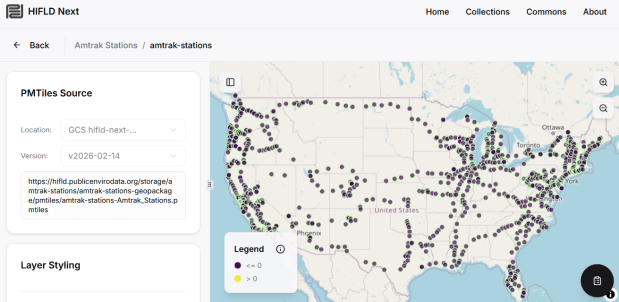
The Public Environmental Data Partners and Fulton Ring have launched a new community-shaped hub for finding, previewing and downloading GIS data collections, and its debut HIFLD Next collection is built on this rescued dataset. The portal increases the accessibility of the HIFLD Open data, with enhanced options for searching, previewing attribute tables and layers, and downloading or streaming data in a number of different formats. Beyond publishing a website, the group is hoping to build a community of practitioners around this project to support and sustain it, and to provide updated datasets and additional collections in the future.
They are keen to solicit feedback from GIS data users, and particularly from librarians and data specialists who provide active user support and who would potentially refer to the portal as a source. After you’ve explored the portal, feel free to submit feedback via their survey.
This project was an archival one, in that we were taking a final snapshot of what was in the repository before it went offline. In the coming year, I’ll be thinking about approaches for consistently capturing updates, and there are some folks who are interested in creating a community-driven portal to replace the defunct government site. Stay tuned!
2025 has been a tough year. Wishing you all the best for the year to come. – Frank
HIFLD Open, a key repository for accessing US GIS datasets on infrastructure, is shutting down on August 26, 2025. This is a revision from a previous announcement, which said that it would be live until at least Sept 30. The portal provided national layers for schools, power lines, flood plains, and more from one convenient location. DHS provides no sensible explanation for dismantling it, other than saying that hosting the site is no longer a priority for their mission (here’s a copy of an official announcement). In other words, “Public domain data for community preparedness, resiliency, research, and more” is no longer a DHS priority.
The 300 plus datasets in Open HIFLD are largely created and hosted by other agencies, and Open HIFLD was aggregating different feeds into one portal. So, much of the data will still be accessible from the original sources. It will just be harder to find.
DHS has published a crosswalk with links to alternative portals and the source feeds for each dataset, so you can access most of the data once Open HIFLD goes offline. I’ve saved a copy here, in case it also disappears. Most of these sources use ESRI REST APIs. Using ArcGIS Online or Pro, and even QGIS (for example), you can connect to these feeds, get a listing in your contents pane, and drag and drop layers into a project (many of the layers are also available via ArcGIS Online or the Living Atlas if you’re using Arc). Once you’ve added a layer to a project, you can export and save local copies.
Adding ArcGIS Rest Server for US Army Corps of Engineers Data in QGIS
If you want to download copies directly from Open HIFLD before it vanishes on Aug 26, I’ve created this spreadsheet with direct links to download pages, and to metadata records when available (some datasets don’t have metadata, and the links will bring you to an empty placeholder). Some datasets have multiple layers, and you’ll need to click on each one in a list to get to it’s download page. In some cases there won’t be a direct download link, and you’ll need to go to the source (a useful exercise, as you’ll need to remember where it is in the future). Alternatively, you can connect to the REST server (before Aug 26, 2025) in QGIS or ArcGIS, drag and drop the layers you want, and then export:
I’m coordinating with the Data Rescue Project, and we’re working on downloading copies of everything on Open HIFLD and hosting it elsewhere. I’ll provide an update once this work is complete. Even though most of these datasets will still be available from the original sources, better safe than sorry. There’s no telling what could disappear tomorrow.
The secure HIFLD site for registered users will remain available, but many of the open layers aren’t being migrated there (see the crosswalk for details). The secure site is available to DHS partners, and there are restrictions on who can get an account. It’s not exactly clear what they are, but it seems unlikely that most Open users will be eligible: “These instructions [for accessing a secure account] are for non-DHS users who support a homeland security or homeland defense mission AND whose role requires access to the Geospatial Information Infrastructure (GII) and/or any geospatial dashboards, data, or tools housed on the GII…“
There’s been a lot of turmoil emanating from Washington DC lately. One development that’s been more under the radar than others has been the modification or removal of US federal government datasets from the internet (for some news, see these articles in the New Yorker, Salon, Forbes, and CEN). In some cases, this is the intentional scrubbing or deletion of datasets that focus on topics the current administration doesn’t particularly like, such as climate and public health. In other cases, the dismemberment of agencies and bureaus makes data unavailable, as there’s no one left to maintain or administer it. While most government data is still available via functioning portals, most of the faculty and researchers I work with can identify at least a few series they rely on that have disappeared.
Librarians, archivists, researchers, professors, and non-profits across the country (and even in other parts of the world), have established rescue projects, where they are actively downloading and saving data in repositories. I’ve been participating in these efforts since January, and will outline some of the initiatives in this post.
The Internet Archive
The place of last resort for finding deleted web content is the Internet Archive. This large, non-profit project has been around as long as the web has existed, with the goal of creating a historic archive of the internet. It uses web crawlers or spiders to creep across the web and make copies of websites. With the Wayback Machine, you can enter a URL and find previous copies of web pages, including sites that no longer exist. You’re presented with a calendar page where you can scroll by year and month to select a date when a page was captured, which opens up a copy.
This allows you to see the content, navigate through the old website, and in many cases download files that were stored on those pages. It’s a great resource, but it can’t capture everything; given the variety and complexity of web pages and evolving web technologies, some websites can’t be saved in working order (either partially or entirely). Content that was generated and presented dynamically with JavaScript, or was pulled and presented from a database, is often not preserved, as are restricted pages that required log-ins.
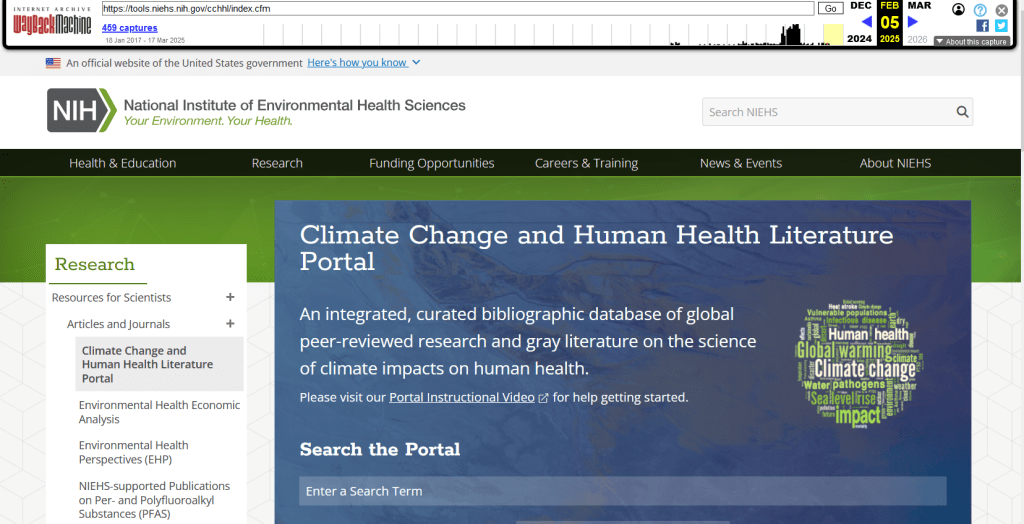
An archived copy of the NIEHS page (the actual website was deleted in mid February 2025)
The Internet Archive also hosts a number of special collections where folks have saved documents, images, sound and video, and software. For example, you can find many research articles that are available in PubMed from the PubMed Central collection, a ton of documents from the USDA’s National Agricultural Library, and about 100 GB of data someone captured from the CDC in January 2025. A large project called the End of Term Archive was launched in 2008 to capture what federal government websites looked like at the end of each presidential term. The pages are saved in a special collection in the IA.
Data Rescue Project
Dozens of new data archiving projects were launched at the end of 2024 and beginning of 2025 with the intention of saving federal datasets. The Data Rescue Project is one of the larger efforts, which has been driven by data librarians and archivists with non-profit partners. Professional groups including IASSIST, ICPSR, RDAP, the Data Curation Network, and the Safeguarding Research & Culture project have been active organizers and participators. While this will be an oversimplification, I’ll summarize the project as having two goals
The first goal is to keep track of what the other archiving projects are, and what they have saved. To this end, they created the Data Rescue Tracker, which has two modules. The Downloads List is an archive of datasets that have been saved, with details about where the data came from and locations of archived copies. The Maintainers List is a catalog of all the different preservation projects, with links to their home pages. There is also a narrative page with a comprehensive list of links to the various rescue efforts, data repositories, alternate sources for government data, and tools and resources you can use to save and archive data.
The Data Rescue Tracker Downloads List
The second goal is to contribute to the effort of saving and archiving data. The team maintains an online spreadsheet with tabs for agencies that contain lists of datasets and URLs that are currently prioritized for saving. Volunteers sign up for a dataset, and then go out and get it. Some folks are manually downloading and saving files (pointing and clicking), while others write short screen scraping scripts to automate the process. The Data Rescue Project has partnered with ICPSR, a preeminent social science research center and repository in the US, at the University of Michigan. They created a repository called DataLumos, which was launched specifically for hosting extracts of US federal government data. Once data is captured, volunteers organize it and generate metadata records prior to submitting it to DataLumos (provided that the datasets are not too big).
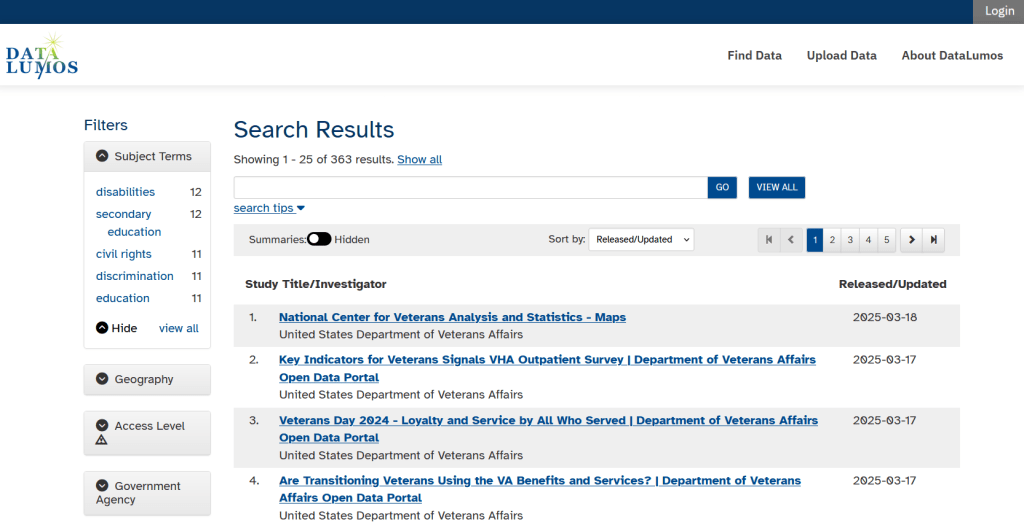
DataLumos archive for federal government datasets, maintained by ICPSR
Most of the datasets that DRP is focused on are related to the social sciences and public policy. The Data Rescue Project coordinates with the Environmental and Government Data Initiative and the Public Environmental Data Partners (which I believe are driven by non-profit and academic partners), who are saving data related to the environment and health. They have their own workflows and internal tracking spreadsheets, and are archiving datasets in various places depending on how large they are. Data may be submitted to the Internet Archive, the Harvard Dataverse, GitHub, SciOp, and Zenodo (you can find out where in the Data Rescue Tracker Download’s List).
Mega Projects
There are different approaches for tackling these data preservation efforts. For the Data Rescue Project and related efforts, it’s like attacking the problem with millions of ants. Individual people are coordinating with one another in thousands of manual and semi-automated download efforts. A different approach would be to attack the problem with a small herd of elephants, who can employ larger resources and an automated approach.
For example, the Harvard Law School Library Innovation Lab launched the Archive of data.gov, a large project to crawl and download everything that’s in data.gov, the US federal government’s centralized data repository. It mirrors all the data files stored there and is updated regularly. The benefit of this approach is that it captures a comprehensive amount of data in one go, and can be readily updated. The primary limitation is that there are many cases where a dataset is not actually stored in data.gov, but is referenced in a catalog record with a link that goes out to a specific agency’s website. These datasets are not captured with this approach.
If trying to find back-ups is a bit bewildering, there’s a tool that can help. Boston University’s School of Public Health and Center for Health Data Science have created a find lost* data search engine, which crawls across the Harvard Project, DataLumos, the Data Rescue Project, and others.
Beyond the immediate data preservation projects that have sprung up recently, there are a number of large, on-going projects that serve as repositories for current and historical datasets. Some, like IPUMS at the University of Minnesota and the Election Lab at MIT focus on specific datasets (census data for the former, election results data for the latter). There are also more heterogeneous repositories like ICPSR (including OpenICPSR which doesn’t require a subscription), and university-based repositories like the Harvard Dataverse (which includes some special collections of federal data extracts, like CAFE). There are also private-sector partners that have an equal stake in preserving and providing access to government data, including PolicyMap and the Social Explorer.
Wrap-up
I’ve been practicing my Python screen scraping skills these past few months, and will share some tips in a subsequent post. I’ve been busy contributing data to these projects and coordinating a response on my campus. We’ve created a short list of data archives and alternative sources, which captures many of the sources I’ve mentioned here plus a few others. My library colleagues in the health and medical sciences have created a list of alternatives to government medical databases including PubMed and ClinicalTrials.gov
Having access to a public and robust federal statistical system is a non-partisan issue that we should all be concerned about. Our Constitution justifies (in several sections) that we should have such a system, and we have a large body of federal laws that require it. Like many other public goods, the federal statistical system contributes to providing a solid foundation on which our society and economy rest, and helps drive innovation in business, policy, science, and medicine. It’s up to us to protect and preserve it.
I’ve missed my once-a-month goal for writing posts several times this year. This is partially for good reasons, as I’ve been busy supporting students and faculty with coursework and projects, and have been supervising the excellent work of my own students in the lab. We’ve made great progress, releasing a spatial database for Rhode Island mapping projects, writing new tutorials, inventorying thousands of USGS topo maps, and supporting hundreds of students and faculty with their geospatial and demographic research.
But in order to effectively support the work of others, academic librarians need to have a research agenda of their own; to keep up with evolving technology and scholarship to remain effective, and to sustain your own intellectual interests as a professional. Which brings us to the bad reasons behind my posting inactivity. My professional development has come to a screeching halt since I began my new position three years ago. My employer is adverse to supporting scholarly activities for professional librarians (although they gladly share credit if you do the work on evenings, weekends, and vacation time), and a heavy workload makes it impossible to find time for professional development. There are many reasons behind this for which I can’t go into detail – I’ll generally say that bad management and an over-sized library managerial caste are the primary culprits.
Unfortunately this is all too common in academic librarianship. Some high-profile articles have discussed this recently, surveys show that morale is low, and there’s a small but budding branch of scholarship that focuses on library dysfunction. It’s a shame, because both traditional “core-research” librarians and data services-oriented librarians play vital roles within higher ed, and there is no shortage of students and professors who remind me of this on a regular basis. In my opinion, while many students and professors understand and value the work of librarians, many library administrators do not. They dismiss traditional subject librarians as legacy service providers, and they completely do not understand the work of data librarians.
I’ve heard several depressing stories from colleagues at other schools who have been undermined, shuffled around, and in some cases put out of business by incompetent leadership within their library. Within GIS and data librarianship I know several folks who have given up, leaving higher ed for the private sector or independent consulting.
Towards the end of the semester, as I was finishing an hour-long GIS consultation with a grateful undergrad, he asked me what research projects I was currently working on, and what kind of research I do. I was embarrassed to admit that I haven’t been working on anything of my own. After having written a book and publishing several well-received reports, I’m doing nothing more than the intellectual equivalent of shoveling snow. I can’t help but think that I’ve taken a wrong turn, and as the new year begins it’s time to consider the options: focus more sharply on the positive aspects of my position while minimizing the negatives? And somehow, carve out time to do work that I’m interested in? Or, consider moving on, being mindful to avoid exchanging one set of bad circumstances with another? For the latter, this may mean leaving academic librarianship behind.
I am most fortunate in that I don’t have to return to work until the second week of January, and it’s good to have this time to recuperate and reflect. Best wishes to you in the coming new year – Frank
Right before the semester began, I updated the Rhode Island maps on my census research guide so that they link to the recently released Demographic Profile tables from the 2020 Census. I feel like the release of the 2020 census has flown lower on the radar compared to 2010 – it hasn’t made it into the news or social media feeds to the same degree. It has been released much later than usual for a variety of reasons, including the COVID pandemic and political upheaval and shenanigans. At this point in Sept 2023, most of what we can expect has been released, and is available via data.census.gov and the census APIs.
Here are the different series, and what they include.
Redistricting data. Released in Aug 2021. Also known as PL 91-171 (for the law that requires it), this data is intended for redrawing congressional and legislative districts. It includes just six tables, available for several geographies down to the block level. This was our first detailed glimpse of the count. The dataset contains population counts by race, Hispanic and Latino ethnicity, the 18 and over population, group quarters, and housing unit occupancy. Here are the six US-level tables.
Demographic and Housing Characteristics File. Released in May 2023. In the past, this series was called Summary File 1. It is the “primary” decennial census dataset that most people will use, and contains the full range of summary data tables for the 2020 census for practically all census geographies. There are fewer tables overall relative to the 2010 census, and fewer that provide a geographically granular level of detail (ostensibly due to privacy and cost concerns). The Data Table Guide is an Excel spreadsheet that lists every table and the variables they include.
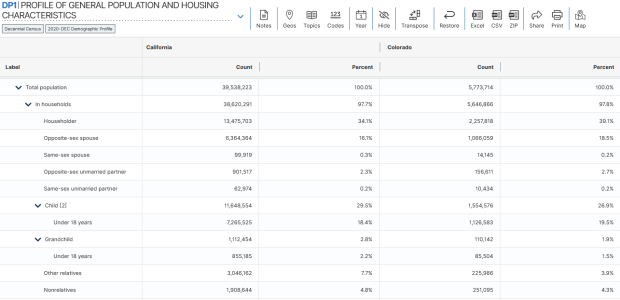
Demographic Profile. Released in May 2023. This is a single table, DP1, that provides a broad cross-section of the variables included in the 2020 census. If you want a summary overview, this is the table you’ll consult. It’s an easily accessible option for folks who don’t want or need to compile data from several tables in the DHC. Here is the state-level table for all 50 states plus.
Detailed Demographic and Housing Characteristics File A. Released in Sept 2023. In the past, this series was called Summary File 2. It is a subset of the data collected in the DHC that includes more detailed cross-tabulations for race and ethnicity categories, down to the census tract level. It is primarily used by researchers who are specifically studying race, and the multiracial population.
Detailed Demographic and Housing Characteristics File B. Not released yet. This will be a subset of the data collected in the DHC that includes more detailed cross-tabulations on household relationships and tenure, down to the census tract level. Primarily of interest to researchers studying these characteristics.
There are a few aspects of the 2020 census data that vary from the past – I’ll link to some NPR stories that provide a good overview. Respondents were able to identify their race or ethnicity at a more granular level. In addition to checking the standard OMB race category boxes, respondents could write in additional details, which the Census Bureau standardized against a list of races, ethnicities, and national origins. This is particularly noteworthy for the Black and White populations, for whom this had not been an option in the recent past. It’s now easier to identify subgroups within these groups, such as Africans and Afro-Caribbeans within the Black population, and Middle Eastern and North Africans (MENA) within the White population. Another major change is that same-sex marriages and partnerships are now explicitly tabulated. In the past, same-sex marriages were all counted as unmarried partners, and instead of having clearly identifiable variables for same-sex partners, researchers had to impute this population from other variables.
Another major change was the implementation of the differential privacy mechanism, which is a complex statistical process to inject noise into the summary data to prevent someone from reverse engineering it to reveal information about individual people (in violation of laws to protect census respondent’s privacy). The social science community has been critical of the application of this procedure, and IPUMS has published research to study possible impacts. One big takeaway is that published block-level population data is less reliable than in the past (housing unit data on the other hand is not impacted, as it is not subjected to the mechanism).
When would you use decennial census data versus other census data? A few considerations – when you:
Want or need to work with actual counts rather than estimates
Only need basic demographic and housing characteristics
Need data that provides detailed cross-tabulations of race, which is not available elsewhere
Need a detailed breakdown of the group quarters population, which is not available elsewhere
Are explicitly working with voting and redistricting
Are making historical comparisons relative to previous 10-year censuses
In contrast, if you’re looking for detailed socio-economic characteristics of the population, you would need to look elsewhere as the decennial census does not collect this information. The annual American Community Survey or monthly Current Population Survey would be likely alternatives. If you need basic, annual population estimates or are studying the components of population change, the Population and Housing Unit Estimates Program is your best bet.






You must be logged in to post a comment.