identifiers and labels for each of the census years. The variables follow, ordered by variable and then by year. In this example, occupied housing units from 1970 to 2020 appear in the first block, and vacant units in the second. All the 1970 census tract values for Autauga County, Alabama are blank (as many rural counties in 1970 were un-tracted). We can see that values for census tract 205 run only from 1980 to 2010, with no value for 2020. The tract was split into three parts in 2020, and we see values for tracts 205.01, .02, and .03 appear in 2020. So in the nominal tables, geographies appear and disappear as they are created or destroyed. However, if geographic boundaries change but the name and designation for the geography do not, that geography persists throughout the time series in spite of the change.
A portion of the standardized table is below. This table only includes identifiers and labels for the 2010 census, as all data was modified to fit the tract geography of that year. The values for each census year except 2010 are published in triplicate: an estimate, and a lower and upper bound for the estimate. If the values in these three columns differ, it indicates that a block (or block group) was split and reapportioned to fit within the tract boundary for 2010 (you may also see decimals, indicating a split occurred). You’d use the estimate in your work, while the bounds provide some indication of the estimate’s accuracy. Note in this table, tract 205 in Autauga County persists from 1990 to 2020, as it existed in 2010. Data from the three 2020 tracts was aggregated to fit the 2010 boundary.
The crosswalk tables that IPUMS used to create the standardized data are available, if you wanted or needed to generate your own normalized data. The best approach is to proceed from the bottom up, aggregating blocks to reformulate the data to the geography you wish to use. Some decennial census data, and all data from the ACS, is not available at the block level, which necessitates using block groups instead.
There are some alternatives for obtaining or creating time series census data, which could fit the bill depending on your use case (esp if you are looking at larger geographies). There’s also reference material that can help you make sense of changes.
The Longitudinal Tract Database at Brown University provides tract-level crosswalks from 1970 to 2020. They also provide some pre-compiled data tables generated from the crosswalk.
Use an interactive mapping tool like the Social Explorer to make side by side comparison maps from two time periods. They also incorporate some of the NHGIS standardized data into their database. (SE is a subscription-based product; if you’re at a university see if your library subscribes).
I recently had a question about finding historic climate data in the United States at the county-level. In this post I’ll show you how to access it, and how to parse fixed-width text files in Excel. Weather data is captured and reported by point-based weather stations, and then is often interpolated and modeled over gridded surfaces (rasters). The National Centers for Environmental Information at NOAA have used their models to create zonal statistics for counties, which they publish via the Climate at a Glance County Mapping program (I described what zonal statistics are in an earlier post).
The basic application lets you map the continental US or an individual state (includes AK but not HI). You choose a parameter (Avg / Min / Max temperature, precipitation, cooling / heating days, drought indexes), year (1895 to present), month, and time scale (1 month to 5 years). This creates a map that you can modify to depict that value, or to display ranks or anomalies. You can download the map as an image, or the underlying data as CSV or JSON.
A separate app allows you to create a time series profile for a particular county, with a table, chart, and data that you can download.
These apps are great for the basics, but bulk downloading the underlying data for all counties and years is a bit trickier. You crash land in a file directory and have to choose from an array of zipped files. Fortunately there is good documentation. In that folder, these are the county-level files for precipitation, min temp, max temp, and avg temp:
climdiv-pcpncy-vx.y.z-YYYYMMDD
climdiv-tmaxcy-vx.y.z-YYYYMMDD
climdiv-tmincy-vx.y.z-YYYYMMDD
climdiv-tmpccy-vx.y.z-YYYYMMDD
Where v is for “version”, the xyz is a version number, and the final portion is the date. The archive is updated monthly. The other files in the directory are for climate divisions, states and regions, and data that pertains to the drought indexes. There are also files that have climate normals for each of these areas. If you’re interested in these, you can go up to the parent-level directory and view the relevant documentation.
The county files are fixed-width text files, which means you have to parse them to separate the values. If you treat them as delimited files (using spaces), then all of the fields at the beginning of the file will be lumped together, which is not useful. Spreadsheets and stats packages have tools for importing delimited text, or you could script something in Python or R. Modern versions of Excel will allow you to parse fixed-width data by supplying a list of endpoints for each column; older versions of Excel and other spreadsheets have you “eyeball” the columns and manually insert breaks in an import screen.
If you’re using a modern version of Excel: open a blank workbook and on the Data ribbon click the From Text/CSV button. Browse and select the county text file you’ve downloaded. In the import screen change the Delimiter drop down to Fixed Width.
In the box underneath, begin with zero and type the end points for each position (with the exception of the final endpoint, 95) as a comma separated list. You’ll find these in the README file, but I’ve also tacked on the most salient bits to the end of this post. For your convenience:
0,5,7,11,18,25,32,39,46,53,60,67,74,81,88
If you click on the preview grid, it will parse the columns.
In this example, I’m not parsing the state and county code separately, but am keeping them together to create a single unique identifier. Once everything is parsed, hit the Transform Data button. For column 1, hit the small 123 button, and change the option to Text, and choose Replace data.
This will preserve the leading zero in the state/county code. It’s important to do this, so the codes in this table with match the codes in other county data table or spatial data files that you may wish to join this table to. Do the same for the element code in column 2. The remaining Year and Month columns can be left alone, as they’re already appropriately saved as integers and decimals respectively.
Hit the Close and Load button in the upper left hand corner, and Excel will parse and load the data. It formats the columns and applies a filter option. To get rid of the styling and filter dropdowns, I’d copy the entire table, and do a Paste-Special-Values in a new worksheet. Then replace the generic column labels with these:
Save the file, and now you have something to work with. Each record represents the monthly temperature or precipitation for a particular county for a particular year. To create a unique record ID, you can concatenate the state/county code, element code, and year values. For GIS applications, you would need to pivot the data to a wide form, so that the year becomes a column to give you month-year as a column, and each row represents each county with no repeats. With over 120 years of monthly data, that would give you over 1500 columns – so filter out what you don’t need. The state / county code can be used to join the table to the Census Bureau’s Cartographic Boundary Files, using the CBF’s GEOID field.
When would you use this data? If you’re creating data profiles or are running a statistical analysis and are using counties as your geographic unit, and temperature or precipitation is one variable among many that you need. Or, you’re making a series of county-level maps, and this is one of your variables. This dataset is clearly pretty convenient for doing time series analyses, as compiling data for a times series is usually time consuming. The counties in this dataset represent present day boundaries, so normalizing geography over time isn’t necessary.
When not to use it? Counties vary in size and can encompass a great deal of internal variety in terms of elevation, land use and land cover, and proximity to / presence of water bodies, all of which impact the climate. So the weather in one part of a county could be quite different from another part. To capture these internal differences, it would be better to use gridded data, such as the 4×4 km rasters that PRISM produces for daily, monthly, annual, and normal summaries.
Gridded climate data and zonal stats derived from grids are estimates based on models; if you wanted or needed the actual measurements as they were recorded, you would need to go back and get point-based weather station data, from the Local Climatological Database for instance. There are a limited number of stations, and not one for every county. The closest station to a given place could be used to represent or approximate the weather for that place.
Codebook for county data files (extracted from README):
Element Record Name Position Element Description
STATE-CODE 1-2 as indicated in State Code Table as described in FILE 1. Range of values is 01-48.
DIVISION-NUMBER 3-5 COUNTY FIPS - Range of values 001-999.
ELEMENT CODE 6-7
01 = Precipitation
02 = Average Temperature
25 = Heating Degree Days
26 = Cooling Degree Days
27 = Maximum Temperature
28 = Minimum Temperature
YEAR 8-11 This is the year of record. Range is 1895 to current year processed.
Monthly Divisional Temperature format (f7.2) Range of values -50.00 to 140.00 degrees Fahrenheit. Decimals retain a position in the 7-character field. Missing values in the latest year are indicated by -99.99.
Monthly Divisional Precipitation format (f7.2) Range of values 00.00 to 99.99. Decimal point retains a position in the 7-character field. Missing values in the latest year are indicated by -9.99.
JAN-VALUE 12-18
FEB-VALUE 19-25
MAR-VALUE 26-32
APR-VALUE 33-39
MAY-VALUE 40-46
JUNE-VALUE 47-53
JULY-VALUE 54-60
AUG-VALUE 61-67
SEPT-VALUE 68-74
OCT-VALUE 75-81
NOV-VALUE 82-88
DEC-VALUE 89-95
Right before the semester began, I updated the Rhode Island maps on my census research guide so that they link to the recently released Demographic Profile tables from the 2020 Census. I feel like the release of the 2020 census has flown lower on the radar compared to 2010 – it hasn’t made it into the news or social media feeds to the same degree. It has been released much later than usual for a variety of reasons, including the COVID pandemic and political upheaval and shenanigans. At this point in Sept 2023, most of what we can expect has been released, and is available via data.census.gov and the census APIs.
Here are the different series, and what they include.
Redistricting data. Released in Aug 2021. Also known as PL 91-171 (for the law that requires it), this data is intended for redrawing congressional and legislative districts. It includes just six tables, available for several geographies down to the block level. This was our first detailed glimpse of the count. The dataset contains population counts by race, Hispanic and Latino ethnicity, the 18 and over population, group quarters, and housing unit occupancy. Here are the six US-level tables.
Demographic and Housing Characteristics File. Released in May 2023. In the past, this series was called Summary File 1. It is the “primary” decennial census dataset that most people will use, and contains the full range of summary data tables for the 2020 census for practically all census geographies. There are fewer tables overall relative to the 2010 census, and fewer that provide a geographically granular level of detail (ostensibly due to privacy and cost concerns). The Data Table Guide is an Excel spreadsheet that lists every table and the variables they include.
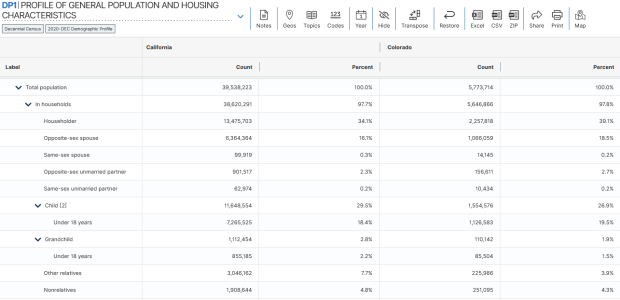
Demographic Profile. Released in May 2023. This is a single table, DP1, that provides a broad cross-section of the variables included in the 2020 census. If you want a summary overview, this is the table you’ll consult. It’s an easily accessible option for folks who don’t want or need to compile data from several tables in the DHC. Here is the state-level table for all 50 states plus.
Detailed Demographic and Housing Characteristics File A. Released in Sept 2023. In the past, this series was called Summary File 2. It is a subset of the data collected in the DHC that includes more detailed cross-tabulations for race and ethnicity categories, down to the census tract level. It is primarily used by researchers who are specifically studying race, and the multiracial population.
Detailed Demographic and Housing Characteristics File B. Not released yet. This will be a subset of the data collected in the DHC that includes more detailed cross-tabulations on household relationships and tenure, down to the census tract level. Primarily of interest to researchers studying these characteristics.
There are a few aspects of the 2020 census data that vary from the past – I’ll link to some NPR stories that provide a good overview. Respondents were able to identify their race or ethnicity at a more granular level. In addition to checking the standard OMB race category boxes, respondents could write in additional details, which the Census Bureau standardized against a list of races, ethnicities, and national origins. This is particularly noteworthy for the Black and White populations, for whom this had not been an option in the recent past. It’s now easier to identify subgroups within these groups, such as Africans and Afro-Caribbeans within the Black population, and Middle Eastern and North Africans (MENA) within the White population. Another major change is that same-sex marriages and partnerships are now explicitly tabulated. In the past, same-sex marriages were all counted as unmarried partners, and instead of having clearly identifiable variables for same-sex partners, researchers had to impute this population from other variables.
Another major change was the implementation of the differential privacy mechanism, which is a complex statistical process to inject noise into the summary data to prevent someone from reverse engineering it to reveal information about individual people (in violation of laws to protect census respondent’s privacy). The social science community has been critical of the application of this procedure, and IPUMS has published research to study possible impacts. One big takeaway is that published block-level population data is less reliable than in the past (housing unit data on the other hand is not impacted, as it is not subjected to the mechanism).
When would you use decennial census data versus other census data? A few considerations – when you:
Want or need to work with actual counts rather than estimates
Only need basic demographic and housing characteristics
Need data that provides detailed cross-tabulations of race, which is not available elsewhere
Need a detailed breakdown of the group quarters population, which is not available elsewhere
Are explicitly working with voting and redistricting
Are making historical comparisons relative to previous 10-year censuses
In contrast, if you’re looking for detailed socio-economic characteristics of the population, you would need to look elsewhere as the decennial census does not collect this information. The annual American Community Survey or monthly Current Population Survey would be likely alternatives. If you need basic, annual population estimates or are studying the components of population change, the Population and Housing Unit Estimates Program is your best bet.












You must be logged in to post a comment.