Python Geocoding Take 1 – International Addresses I discussed my recent adventures with geocoding addresses outside the US. In contrast, there are countless options for batch geocoding addresses within the United States. I’ll discuss a few of those options here, but will focus primarily on the US Census Geocoder and a Python script I’ve written to batch match addresses using their API. The code and documentation is available on my lab’s resources page.
A Few Different Options
ESRI’s geocoding services allow you (with an account) to access their geocoding servers through tools in the ArcToolbox, or you can write a script and access them through an API. QGIS has a third-party plugin for accessing Google’s services (2500 records a day free) or the Open Streetmap. You can still do things the old fashioned way, by downloading geocoded street files and creating a matching service.
Alternatively, you can subscribe to any number of commercial or academic services where you can upload a file, do the matching, and download results. For years I’ve used the geocoding services at Texas A&M that allow you to do just that. Their rates are reasonable, or if you’re an academic institution and partner with them (place some links to their service on their website) you can request free credits for doing matches in batches.
The Census Geocoder and API, and a Python Script for Batch Geocoding
The Census Bureau’s TIGER and address files are often used as the foundational layers for building these other services, to which the service providers add refinements and improvements. You can access the Census Bureau’s services directly through the Census Geocoder, where you can match an address one at a time, or you can upload a batch of 1000 records. It returns longitude and latitude coordinates in NAD 83, and you can get names and codes for all the census geographies where the address is located. The service is pretty picky about the structure of the upload file (must be plain text, csv, with an id column and then columns with the address components in a specific order – with no other attributes allowed) but the nice thing is it requires no login and no key. It’s also public domain, so you can do whatever you want with the data you’ve retrieved. A tutorial for using it is available on our lab’s census tutorials page.

They also have an API with some basic documentation. You can match parsed and unparsed addresses, and can even do reverse geocoding. So I took a stab at writing a script to batch process addresses in text-delimited files (csv or txt). Unfortnately, the Census Geocoding API is not one of the services covered by the Python Geocoder that I mentioned in my previous post, but I did find another third party module called censusgeocode which provides a thin wrapper you can use. I incorporated that module into my Python 3 script, which I wrote as a function that takes the following inputs:
census_geocode(datafile,delim,header,start,addcol)
(str,str,str,int,list[int]) -> files
- datafile – this is the name of the file you want to process (file name and extension). If you place the geocode_census_funct.py file in the same directory as your data file, then you just need to provide the name of the file. Otherwise, you need to provide the full path to the file.
- delim – this is the delimiter or character that separates the values in your data file. Common delimiters includes commas ‘,’, tabs ‘t’, and pipes ‘|’.
- header – here you specify whether your file has a header row, i.e. column names. Enter ‘y’ or ‘yes’ if it does, ‘n’ or ‘no’ if it doesn’t.
- start – type 0 to specify that you want to start reading the file from the beginning. If you were previously running the script and it broke and exited for some reason, it provides an index number where it stopped reading; if that’s the case you can provide that index number here, to pick up where you left off.
- addcol – provide a list that indicates the position number of the columns that contain the address components in your data file. For an unparsed address, you provide just one position number. For a parsed address, you provide 4 positions: address, city, state, and ZIP code. Whether you provide 1 or 4, the numbers must be supplied in brackets, as the function requires a Python list.
You can open the script in IDLE, run it to load it into memory, and then type the function with the necessary parameters in the shell to execute it. Some examples:
- A tab-delimited, unparsed address file with a header that’s stored in the same folder as the script. Start from the beginning and the address is in the 2nd column:
census_geocode('my_addresses.txt','t','y',0,[2]) - A comma-delimited, parsed address file with no header that’s stored in the same folder as the script. Start from the beginning and the addresses are in the 2nd through 5th columns:
census_geocode('addresses_to_match.csv',',','n',0,[2,3,4,5]) - A comma-delimited, unparsed address file with a header that’s not in the same folder as the script. We ran the file before and it stopped at index 250, so restart there – the address is in the 3rd column:
census_geocode('C:address_datadata1.csv',',','y',250,[3])
The beginning of the script “sets the table”: we read the address columns into variables, create the output files (one for matches, one for non-matches, and a summary report), and we handle whether or not there’s a header row. For reading the file I used Python’s CSV module. Typically I don’t use this module, as I find it’s much simpler to do the basic: read a line in, split it on a delimiter, strip whitespace, read it into a list, etc. But in this case the CSV module allows you to handle a wider array of input files; if the input data was a csv and there happened to be commas embedded in the values themselves, the CSV module easily takes care of it; if you ignore it, the parsing would get thrown off for that record.
Handling Exceptions and Server Errors
In terms of expanding my skills, the new things I had to learn were exception handling and control flows. Since the censusgeocoding module is a thin wrapper, it had no built in mechanism for retrying a match a certain number of times if the server timed out. This is an absolute necessity, because the census server often times out, is busy, or just hiccups, returning a generic error message. I had already learned how to handle crashes in my earlier geocoding experiments, where I would write the script to match and write a record one by one as it went along. It would try to do a match, but if any error was raised, it would exit that loop cleanly, write a report, and all would be saved and you could pick up where you left off. But in this case, if that server non-response error was returned I didn’t want to give up – I wanted to keep trying.
So on the outside there is a loop to try and do a match, unless any error happens, then exit the loop cleanly and wrap up. But inside there is another try loop, where we try to do a match but if we get that specific server error, continue: go back to the top of that for loop and try again. That loop begins with While True – if we successfully get to the end, then we start with the next record. If we get that server error we stay in that While loop and keep trying until we get a match, or we run out of tries (5) and write as a non-match.

In doing an actual match, the script does a parsed or unparsed match based on user input. But there was another sticking point; in some instances the API would return a matched result (we got coordinates!), but some of the objects that it returned were actually errors because of some java problem (failed to get the tract number or county name – here’s an error message instead!) To handle this, we have a for i in range loop. If we have a matched record and we don’t have a status message (that indicates an error) then we move along and grab all the info we need – the coordinates, and all the census geography where that coordinate falls, and write it out, and then that for loop ends with a break. But if we receive an error message we continue – go back to the top of that loop and try doing the match again. After 3 tries we give up and write no match.
Figuring all that out took a while – where do these loops go and what goes in them, how do I make sure that I retry a record rather than passing over it to the next one, etc. Stack Exchange to the rescue! Difference between continue, pass and break, returning to the beginning of a loop, breaking out of a nested loop, and retrying after an exception. The rest is pretty straightforward. Once the matching is done we close the files, and write out a little report that tells us how many matches we got versus fails. The Census Geocoder via the API is pretty unforgiving; it either finds a match, or it doesn’t. There is no match score or partial matching, and it doesn’t give you a ZIP Code or municipal centroid if it can’t find the address. It’s all or nothing; if you have partial or messy addresses or PO Boxes, it’s pretty much guaranteed that you won’t get matches.
There’s no limit on number of matches, but I’ve built in a number of pauses so I’m not hammering the server too hard – one second after each match, 5 seconds after every 1000 matches, a couple seconds before retrying after an error. Your mileage will vary, but the other day I did about 2500 matches in just under 2 hours. Their server can be balky at times – in some cases I’ve encountered only a couple problems for every 100 records, but on other occasions there were hang-ups on every other record. For diagnostic purposes the script prints every 100th record to the screen, as well as any problems it encountered (see pic below). If you launch a process and notice the server is hanging on every other record and repeatedly failing to get matches, it’s probably best to bail out and come back later. Recently, I’ve noticed fewer problems during off-peak times: evenings and weekends.
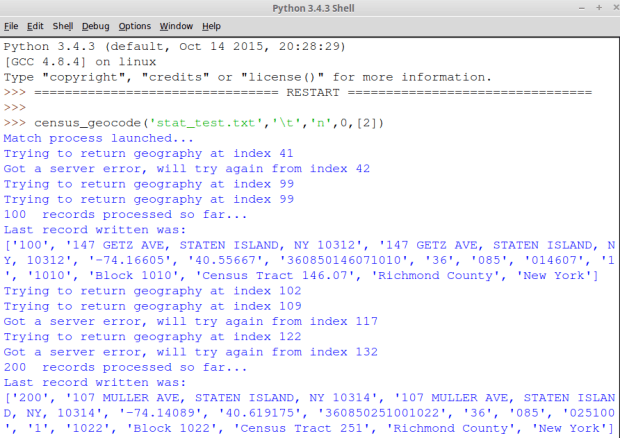
Wrap Up
The script and the documentation are posted on our labs resources page, for all to see and use – you just have to install the third party censusgeocode module before using it. When would you want to use this? Well, if you need something that’s free, this is a good choice. If you have batches in the 10ks to do, this would be a good solution. If you’re in the 100ks, it could be a feasible solution – one of my colleagues has confirmed that he’s used the script to match about 40k addresses, so the service is up to the task for doing larger jobs.
If you have less than a couple thousand records, you might as well use their website and upload files directly. If you’re pushing a million or more – well, you’ll probably want to set up something locally. PostGIS has a TIGER module that lets you do desktop matching if you need to go into the millions, or you simply have a lot to do on a consistent basis. The excellent book PostGIS in Action has a chapter dedicated to to this.
In some cases, large cities or counties may offer their own geocoding services, and if you know you’re just going to be doing matches for your local area those sources will probably have greater accuracy, if they’re adding value with local knowledge. For example, my results with NYC’s geocoding API for addresses in the five boroughs are better than the Census Bureau’s and is customized for local quirks; for example, I can pass in a borough name instead of a postal city and ZIP Code, and it’s able to handle those funky addresses in Queens that have dashes and similar names for multiple streets (35th st, 35th ave, 35th dr…). But for a free, public domain service that requires no registration, no keys, covers the entire country, and is the foundation for just about every US geocoding platform out there, the Census Geocoder is hard to beat.
